AutoML: A Survey of the State-of-the-Art
自动机器学习:无需人类辅助自动进行机器学习
Abstract
本文根据AutoML的处理流程来对自动机器学习进行介绍,包括:数据准备、特征工程、超参数优化和神经网络架构搜索。
(Data preparation,Feature engineering,Hyperparameter optimization, Neural Architecture Search).
本文还总结了一些代表性的NAS算法在CIFAR-10和ImagNet数据集上的效果;最终对AutoML现存的挑战及未来发展方向进行讨论。
Section I Introduction
深度学习应用在了诸多领域,如图像分类、目标检测、语言模型。神经网络逐渐向着更加复杂的方向发展,但是要注意到这些模型都是研究人员不断试错尝试设计出来的,耗费了大量的时间和资源。
因此AutoML就是自动进行深度学习,减少时间和资源的消耗。
AutoML有诸多定义和解读,总的来说就是在有限的计算资源下自动进行深度学习的过程。

随着计算机算力的指数增长,AutoML可以动态组合各种技术,搭建简易便捷端到端的深度学习模型。
Fig 1展示了AutoML的处理流程,包含以下步骤:
(1)data preparation
(2)feature engineering
(3)model generation
(4)model evaluation
而模型生成可以进一步分为搜索空间和优化方法两部分。
搜索空间定义了模型的搜索范围,有基于传统机器学习和基于神经网络两类;优化方法也分为超参数优化和结构优化两种,前者优化训练相关的参数(如学习率、batchsize),后者优化模型结构相关的参数(如神经网络的层数、KNN中K近邻的取值)。
神经架构搜索(NAS)分为以下三部分,分别是:搜索空间、优化策略、模型评估策略。
Zoph等人的研究是第一个提出神经架构搜索概念的,他们通过强化学习训练神经网络成功获得了与人类设计的模型相近性能的网络结构,随后AutoML领域中如何进行神经架构搜索就引起了各界极大的研究兴趣。
NAS的目标就是在预定义的搜索空间中选择和组合不同的基本操作从而搭建更加健壮和性能良好的神经结构。
基于研究现状,搜索空间主要分为以下几种:整体结构(entire-architecture)、细胞型(cell-based)、层次型(hierarchical )和态射型(morphism-based)。
优化方法可分为:强化学习、进化算法、梯度下降算法、随机搜索和混合模型。
本文主要内容:2-4章按顺序依次介绍 数据准备、特征工程、模型生成和模型优化,第6章介绍NAS不同的算法,主要分为两类:one/two stage 和one-shot类型;第7章对AotoML的一些开放性问题进行探讨,最后总结全文。
Section 2 Data Preparation
进行深度学习的第一步就是要准备数据,包括:数据收集、数据清洗和数据增强。
数据收集:
Data collection是建立数据集或扩充已有数据集不可或缺的一步。
数据清洗:
Data cleaning主要是滤除数据中的噪声不影响后续模型的使用。
数据增强:
Data augmentation对增强模型鲁棒性、提升模型性能至关重要。
Fig 2展示了数据准备的流程。

Part A Data Collection
在早期机器学习的研究中提出了MNIST数据集,随后又发展出了更大的CIFAR-10,CIFAR-100和ImageNet数据集。但是为特定的任务找到合适的数据集往往不是那么容易,有的是因为医学图像难以获取,有的是因为隐私原因。常通过以下两种方式解决数据收集问题:数据搜索和数据合成。
Data Searching
互联网中有无穷的数据但是网络数据的获取和使用还存在一些问题:
(1)搜索结果可能与关键词并不匹配;
(2)有些网络数据可能打标错误甚至未打标;
(3)网络上的数据分布可能与数据集本身的分布大相径庭,也增加了模型训练的难度。
因此为了解决以上问题,可以考虑数据合成的方法。

Data Synthesis
数据模拟器是最常用的数据合成方法之一。
因为你像一些自动驾驶的测试数据就不可能来自真实世界的真实图像,就需要借助数据模拟器生成尽可能逼真的图像。
另一种新型技术就是借助生成对抗网络来生成图像。比如Fig 3就展示了借助GAN生成的一些人脸图像。但对于文本数据使用GAN还有一定难度,因为文本大多是不连续的因此判别器的梯度无法传递到生成器。还有研究使用GAN生成医疗或教育数据。
Part B Data cleaning
因为搜集的数据不可避免会有噪声,但噪声不利于模型的训练,因此需要数据清洗去除噪声。传统的数据清洗需要专家知识,这种方法有自身的局限性并且价格昂贵。随后逐渐出现了自动化数据清洗,比如通过Boosting和特征选择结合的方式获得一系列效果良好的清洗操作,或者转化为超参数优化问题。
以上方法都是在固定的数据集内,再考虑到现实世界每天都会产生海量的数据,如何在这一连续的过程中进行数据清洗才是需要考虑的问题。
Part C Data Augmentation
从某些角度而言 数据增强也可以看做是数据收集的一种方式,但是数据增强主要是作为防止模型出现过拟合的手段。

