答主最近学到TRPO,这算法确实很难理解,现在记录答主现在的一点想法,留存记录。先放参考文献,方便大家学习。
Reference:
[1]: Sutton R S, Barto A G. Reinforcement learning: An introduction[M]. MIT press, 2018.
[2]: 张伟楠、沈键、俞勇. 《动手学强化学习》, 2022.
[3]: Schulman J, Levine S, Abbeel P, et al. Trust region policy optimization[C]//International conference on machine learning. PMLR, 2015: 1889-1897.
本文将以《动手学强化学习》这本书为主导,对TRPO算法进行数学推导,代码分析。源代码在这个链接。
1:算法目标
我在学习TRPO的过程中,经常会学着学着就很茫然,其实后面发现是对算法的目标不清楚,牢记A-C架构的目标,会对理解TRPO很有帮助。TRPO的目标可以用两个方程表示:
更新价值参数 :  (1)
(1)
更新策略参数 :  (2)
(2)
公式(1),(2)是Actor-Critic的本质,TRPO算法的目标也是基于此,最后要实现的也是基于这两个方程的更新。
Problem 1: 为什么TRPO会出来? TRPO要解决什么问题? TRPO通过什么方法解决问题?如何判 定新算法的优劣?
* (1)单纯的A-C网络在策略网络是深度模型时,沿着策略梯度更新参数,很有可能会因为步长 太长导致策略显著变差,进而影响训练效果[2] 。TRPO就是要解决这个问题。
(2)TRPO算法通过置信域来控制步长,从而解决上述问题。通过引入每一幕的回报总望, 来判断新策略的优劣。
2:数学工具
先总结TRPO用到的数学方法: 共轭梯度(conjugate gradient method),线性搜索(line search), 广义优势估计(generalized advantage estimation),KKT条件,KL散度。
2.1:每个数学方法的作用
KL散度: 通过KL散度计算目前的策略和更新后的策略之间的距离,通过这个距离来限制更新的范 围(这个距离在策略空间是一个球,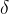 是这个球的最大边界半径,这个球就是信任域)
是这个球的最大边界半径,这个球就是信任域)
KKT条件:利用KKT条件解出约束条件的解
线性搜索: 由于 TRPO 算法用到了泰勒展开的 1阶和 2 阶近似,这并非精准求解,所以在
每次选代的最后进行一次线性搜索。
共轭梯度:一般来说,用神经网络表示的策略函数的参数数量都是成千上万的, 而TRPO算法用 到了海瑟矩阵(Hessian matrix),要计算这么大的矩阵的逆矩阵是不太现实的,所以利用共轭梯度来计算要算的梯度。
广义优势估计: 利用广义优势估计来计算优势函数
3:算法步骤
TRPO的伪代码如下[2] :

