Kafka
简介
Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
流平台具有三个关键功能:
-
消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
-
容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险·。
-
流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
Kafka 主要有两大应用场景:
-
消息队列 :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
-
数据处理: 构建实时的流数据处理程序来转换或处理数据流。
为什么要用kafka消息队列,他的优势是什么?
- 解耦:读写逻辑分开
- 冗余:避免消息丢失
- 扩展性:解耦之后,增大消息入队和处理消息的频率都很容易
- 灵活性 & 峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用
- 顺序保证
- 缓冲
核心概念
生产者(也称为发布者)创建消息,而消费者(也称为订阅者)负责消费or读取消息。
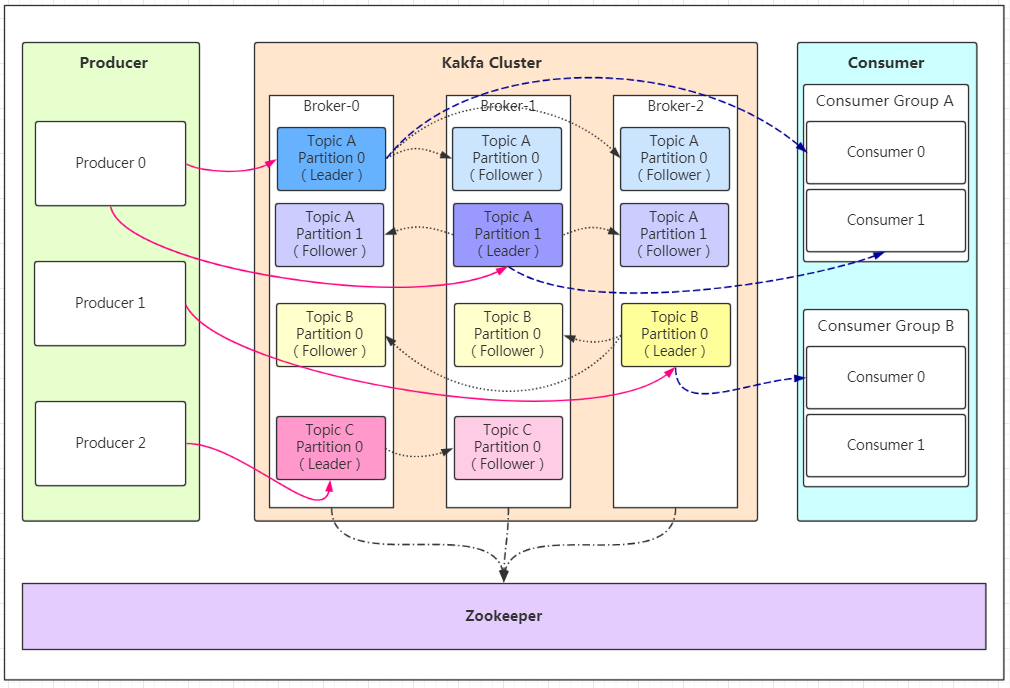
在 Kafka 中,消息以**主题(Topic)**来分类,每一个主题都对应一个 「消息队列」,这有点儿类似于数据库中的表。但是如果我们把所有同类的消息都塞入到一个“中心”队列中,势必缺少可伸缩性,无论是生产者/消费者数目的增加,还是消息数量的增加,都可能耗尽系统的性能或存储。v
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!(为了方便扩展-消息数量增加和提供并发)
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Kafka 的多分区(Partition)以及多副本(Replica)机制的作用
- Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
- Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
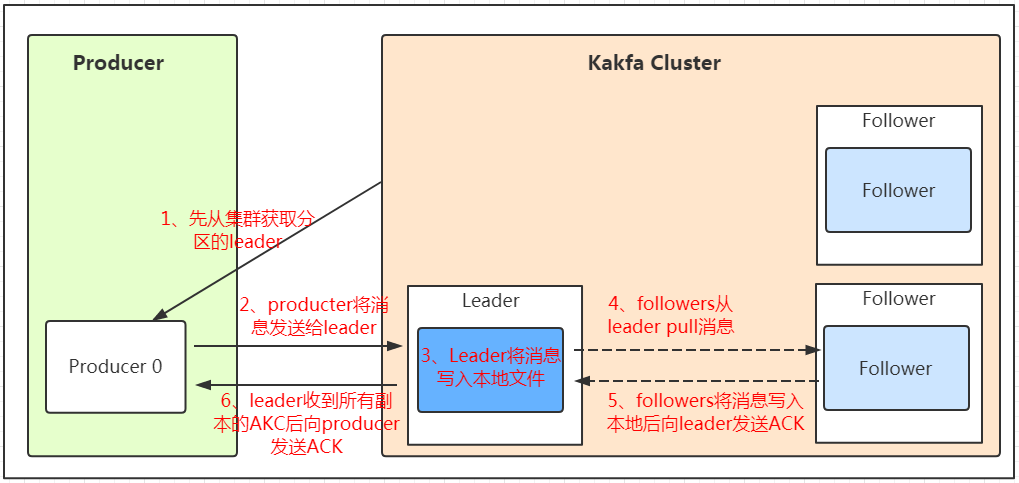
基本原理
发送数据
写入数据的时候寻找leader,followers主动pull从leader中拉取数据
面试常问问题
kafka如何保证有序性

每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。Kafka 只能为我们保证 Partition(分区) 中的消息有序,而不能保证 Topic(主题) 中的 Partition(分区) 的有序。
所以,我们就有一种很简单的保证消息消费顺序的方法:1 个 Topic 只对应一个 Partition。这样当然可以解决问题,但是破坏了 Kafka 的设计初衷。
Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
总结一下,对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
- 1 个 Topic 只对应一个 Partition。
- (推荐)发送消息的时候指定 key/Partition。
kafka如何保证消息不丢失
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后消息消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果
可以采用为其添加回调函数的形式,示例代码如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
另外这里推荐为 Producer 的retries(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了
丢失的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。

当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭闭自动提交 offset,每次在真正消费完消息之后之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
如何解决重复消费的问题
通过保证消息队列消费的幂等性来保证
怎么保证消息队列消费的幂等性(同一条消息消费多次结果相同)?
我们需要结合业务来思考,比如下面的例子:
1.比如某个数据要写库,你先根据主键查一下,如果数据有了,就别插入了,update一下好吧
2.比如你是写redis,那没问题了,反正每次都是set,天然幂等性
我们需要结合业务来思考,比如下面的例子:
1.比如某个数据要写库,你先根据主键查一下,如果数据有了,就别插入了,update一下好吧
2.比如你是写redis,那没问题了,反正每次都是set,天然幂等性
3.对于消息,我们可以建个表(专门存储消息消费记录)