Fig 4展示了不同类型数据进行数据扩充的方式。
比如对于图像数据,常用的仿射变换有旋转、缩放、随机裁剪、对称等;弹性变换包括对比度、亮度变换和通道调整;一些高阶的变换还包括随机擦除、图像混叠、mixup等。
需要注意的是上述提到的数据增强的方法还是需要根据人为选择,这也需要专家知识且费时费力。也有研究者提出自动数据增强(AutoAugment)但目前效率并不十分令人满意。
Section III Feature Engineering
特征工程
工业上一般任务数据和特征确定了机器学习的上限,算法和模型只能无限逼近这一极限。特征工程包含三个子课题:特征选择、特征提取和特征构造。
特征提取和特征构造是特征变换的不同变体、都会创造一系列新的特征。
在绝大多数情况下特征提取的目标是通过施加特定的映射函数尽可能减少特征维度;
而特征构造则会扩展原始的特征空间;
特征选择则是通过选择一些重要的特征来减少特征的冗余性。
因此,从某些角度而言,自动化的特征工程的本质就是动态进行以上三个子过程。
Part A Feature Selection
t
特征选择会基于原始的特征集合去除一些冗余或不相关信息后建立一个特征子集。这样可以有效简化模型,避免模型过拟合,提升性能。
一般选择出来的特征是高度发散的而且与要检测的目标高度相关。

Fig 5展示了一个特征选择的常规流程:
基于搜索策略选择出来的特征会继续被评估,可以看出来这是一个迭代的过程。
一般搜索策略分为三类:完全搜索、随机搜索和启发式搜索。
Complete Search:
包含穷尽搜索和非穷尽两种,后者包含广度优先搜索、最佳优先搜索、分支绑定搜索和束搜索。
Heuristic Search:
启发式搜索包括顺序前向搜索、顺序后向搜索和双向搜索。前两种分别代表向空集中添加特征或从全集中去除特征,而双向搜索同时使用两种搜索算法,直到最终两种方法获得同样的结果。
Random Search:
随机搜索则是最常使用的方法,包括模拟退火算法和遗传算法。
而子集选择策略也可分为3类。分别是:
filter based:
基于滤波器的方法,主要是根据特征的相关性或散度进行评估,然后根据设定的阈值来选择那些特征。比如计算特征的相关系数、卡方检验或者特征之间的交互信息。
wrapper method:
wrapper method主要是选定特定的子集对样本集进行分类然后用分类精度作为衡量特征子集的评估标准;
embeded method:
第三种是嵌入式方法,将特征的选择作为学习过程的一部分进行,像正则化、决策树、深度学习等均属于嵌入式方法。
Part B Feature Construcion
特征构造则是从原始数据或基础的特征空间中构造新的特征来增强模型的泛化性、鲁棒性。主要是为了增强原始特征的表征能力。一般这一过程高度依赖专家知识,最常用的方法就是进行一些预处理变换,比如标准化、归一化、或特征离散。以及对不同特征进行的变换也不同。比如布尔特征常使用conjunction/disjunction/negation等。而数值特征则使用最大值最小值加减法求均值等操作;一些标量特征则常使用笛卡尔积等。
显而易见,手动探索尽全部特征可能性是不可能的,因此为了进一步提升效率,可以提出并证明一些特征的自动构造方法,与基于手工的方法进行对比,探究自动化的方法是否超越了人类手动选择的方法。
此外,一些搜索算法如决策树、进化算法还需要预定义一个搜索空间,而基于domain的方法则无需预定义搜索空间,它需要的是注释提供的域相关的信息。
在选择合适的操作以及构造特征后,应用特征选择技术来评估选择出来的特征。
Part C Feature Extraction
特征提取主要是通过一些映射函数完成特征的降维工作,通过一些评判指标去除不相关的或冗余的信息。不同于特征选择,特征提取会改变原始的特征,它的核心是对原始特征施加一个映射函数。最常用的数PCA主成分分析降维,独立成分分析以及线性判别分析。近期基于前向传播神经网络的方法也逐渐流行起来,以及还提出了一系列基于自编码器的方法。
Section IV Model Generation
再来回顾一下Fig 1的结构图会发现模型生成被分成了两部分,分别是搜索空间(search space)和优化方法(optimization method)。

搜索空间:
定义了模型结构以及优化原则,模型主要分为两大类:基于传统机器学习的SVM,KNN,DECISON-TREE等方法和基于深度神经网络的方法。
优化方法:
优化方法也被分为两类,一种是超参数优化,比如像学习率、batch_size等训练过程相关的参数,还有关于模型结构的参数,如KNN近邻K的取值、DNN网络的层数等。