Solve: 我们现在从终点往前推,先找到终点,再来解决走向终点过程中遇到的困难。
1:终点是利用 公式(1),(2)实现目标更新。(1)的价值函数更新是比较容易的,只需要用 网络输出和时序差分的 Td_target做loss,再反向传播就能更新参数。
2:利用公式(2)更新的时候需要设置好步长,实现参数的更新。
3:怎么设置好步长?利用信任域算法,利用KL散度来计算两个策略之间的距离,是否符合约束 条件(即是否在信任域这个球里面),保证每次更新的幅度在信任域范围内(虽然每次更新幅 度小,但能保证每次更新都是梯度上升)。
4:约束条件可以用KKT条件直接求解,得到带有高阶海瑟矩阵逆矩阵的参数更新的等式。
5:在更新参数的时候,需要计算带有海瑟矩阵的逆矩阵的约束问题,所以引入共轭梯度来解决 海瑟矩阵的逆矩阵难求这个问题。
7:在更新参数的时候,所用到的约束条件都是目标约束条件的1阶,2阶泰勒展开,这种近似展 开并不能保证更新的参数一定满足原本的约束条件,所以引入线性搜索来得到更优的参数。
4:数学推导
来到了本章最无聊最复杂的一部分了,答主尽量会用最简单的推导讲清楚TRPO的数学原理。
4.1 策略目标
策略梯度方法的的一般性过程为:参数化智能体的策略,并设计好衡量策略好坏的目标函数,通过梯度上升的方法来最大化这个目标函数,使得策略最优。具体来说,假设 θ 表示策略 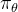 的参数,
的参数, 是状态价值函数,J(θ) 是目标函数,定义:
是状态价值函数,J(θ) 是目标函数,定义:
![J(\theta) = E_{s_{0}}[V^{\pi_{0}} (s_{0})]](https://latex.csdn.net/eq?J%28%5Ctheta%29%20%3D%20E_%7Bs_%7B0%7D%7D%5BV%5E%7B%5Cpi_%7B0%7D%7D%20%28s_%7B0%7D%29%5D)
![= E_{\pi_{\theta}}[\sum_{t=0}^{\infty} \gamma^{t} r(s_{t}, a_{t})]](https://latex.csdn.net/eq?%3D%20E_%7B%5Cpi_%7B%5Ctheta%7D%7D%5B%5Csum_%7Bt%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bt%7D%20r%28s_%7Bt%7D%2C%20a_%7Bt%7D%29%5D)
基 于 策 略 的 方 法 的 目 标 是 找 到  , 策略梯度算法主要沿着 ∇J(θ) 方向迭代更新策略参数 θ。现在,我们要考虑怎么借助当前的
, 策略梯度算法主要沿着 ∇J(θ) 方向迭代更新策略参数 θ。现在,我们要考虑怎么借助当前的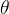 找到一个更好的参数
找到一个更好的参数 (这就是神经网络的一般化流程)。
(这就是神经网络的一般化流程)。
假设当前的目标策略为 πθ ,参数为 θ。我们考虑如何借助当前的 θ 找到一个更好的参数 θ′, 使得
J(θ′) ≥ J(θ)。状态价值函数和动作价值函数定义如下:
![Q_{\pi}(s_{t}, a_{t}) = E_{s_{t+1}, a_{t+1}, ....} \big[\sum_{l=0}^{\infty} \gamma^{l} r(s_{t+l})]](https://latex.csdn.net/eq?Q_%7B%5Cpi%7D%28s_%7Bt%7D%2C%20a_%7Bt%7D%29%20%3D%20E_%7Bs_%7Bt+1%7D%2C%20a_%7Bt+1%7D%2C%20....%7D%20%5Cbig%5B%5Csum_%7Bl%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bl%7D%20r%28s_%7Bt+l%7D%29%5D)
![V_{\pi}(s_{t}) = E_{a_{t}, s_{t+1}, ....} \big[\sum_{l=0}^{\infty} \gamma^{l} r(s_{t+l})]](https://latex.csdn.net/eq?V_%7B%5Cpi%7D%28s_%7Bt%7D%29%20%3D%20E_%7Ba_%7Bt%7D%2C%20s_%7Bt+1%7D%2C%20....%7D%20%5Cbig%5B%5Csum_%7Bl%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bl%7D%20r%28s_%7Bt+l%7D%29%5D)
优势函数定义如下:

看了很多博客,很少有对这个优势函数做推理解释的, 这里简单的解释推导一下优势函数, 也可以看这篇文章 优势函数:
![= E_{s_{t+1}, a_{t+1}, ....} \big[\sum_{l=0}^{\infty} \gamma^{l} r(s_{t+l})] - E_{a_{t}, s_{t+1}, ....} \big[\sum_{l=0}^{\infty} \gamma^{l} r(s_{t+l})]](https://latex.csdn.net/eq?%3D%20E_%7Bs_%7Bt+1%7D%2C%20a_%7Bt+1%7D%2C%20....%7D%20%5Cbig%5B%5Csum_%7Bl%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bl%7D%20r%28s_%7Bt+l%7D%29%5D%20-%20E_%7Ba_%7Bt%7D%2C%20s_%7Bt+1%7D%2C%20....%7D%20%5Cbig%5B%5Csum_%7Bl%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bl%7D%20r%28s_%7Bt+l%7D%29%5D)
![=E_{\pi_{\theta^{'}}} \big[\sum_{t=0}^{\infty} \gamma^{t} [r(s_{t}, a_{t}) + \gamma V^{\pi_{\theta}}(s_{t+1}) - V^{\pi_{\theta}} (s_{t})] \big]](https://latex.csdn.net/eq?%3DE_%7B%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%7D%20%5Cbig%5B%5Csum_%7Bt%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bt%7D%20%5Br%28s_%7Bt%7D%2C%20a_%7Bt%7D%29%20+%20%5Cgamma%20V%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%28s_%7Bt+1%7D%29%20-%20V%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%20%28s_%7Bt%7D%29%5D%20%5Cbig%5D)
关于 和
和 的计算,可以看我这篇文章ICLR选手-马尔科夫决策过程,公式形式有点问题,懒得改了。
的计算,可以看我这篇文章ICLR选手-马尔科夫决策过程,公式形式有点问题,懒得改了。

如上图, 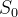 的状态价值函数为:
的状态价值函数为:

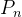 是状态转移概率, 且
是状态转移概率, 且 。设
。设  , 所以可以得到:
, 所以可以得到:

 ,
,  , 所以
, 所以  。即如果每次Agent每次做出的动作选择都是最优的,那么得到的优势函数一定是非负的,如果优势函数为负,说明当前状态做出的选择并不好。
。即如果每次Agent每次做出的动作选择都是最优的,那么得到的优势函数一定是非负的,如果优势函数为负,说明当前状态做出的选择并不好。
可以得到:
![J(\theta^{'}) - J(\theta) = E_{s_{0}} [V^{\pi_{\theta^{'}}} (s_{0})] - E_{s_{0}} [V^{\pi_{\theta}} (s_{0})]](https://latex.csdn.net/eq?J%28%5Ctheta%5E%7B%27%7D%29%20-%20J%28%5Ctheta%29%20%3D%20E_%7Bs_%7B0%7D%7D%20%5BV%5E%7B%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%7D%20%28s_%7B0%7D%29%5D%20-%20E_%7Bs_%7B0%7D%7D%20%5BV%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%20%28s_%7B0%7D%29%5D)
![= E_{\pi_{\theta^{'}}} \big[ \sum_{t=0}^{\infty} \gamma^{t} [r(s_{t}, a_{t}) + \gamma V^{\pi_{\theta}} (s_{t+1}) - V^{\pi_{\theta}} (s_{t})] \big]](https://latex.csdn.net/eq?%3D%20E_%7B%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%7D%20%5Cbig%5B%20%5Csum_%7Bt%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bt%7D%20%5Br%28s_%7Bt%7D%2C%20a_%7Bt%7D%29%20+%20%5Cgamma%20V%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%20%28s_%7Bt+1%7D%29%20-%20V%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%20%28s_%7Bt%7D%29%5D%20%5Cbig%5D)
即:
![J(\theta^{'}) = J(\theta) + E_{\pi_{\theta^{'}}} \big[\sum_{t=0}^{\infty} \gamma^{t} A_{\pi}(s_{t}, a_{t})]](https://latex.csdn.net/eq?J%28%5Ctheta%5E%7B%27%7D%29%20%3D%20J%28%5Ctheta%29%20+%20E_%7B%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%7D%20%5Cbig%5B%5Csum_%7Bt%3D0%7D%5E%7B%5Cinfty%7D%20%5Cgamma%5E%7Bt%7D%20A_%7B%5Cpi%7D%28s_%7Bt%7D%2C%20a_%7Bt%7D%29%5D)

所以如果能够找到一个新的策略,使得 ,那么就能够保证策略的性能不减。但是出现了一个问题: 策略更新和收集样本用的都是新策略,这是很不现实的,所以TRPO做了一步近似,用
,那么就能够保证策略的性能不减。但是出现了一个问题: 策略更新和收集样本用的都是新策略,这是很不现实的,所以TRPO做了一步近似,用 来代替
来代替 (
(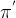 ) 来收集样本,当趋近于时,可以忽略两个策略之间的差距。所以:
) 来收集样本,当趋近于时,可以忽略两个策略之间的差距。所以:

对动作采用重要性采样处理:
![\sum_{a} \pi_{\theta}(a|s) A_{\pi}(s, a) = E_{a \sim q} \big[\frac{\pi^{'}(a|s)}{\pi(a|s)} A_{\pi}(s,a) \big]](https://latex.csdn.net/eq?%5Csum_%7Ba%7D%20%5Cpi_%7B%5Ctheta%7D%28a%7Cs%29%20A_%7B%5Cpi%7D%28s%2C%20a%29%20%3D%20E_%7Ba%20%5Csim%20q%7D%20%5Cbig%5B%5Cfrac%7B%5Cpi%5E%7B%27%7D%28a%7Cs%29%7D%7B%5Cpi%28a%7Cs%29%7D%20A_%7B%5Cpi%7D%28s%2Ca%29%20%5Cbig%5D)
回顾原式,和替代式,我们可以看到两个式子之间唯一的区别就是状态分布的不同,将替代函数 Lθ (θ′) 和原函数 J(θ′) 看做 θ′的函数,则替代函数 Lθ (θ′) 和原函数 J(θ′) 在 θ 处一阶近似,如图:

根据不等式:  ,
, ,
,  是两个分布之间的散度。可以得到替代函数的下界。设这个下界为:
是两个分布之间的散度。可以得到替代函数的下界。设这个下界为:

下面利用这个下界,我们证明策略的单调性: , 且
, 且 , 则
, 则 。这个使得这个不等式成立的
。这个使得这个不等式成立的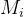 就是我们寻找的策略。这问题可以转换为:
就是我们寻找的策略。这问题可以转换为:![max [L_{\theta}(\theta) - C \cdot D_{KL}^{max} (\theta, \theta^{'})]](https://latex.csdn.net/eq?max%20%5BL_%7B%5Ctheta%7D%28%5Ctheta%29%20-%20C%20%5Ccdot%20D_%7BKL%7D%5E%7Bmax%7D%20%28%5Ctheta%2C%20%5Ctheta%5E%7B%27%7D%29%5D) 。再加上 KL 散度的约束条件,则策略的目标约束为:
。再加上 KL 散度的约束条件,则策略的目标约束为:
![max_{\theta^{'}} E_{s \sim v^{\pi \theta^{'}}} E_{a \sim \pi_{\theta^{'}} (\cdot | s)} [A^{\pi_{\theta}} (s, a)]](https://latex.csdn.net/eq?max_%7B%5Ctheta%5E%7B%27%7D%7D%20E_%7Bs%20%5Csim%20v%5E%7B%5Cpi%20%5Ctheta%5E%7B%27%7D%7D%7D%20E_%7Ba%20%5Csim%20%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%20%28%5Ccdot%20%7C%20s%29%7D%20%5BA%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%20%28s%2C%20a%29%5D)

需要注意的是,因为有无穷个状态,因此约束条件 有无穷个,问题不可解,所以为了解决这个问题,引入平均KL散度代替最大KL散度。
有无穷个,问题不可解,所以为了解决这个问题,引入平均KL散度代替最大KL散度。
4.2 信任域
这里的不等式约束定义了策略空间的一个库尔贝克-莱布勒(kl)球,称之为信任区域。在这个区域中,可以认为当前的学习策略和环境交互的状态分布与上一轮策略最后采样的状态分布一致,进而可以基于一部动作的重要性采样方法是当前的学习策略稳定提升。
信任域的算法如下:



通过上面的图可以得到信任域的大致流程:通过在某点的近似展开,得到近似函数,在这个球的范围内,计算近似函数的最大值,通过这个最大值对应的,计算原函数点对应的值。然后再把这个点作为新的迭代点,直到最后收敛。
4.3 近似求解
直接求约束的优化问题比较麻烦,TRPO在其具体实现中做到一步近似操作来快速求解。可以对目标函数和约束在附近做泰勒展开,分别用1阶,2阶进行近似:


其中,![\textbf{g} = \bigtriangledown_{\theta^{'}} E_{s \sim v^{\pi \theta^{'}}} E_{a \sim \pi_{\theta^{'}} (\cdot | s)} \big[\frac{\pi_{\theta^{'}} (a | s)}{\pi_{\theta} (a | s)} A^{\pi_{\theta}} (s, a) \big]](https://latex.csdn.net/eq?%5Ctextbf%7Bg%7D%20%3D%20%5Cbigtriangledown_%7B%5Ctheta%5E%7B%27%7D%7D%20E_%7Bs%20%5Csim%20v%5E%7B%5Cpi%20%5Ctheta%5E%7B%27%7D%7D%7D%20E_%7Ba%20%5Csim%20%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%20%28%5Ccdot%20%7C%20s%29%7D%20%5Cbig%5B%5Cfrac%7B%5Cpi_%7B%5Ctheta%5E%7B%27%7D%7D%20%28a%20%7C%20s%29%7D%7B%5Cpi_%7B%5Ctheta%7D%20%28a%20%7C%20s%29%7D%20A%5E%7B%5Cpi_%7B%5Ctheta%7D%7D%20%28s%2C%20a%29%20%5Cbig%5D) 表示目标函数的梯度,
表示目标函数的梯度,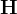 表示策略之间的平均KL距离的海瑟矩阵(Hessian matrix)。于是优化目标变成了:
表示策略之间的平均KL距离的海瑟矩阵(Hessian matrix)。于是优化目标变成了:


此时,我们可以使用卡罗需-库恩-塔克(KKT)条件直接解出上述问题的解:

4.4 共轭梯度
一般来说,用神经网络表示的策略函数的参数数量都是成千上万的,计算和存储海瑟矩阵 的逆矩阵会耗费大量的内存资源和时间。TRPO通过共梯度法 (conjugate gradient method) 回避了这个问题,它的核心思想是直接计算  ,x 即参数更新方向。通过矩阵的变换,可以用x替换下面的等式:
,x 即参数更新方向。通过矩阵的变换,可以用x替换下面的等式:




因为是正定矩阵, 所以 ,所以:
,所以:

共轭梯度的伪代码如下:

为了避免这种大矩阵的出现,我们只计算Hx 向量,而不直接计算和存储 H 矩阵。这样做比
较容易,因为对任意的列向量 v,容易验证


共轭梯度的图解如图:

4.5 线性搜索
由于 TRPO 算法用到了泰勒展开的 1阶和 2 阶近似,这并非精准求解,因此,θ′可能未必比 θ 好,或未必能满足 KL 散度限制。TRPO 在每次选代的最后进行一次线性搜索 (line search). 以
确保找到满足条件 [5]。具体来说,就是找到一个最小的非负整数 i,使得按照:

其中 α ∈ (0, 1), 是一个决定线性搜索长度的超参数。线性搜索示例图如下:

写到这懒得写了:
4.6 KL散度
这个链接
4.7 KKT条件
KKT条件
4.8 广义优势估计


5: 代码讲解
计算优势函数:
import torch
import numpy as np
import gym
import matplotlib.pyplot as plt
import torch.nn.functional as F
import rl_utils
import copy
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
定义价值网络和策略网络:
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class TRPO:
""" TRPO算法 """
def __init__(self, hidden_dim, state_space, action_space, lmbda,
kl_constraint, alpha, critic_lr, gamma, device):
state_dim = state_space.shape[0]
action_dim = action_space.n
# 策略网络参数不需要优化器更新
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr)
self.gamma = gamma
self.lmbda = lmbda # GAE参数
self.kl_constraint = kl_constraint # KL距离最大限制
self.alpha = alpha # 线性搜索参数
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def hessian_matrix_vector_product(self, states, old_action_dists, vector):
# 计算黑塞矩阵和一个向量的乘积
new_action_dists = torch.distributions.Categorical(self.actor(states))
kl = torch.mean(
torch.distributions.kl.kl_divergence(old_action_dists,
new_action_dists)) # 计算平均KL距离
kl_grad = torch.autograd.grad(kl,
self.actor.parameters(),
create_graph=True)
kl_grad_vector = torch.cat([grad.view(-1) for grad in kl_grad])
# KL距离的梯度先和向量进行点积运算
kl_grad_vector_product = torch.dot(kl_grad_vector, vector)
grad2 = torch.autograd.grad(kl_grad_vector_product,
self.actor.parameters())
grad2_vector = torch.cat([grad.view(-1) for grad in grad2])
return grad2_vector
def conjugate_gradient(self, grad, states, old_action_dists): # 共轭梯度法求解方程
x = torch.zeros_like(grad)
r = grad.clone()
p = grad.clone()
rdotr = torch.dot(r, r)
for i in range(10): # 共轭梯度主循环
Hp = self.hessian_matrix_vector_product(states, old_action_dists,
p)
alpha = rdotr / torch.dot(p, Hp)
x += alpha * p
r -= alpha * Hp
new_rdotr = torch.dot(r, r)
if new_rdotr < 1e-10:
break
beta = new_rdotr / rdotr
p = r + beta * p
rdotr = new_rdotr
return x
def compute_surrogate_obj(self, states, actions, advantage, old_log_probs,
actor): # 计算策略目标
log_probs = torch.log(actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs)
return torch.mean(ratio * advantage)
def line_search(self, states, actions, advantage, old_log_probs,
old_action_dists, max_vec): # 线性搜索
old_para = torch.nn.utils.convert_parameters.parameters_to_vector(
self.actor.parameters())
old_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, self.actor)
for i in range(15): # 线性搜索主循环
coef = self.alpha**i
new_para = old_para + coef * max_vec
new_actor = copy.deepcopy(self.actor)
torch.nn.utils.convert_parameters.vector_to_parameters(
new_para, new_actor.parameters())
new_action_dists = torch.distributions.Categorical(
new_actor(states))
kl_div = torch.mean(
torch.distributions.kl.kl_divergence(old_action_dists,
new_action_dists))
new_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, new_actor)
if new_obj > old_obj and kl_div < self.kl_constraint:
return new_para
return old_para
def policy_learn(self, states, actions, old_action_dists, old_log_probs,
advantage): # 更新策略函数
surrogate_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, self.actor)
grads = torch.autograd.grad(surrogate_obj, self.actor.parameters())
obj_grad = torch.cat([grad.view(-1) for grad in grads]).detach()
# 用共轭梯度法计算x = H^(-1)g
descent_direction = self.conjugate_gradient(obj_grad, states,
old_action_dists)
Hd = self.hessian_matrix_vector_product(states, old_action_dists,
descent_direction)
max_coef = torch.sqrt(2 * self.kl_constraint /
(torch.dot(descent_direction, Hd) + 1e-8))
new_para = self.line_search(states, actions, advantage, old_log_probs,
old_action_dists,
descent_direction * max_coef) # 线性搜索
torch.nn.utils.convert_parameters.vector_to_parameters(
new_para, self.actor.parameters()) # 用线性搜索后的参数更新策略
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
td_target = rewards + self.gamma * self.critic(next_states) * (1 -
dones)
td_delta = td_target - self.critic(states)
advantage = compute_advantage(self.gamma, self.lmbda,
td_delta.cpu()).to(self.device)
old_log_probs = torch.log(self.actor(states).gather(1,
actions)).detach()
old_action_dists = torch.distributions.Categorical(
self.actor(states).detach())
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step() # 更新价值函数
# 更新策略函数
self.policy_learn(states, actions, old_action_dists, old_log_probs,
advantage)
hessian_matrix_vector_product这个函数式计算:

conjugate_gradient函数计算共轭梯度。
compute_surrogate_obj是计算:

写到这吧,如果大家对这个有啥问题,欢迎在评论区讨论,同时如果对PPO感兴趣,也可以一起探讨。