本节将主要关注NAS-神经架构搜索策略,Fig 6展示了NAS的具体流程。
可以看到将model generation模型生成进一步分成了三步,分别是:搜索空间、搜索策略和性能评估。
搜索空间:
定义了原则上可以发现的神经架构。不同的设定对应不同的搜索空间,主要包括整体结构、层次化的结构搜索空间、基于模块的以及态射型搜索空间。
搜索策略:
定义了如何高效找到性能良好的架构。
性能评估:
一旦模型生成了,就需要对其性能进行评估。最简单的方法就是将生成的模型训练至收敛然后在验证集上验证。但是这种方法十分费时且消耗计算资源,使用一些方法加速但却可能会降低置信度,因此如何权衡效率和有效性是非常值得探究的一个问题。
本小节主要介绍搜索空间和搜索策略,性能评估将会在下一节进行介绍。
Part A 搜索空间
神经架构可以用一个有向无环图来表示,通过一系列节点和连接结点之间的边组成。每一个node代表张量z而每条边代表从一组候选操作O中选出来的操作o。结合自身能支持的算力可以限定N也就是每个节点支持的可选择的操作种类数,用入度表示。
因此,结点k的计算公式是:
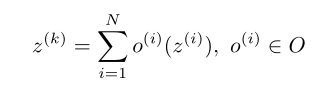
O中包含的候选操作主要有:卷积、池化、激活、跳跃连接、级联、相加。为了增强模型的性能有的研究还会加入一些其他操作,如深度可分离卷积、膨胀卷积、SE模块等。
不同的搜索空间上述操作的选择、集合方式都不同,换言之 搜索空间决定了搜索策略可以探索的结构范式,因此如何设计一个优秀的搜索空间是一个极具挑战的问题。一般一个好的搜多空间应该不带人为偏见、尽可能的灵活多变。下面总结了一些常见的搜索空间结构:
A-1 Entire-Structure Search Space
Fig 7展示了全结构搜索空间示意图,它是最简单最直截了当的一种搜索空间。其中每一个结点代表特定的操作,通过堆叠一定数量的操作节点完成整个网络的搭建,而右边的结构借助skip connection可以探索更深层次的网络。尽管整个结构简洁明了但还是有自身局限性。

因为常规而言网络层次越深泛化性越好,但是搜索如此深层次的网络十分消耗计算资源,而且生成的结构不具备迁移性,往往搜索得到适应某一小型数据集的结构无法迁移到更大的数据集上,不得不生成新的模型。
A-2 Cell-Based Search Space
基于单元的搜索空间就是为了解决模型迁移性的问题,将搜索的网络结构定义为一系列单元结构的组合,借鉴了如ResNet系列网络堆叠残差模块的思想。
Fig8 展示了基于单元的搜索空间结构示意图,分别展示了normal cell和reduction cell两种结构。从而将整个网络结构的搜索简化为最优单元结构的搜索。
其中normal cell的输出保持与输入同样的维度,在实际应用中通常根据具体需求人工设定normal cell的数量;而reduction cell与normal cell结构相同但是会压缩输出的特征图的高度和宽度,通常减半然后输出通道数加倍。
通过基于单元的搜索空间可以仅通过增加更多的单元搭建更大的网络而无需重新搜索单元结构。

比如在Fig 8右侧的cell中 每一个单元包含两个模块(Block),分别代表不同的操作接收不同的输入,而两个模块的输出可以通过addition或concatenation的方式结合。每一个block是一个五元组(I1,I2,O1,O2,C)分别代表两个输入、两种操作和O1O2如何结合。
在实际应用中,需要额外注意以下几点:
(1)不同输入可以有不同的通道数,但一般会通过校准确保所有输入拥有同样的通道数,比如使用1x1卷积;
(2)block的输入可以是来自前一级的cell也可以是同一个单元的另一个block,但需要确保输出保证同样的分辨率即可。
复杂度:
单元内搜索比搜索整个网络架构要高效的多。M是候选的操作数目,L是整个单元包含的层数,B代表每个cell中的Block数,则可能的结构有:
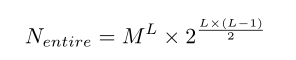
考虑到有两种cell(normal & reduction)因此最终共有的结构数目为:
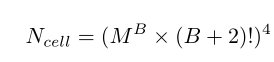
能够看出数目是与层数成指数关系的.
Two-stage Gap:
基于cell的搜索空间包含两个步骤:搜索和估计。首先在搜索空间中选择效果最好的模型没然后从头训练评估效果,但是这两个阶段之间的模型深度存在很大差异。

参见Fig9左边是DARTS生成的模型在搜索阶段仅包含8个cell然而在估计阶段则需要20个cell。尽管在搜索结算找到了浅层模型的最佳结构,但是并不意味着适合评估阶段的深层模型。
换言之,仅仅通过增加更多的cell并不一定有效还有可能降低精度。
为了弥补这两个阶段之间的差距,P-DARTS将搜索阶段进一步划分,逐渐增加网络的深度,但这也增加了对算力的消耗。
A-3Hierarchical Search Space
基于单元的搜索空间有效解决了迁移性的问题,大多遵循两种层次结构:
内部cell级为单元内每个节点选择操作和连接方式;外部网络级则控制空间分辨率的变化。

Fig 10展示了选择网络结构的一种一般公式,按照这一公式可以复现许多性能良好的网络设计,这样就可以充分探究每一层中不同的通道数和feature map的大小。
同时cell内Block的结构也是需要人为设定的,也就是是一个新的超参数。

而Fig 11在展示了在HierNas中高层cell是基于低层cell结构组合得到的。
以及在PNAS和HierNas中 一旦一个cell的结构确定下来那么在整个网络中所有层均使用这种结构。
而MnasNet则使用了新的因式分解的方式来为最终的网络结构的不同层生成不同的单元结构,即MBConv,每一个cell包含不同数目的block,但同一个cell中的Block具有相同的结构,从而有效平衡了模型performance和latency的问题。
以及由于NAS计算消耗很大,绝大多数可微分的NAS可以先在小型的代理数据集(proxy dataset,如CIFAR-10)上搜索出一个较好的cell结构然后将其迁移到更大的目标数据集上(如ImageNet)。
A-4 Morphism-Based Search Space
基于网络态射的搜索空间
牛顿有句名言:我能看的更远是因为我站在巨人的肩膀上。
同样也有类似思路的训练技巧,如知识蒸馏、迁移学习等。
正如Net2Net是基于已有的网络结构进行态射得到新的网络结构,主要有两种:深度和宽度态射,通过在原有网络结构上修改可以保留原来网络的优点还能保证新的网络能够还原回源网络,从而保证它的表现至少不会低于源网络。
但是目前只能分别修改深度和宽度,同时还会引发稀疏性问题。
在network morphism能够从父网络中继承知识并且短时间内训练成一个更强大的网络,并且有以下好处:
(1)可以嵌入non-identity layer并且处理任意非线性激活函数;
(2)可以在同一操作中同时变换深度、宽度、以及kernel的态射。
Part B Architecture Optimization
在搜索空间确定后就需要通过搜索策略搜索出最佳的网络架构,这一过程称为Architecture Optimization(AO).
传统的神经网络结构由一组超参数定义,根据在验证集的表现来调整超参数,因此调参的过程需要依赖专家知识,需要大量的时间和资源消耗进行尝试;因此自动化的搜索策略就将人类从这一繁重的工作中解放出来,能够自动化搜索新的网络结构。具体的AO搜索策略可以分为以下几类:
B-1 Evolutionary Algorithm
与传统的全局搜索方法相比,进化算法是一种更成熟的全局优化方式,具有更高的鲁棒性和泛化性。可以更好的解决传统优化算法难以解决的复杂任务。
Encoding Scheme
不同的进化算法使用不同的编码策略来表示网络结构,大体分为直接编码和间接编码两种类型。比如Genetic CNN将网络结构编码为定长的二值序列,1代表两个节点相连,0表示不相连。
虽然这种方法编码简单但是计算控件是结点数的平方。还有将网络结构编码为有向无环图的;
而间接编码则是按照指定的规则生成编码这样可以有更紧凑的网络表示。比如Cellular encoding按照简单的图语法将一系列神经网络编码为一组label tree.
常规的进化算法包括以下4步骤:选择-交叉-变异-更新

参见Fig 14
Selection:通过交叉的方式从一组生成的网络中选择一部分万罗,目的是在保留现有性能的同时去除一部分weak的结果。
网络的选择主要有3种策略:
(1)Fitness selection:
根据每一个网络计算的适应度进行选择,种群中的个体被选中的概率与个体对应的适应度相关;
(2)rank selection:与适应度选择类似,但是不是根据绝对值而是根据种群中每个个体的相对适应度进行选择;
(3)tournament fitness:
锦标赛选择首先以等概率p从种群中选取k个适应度最高的个体,随后以概率(1-p)p选择k个适应度次之的个体,然后以概率(1-p)^2p选择适应度再次之的个体,循环往复进行。
**Crossover:**
选择过后,每两个网络通过交叉产生一个新的网络后代,继承父母各一半的遗传信息。具体的交叉方式根据编码方案不同而不同;以二进制编码为例,会将网络编码为一个线性的二进制串,这样父代网络可以通过一点或多点交叉组合,但是这样有可能会导致数组损坏;对于基于cell的编码方式一般会从一个父代网络中随机切割下一个子树然后替换掉另一个父代网络的部分子树。
Mutation:
父母的遗传信息复制传递给子代的过程中也会发生变异。比如随机独立翻转不同位置的点变异就是广泛使用的一种变异方法;还有的变异有:使能或禁用两层之间的连接,或者添加或删除两个节点或两层网络之间的skip connection.而也有研究[25]预先定义了一组变异算子,比如改变学习率或者filter size,或者移除 节点之间的skip connection。虽然变异有可能会损害网络结构甚至导致功能丧失,但是使用突变也能探索更新颖的结构、确保多样性。
**Update:**
许多网络结构就是通过上述步骤生成的,但鉴于有限的计算资源必须删除其中一些内容。
比如在[25]中选择出的网络中性能最差的两个就会被立即移除;还有的是移除最老的网络;或者定期移除所有的模型。在EENA中并不会丢弃任何网络而是通过一个λ参数调节种群数量,即以概率λ删除性能最差的模型和以1-λ概率删除最老的模型。
B-2 Reinforcement Learning
Zoph等人首次将强化学习用于NAS。一般使用RNN作为代理(agent),在每一步骤执行一个动作从搜索空间采样一个新的结构,并且接受观察到的状态和reward,随后更新代理的采样策略。

环境是指使用标准的神经网络训练代理生成的网络并进行评估。
这方面主要变体是使用不同的评估策略或者编码方式。
这部分一些研究工作在CIFAR-10数据集和PTB数据集(Penn Treebank)取得了SOTA,但是需要耗费巨大的时间和计算资源,比如有的需要在800块K40上训练28天;或者在10块GPU上训练10天。
这种巨大算力的消耗不是一些独立研究者可以负担的因此又提出了一些算法:
BlockQNN提出了一种分布式异步框架结合早停搜索策略,仅用1个GPU在20小时就可以完成搜索。而ENAS则是财通参数共享的思想,将所有孩子网络看做是一个super-net的子图,然后子图之间共享参数,这样就避免了需要从头开始训练每个子网络。ENAS最终仅用1块GPU搜索10小时就可以得到性能最佳二段结构,比前人研究提速了近1000倍。
B-3梯度下降
前面的搜索策略都是在离散的搜索空间进行采样,而DARTS首次提出借助softmax函数将离散的搜索空间转换为连续可微的搜索空间:

其中O代表可进行的操作,α代表一组节点之间的权重,K则是预先定义的云溪的操作。经过relaxation后网络架构搜索就变成了α和weight的联合优化。损失函数表述为:


Fig 17展示了DARTS
每个cell中包含4个节点,边则是候选的操作集合,每个操作的权重相等。因此alpha神经架构是一个超图(super_net),包含了所有可能的网络结构。在搜索最后通过仅保留所有权重最大的混合操作导出最终的结构。
DARTS极大的缩短了搜索时间,但是仍然存在以下问题:
首先DARTS将神经网络的结构和权重联合优化描述为一个双层优化问题,但是这一问题无法直接解决因为两个都是高维参数。
因此常使用single-level优化:

虽然可以通过常规训练完成这一single_level优化但是搜索出来的结构在验证集上的性能常常无法保证。
在[150]中作者提出了mixed-level优化
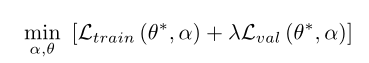
引入了λ一个非负的归一化参数用来权衡train和validation的比重。λ=0就退化为single-level optimization;λ=无穷就退化为bilevel optimization,实验结果显示mixed-level optimization不仅可以一致过拟合问题还可以避免在bilevel optimization中常出现的梯度错误的问题。
其次DARTS每条边的输出是所有候选操作的加权和,这就会导致对GPU的需求会随着候选操作的数目而线性增加。因此有的研究就通过使用reparameterization trick从super-net中采样。这样网络结构就被完全分解可以根据具体的分布进行建模,这样就提供了一种有效的方法采样子结构,并且允许梯度反向传播。
另一个问题就是同时优化不同的操作十分困难,有的操作还会起副作用。比如研究发现在DARTS后面的搜索阶段主要是skip connection这样就不利于网络结构的加深,反而对网络精度有负面影响。因此在DARTS+中又引入了早停法,在一个cell中存在两个或多个skip connection时搜索就会停止。
B-4基于代理模型的优化
另一种搜索策略则是使用代理模型的SMBO(surrogate model-based optimization),核心就是构建优化目标的代理模型,不断迭代保存过去的评估结果,并预测最可能的网络结构。这样也可以有效缩短搜索时间,提升效率。
SMBO算法根据不同的代理模型,可大致分为:贝叶斯优化(随机森林、高斯过程)和深度神经网络两类。
B-5网格和随机搜索
Grid Search 和Random Search都是简单易行的搜索策略也被广泛用于NAS中,并且有的研究显示使用随机搜索可以设计出性能十分可观的网络结构,而其他SOTA的NAS算法并没有超出随机搜索效果很多。
B-6混合搜索算法
前面提到的搜索算法都有各自的优缺点:
(1)进化算法鲁棒性很强但是十分消耗计算资源,并且其进化操作是随机执行的。
(2)尽管强化学习可以搜索到复杂的结构模式,但是搜索的效率和稳定性无法保证,因为agent需要尝试多次才能获得正向反馈。
(3)基于梯度的搜索算法极大的提升了搜索效率但是本质上还是在一个super-net中进行,限制了网络结构的多样性。
因此提出了混合搜索算法,结合不同搜索策略的优点。主要包括:
(1)EA+RL:
提升了搜索效率也避免了进化的随机性。
(2)EA+GD:
将进化算法与梯度下降结合,搜索出来的结构在一个super-net中共享参数并在不同的epoch的训练集上进行调优。
(3)EA+SMBO。
比如[43]使用随机森林作为代理来预测模型性能,提升了对模型适应度的评估。
(4)GD+SMBO。
在NAO中使用自编码器来生成神经网络结构,并且建立了一个回归模型作为代理来预测生成结构的性能。
Part C Hyper-parameter Optimization
绝大多数NAS在搜索阶段对所有的候选结构使用相同的超参数;在找到潜力最佳的神经架构后有必要重新设计一套超参数来重新微调网络。因此就提出了一系列超参数优化方法(HPO),如网格搜索、随机搜索、贝叶斯优化、基于梯度的优化和基于种群的优化。

C-1 Grid and Random Search
Fig 18展示了Random Search 和Grid Search的区别: GS按照固定的间隔划分搜索空间,在评估所有格点的性能后选择最好的点;而RS顾名思义就说从候选的点中随机选择性能最好的点。
GS实现简单但是当超参数搜索空间非常大时,计算是十分昂贵且效率低下的,因为搜索的数量会指数增长。
为了减轻这一问题,有的研究提出coarse-to-fineGS,首先使用粒度较粗的网格搜索定位到较好的区域,然后对该区域进行粒度较细的进一步搜索。
以及也有一些研究证明RS比GS效率更高,但是RS并不能保证达到最优,这就意味着搜索的时间越久月可能找到最优的超参数,但这也会消耗更多的计算资源。
C-2贝叶斯优化
BO是一种高效的全局优化方法,但本小节仅会简要介绍BO,深入的探讨还请读者移步[168,167,182,183]。
BO是一种基于代理模型的优化方法(SMBO),它通过建立一个概率模型完成从超参数到验证集评估效果的映射,这样有效的平衡了探索尽可能多的超参数以及为某些可能的超参数尽可能多的分配资源这一问题。

Algorithm 1展示了SMBO的主要流程,需要预先定义以下参量:
f:评估函数、θ搜索空间、采集函数S、概率模型M、和记录数据集D。
1.初始化获取数据集;
2.借助采集函数S从概率模型中选择可能的网路架构;
3.通过f评估函数对选出来的结构进行评估,也就是将选出来的这组超参数带入网络中进行训练,并且在验证集上进行验证。这一步需要消耗大量算力;
4.更新数据集D。
以上过程会循环选参数T次,T就根据时间和资源决定。
BO常用的代理模型有高斯过程(GP),S随机森林和树结构。

Table II展示了部分目前开源的BO方法,可以看到最广泛采用的是GP,但是其搜索空间与数据样本成正比,而RF可以更好的处理更大的空间和更多的数据样本。
C-3基于梯度的优化
另一种超参优化方法时基于梯度的优化,不同于BO.RS,GS等黑盒优化,GO基于梯度信息优化超参数,这样可以显著提升超参数优化的效率。
但是基于梯度信息优化数以千计的超参数仍然需要对算力要求很高,因此[187]使用梯度近似信息热不是真正的梯度来优化超参数,这样在训练收敛前就可以优化超参数。
[188]中研究了正向的和反向的基于梯度的优化方法。reverse-mode GO需要存储整个网络的训练历史,从而计算超参数的梯度;而forward-mode GO可以实现对超参数的实时更新,效率大增;[189]中提出了基于梯度的优化器,不仅可以优化常规的超参数(如lr)还可以优化优化器的参数(如Adam优化器的动量系数)
Section V Model Estimation
一旦生成了某种神经网络架构就要对它的性能进行测试。常规方法就是将模型训练至收敛然后验证其性能。但是这方法极其费时且需要强大的算力支持,比如有的验证需要在800块K40上训练28天等,因此下面总结了几种加速模型评估的方法:
Part A Low fidelity
低保真度
因为模型的训练时间与数据集和网络规模的大小高度相关,因此可以借助不同的方法加速模型的评估。
首先就是可以压缩输入图像的数目或分辨率;其次可以通过压缩模型规模完成低保真度的评估,比如减少每层卷积核的数目。
还有[192]通过一系列低保真度的估计量组合成essemble estimator这样就避免使用单一的低保真度估计量评估带来的误差;以及[34]等人证明了训练时间的长短与模型性能的相关性并不强,从而证实了对网络进行长时间搜索是不必要的。
Part B Weight Sharing
权重共享可以用来加速NAS的评估。比如[193]中提出的Transfer Neural AutoML就会利用先前任务中的知识来加速网络设计;ENAS中所有的孩子网络都是共享参数的,这样使得搜索速度提升了上千倍;而基于态射的搜索空间也会继承之前网络结构的权重。
Part C Surrogate
基于代理的方法是另一种用来近似黑盒函数的方法。一旦找到了一个较好的近似,在此基础上继续进行优化的计算代价是微不足道的。比如在PNAS中就引入了代理模型控制搜索的方向,使得评估时间较ENAS提升了5倍;最终整体计算时间提升了8倍。但是当搜索空间很大并且难以量化的时候,此时对每种配置都进行评估代价是十分昂贵的,此时基于代理的方法是不适用的。在[199]中提出的SemiNAS无需在训练结束再评估模型精度而是通过控制器就可以预测精度。
Part D Early Stopping
早停法最早是用来防止机器学习中的过拟合问题,近期应用于NAS,对于一些性能不佳的网络架构停止对他们的预测,从而加速NAS的评估。比如[202]从文献中选取各种参数模型,通过加权组合以上模型获得一个学习曲线模型,从而用于预测网络的性能;还有[203]通过计算梯度的局部统计数据进行早停,使得优化器可以充分利用训练数据,不再依赖验证集的参与。
Part E Resource-aware
资源敏感的
早期NAS的研究聚焦于如何搜索出性能更高的申精加否,如提升分类精度,而不管计算资源的消耗;随后就有研究聚焦于如何权衡网络性能和资源预算,resource-aware算法主要将计算成本作为资源约束添加到损失函数中。这些计算成本有不同的类型,如
(1)参数规模;
(2)乘累加操作的次数;
(3)浮点操作的次数;
(4)实际的延时。
比如MONAS中将乘累加操作次数作为计算成本的约束,直接加入到reward function中;在MnasNet中则是定制了一个带权乘积近似帕累托最优:
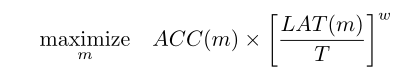
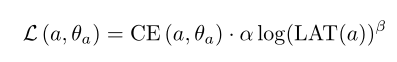
其中LAT代表的是具体设备上进行推断的延迟,T是目标延迟、w是权重参数;在FBNet中则是使用了一个延迟查找表来估计推断时网络的总体延迟,损失函数定义为:
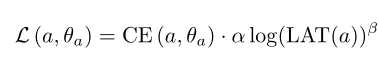
其中CE代表的就是网络结构α和权重θ的交叉熵损失;在MnasNet中则是通过设置两个超参数来控制损失函数和延迟项的幅度。
Section VI NAS Performance Summary
在第四小节总结了不同类型的搜索空间和搜索策略,第五小节则主要总结了模型评估策略。本节主要总结、对比前面涉及到算法的性能比较;以及探讨在NAS中值得研究的问题以及如何将NAS应用于除图像分类外的其他任务。
Part A NAS Performance comparison
主要根据网络精度和算法效率作为不同算法的评价指标。由于不同算法加速使用的GPU不同,本文使用 GPU Days近似表征算法效率。
GPU Days定义为:
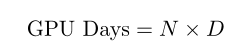
N代表使用GPU的数量,D代表实际搜索的时间。


Table 3和Table 4分别展示了不同算法在CIFAR-10和ImageNet上的对比结果,可以看到早期的工作主要聚焦于如何借助EA或RL提升模型精度而不在意资源的消耗情况;后期的一些研究逐渐聚焦于如何保持现有精度的前提下尽量提升算法效率,比如EENA通过精心设计变异和交叉操作,复用学习到的信息来指导进化过程,从而提升基于EA的算法效率;而ENAS则是最早的借助参数共享提升基于RL的算法效率的研究,有效减少了参数数量,将搜索时间缩短至1天内。我们还发现许多基于梯度的搜索算法可以大大减少 搜索的计算资源消耗,并且达到SOTA效果,需要后续工作都是基于这一方向继续进行优化。
有趣的是,随机搜索也能达到很可观的结果,有研究指出,将随机搜索与权重共享结合可以优于一系列强大的算法,如ENAS和DARTS。
Kendall Tau metric
虽然RS可以达到很可观的效果,但一个本质问题是:与RS相比,其他架构优化的算法的优势和意义是什么?研究者尝试使用其他的评价指标来回答这一问题,而不仅仅依赖最终的模型精度。
绝大多数NAS包含两个阶段:
(1)在训练集中搜索性能最佳的架构;
(2)扩展该结构并在验证集上验证性能。
但是这两个阶段的性能往往存在巨大差异,也就是在训练集上达到最佳性能的架构并不是在验证集上表现最佳的那一个。
因此许多研究人员不再仅考虑最终的精度和搜索时间成本,还会通过Kendall Tau metric来衡量搜索和评估阶段之间的相关性:

其中Nc和Nd分别代表一致和不一致的组合,τ则是在[-1,1]之间的一个数,τ=1表示二者排名一致;τ=-1代表两者排名完全不一致;τ=0代表二者排名没有任何关系。
NAS-Bench Dataset
虽然Table 3 和Table 4中对各种算法进行了对比,但由于每种算法训练相关的超参数设置以及是否使用数据增强都是不一致的,因此这一对比是不客观的。
NAS-Bench-101 则是为了解决算法不可再现问题作出的开创性工作。NAS-Bench-101提供了一个数据集包含了423,624种独一的神经架构,都是基于一个固定的搜索空间生成和评估的,并且映射到了CIFAR-10上的训练和评估性能。还有研究进一步扩展到了多个数据集上。这样可以让研究人员能够集中精力关注于如何优化算法有效性和算法效率,避免对一些结构重复训练,并且有助于NAS社区的发展。
Part B One-Stage vs Two-Stage
NAS
算法可以分为One-Stage 和Two-Stage两类,参见Fig 20.

Two-Stage NAS包含两个阶段,搜索和评估。搜索阶段涉及结构优化和参数训练,这十分消耗计算资源;然后搜索阶段性能最佳的网络会在测试集上重新训练。
One-Stage NAS对于一个较好的网络架构直接使用而不需要微调,其中双向箭头表示超参数优化和网络结构优化是同时进行的,但是这也是许多NAS问题的主要挑战所在。
比如Progresive shrink算法会在训练结束后对权重进行后处理,以及会预先训练整个网络然后逐渐微调各个子网络,在通过设定约束确保每个子网络的性能;但即使这么做仍然十分消耗计算资源。
Part C One-Shot/Weight-sharing
One-Shot≠One-stage
区分是否是One-Shot是看候选的网络架构是否共享参数,而One-Shot与否则是根据搜素时的阶段,但据我们观察大多数One-Shot都是遵循One-Stage的。
One-Shot NAS最主要的特征是其搜索空间是嵌入在一个super-net中的,因此所有可能的网络架构都可以从super-net中派生出来。

Fig21展示了One-Shot和Non-one-shot的区别,可以看到One-Shot都是一组同心圆表示不同网络之间的权重是共享的,而One-Shot也可以分为两类,主要在于结构和权重在训练时是如何优化的,分为二者是耦合的或者二者是解耦的。
Coupled Optimization:
网络架构和权重的优化是耦合的。比如ENAS会用LSTM离散采样出一个新的网络架构然后使用几批训练数据来优化这个体系结构的权重,以上步骤迭代多次后就会得到一个不同架构及其各自精度的一个记录;然后在从中选择性能最好的进行重训练。
DARTS也用类似的权重共享策略,但是其架构的分布是连续参数化的,在super-net中包含全部的候选操作每个操作都有需要学习的参数,最好的体系结构也可以从分布中导出。但是不同之处在于DARTS会直接优化supernet的权重和架构分布,因此需要消耗极大的GPU内存。虽然有些基于DARTS的改进提出各种方法减少对计算资源的消耗但是权重和架构的耦合优化不可避免的会在优化过程中引入偏见,因为他们无法平等的处理各个子网络。一些很快就收敛的子网络更容易获得优化的机会但是这些体系结构仅是候选架构中很小的一部分,因此能够找到最佳网络架构的条件是非常苛刻的。
耦合优化的另一缺点就是当连续采样训练心得额架构时以前架构的权重将受到负面影响,导致性能下降。在[228]中将这一问题称之为multi-model forgetting.为了解决这一问题[229]将supernet训练建模为连续学习一个约束优化问题。
Decoupled Optimization:
解耦优化是将体系结构和权重的优化分解为两个阶段
(1)训练super-net
(2)将训练的super-net用于预测不同体系结构的性能,从中选择最优前途的体系结构。
在训练supernet阶段不能像常规网络那样直接训练因为supernet的权重也是深度耦合的,此时使用权重共享会降低单个结构的性能也会影响候选网络结构的排序;为了减少权重耦合的程度提出了许多one-shot方法,比如通过随机采样策略好哦这基于RL控制器进行采样,亦或是借助一个辅助的hypernetwork产生网络权重等。
Part D Joint Hyper-parameter and Architecture Optimization
绝大多数NAS在整个搜索的训练阶段都是用固定设定好的超参数,搜索结束后再继续优化超参数,但是由于不同结构倾向于选择不同的超参数这样搜索可能会导致搜索结果不是最优的。因此一种十分有前景的方式是超参与网络结构进行联合优化(HAO)。
比如Zela就是将NAS搜索转化为超参数优化问题,这样空间搜索就可以与标准的超参数优化结合;问题在于结构搜索通常是有类别的,而超参数的优化有离散的(比如优化器的类型)也有连续的(比如学习率)。而AutoHAS就将连续的超参数离散为多种类别的线性组合。
在训练supernet时每条路径的概率会逐渐增加,像GreedyNAS就会更集中在更具有潜在价值的路径上,并且实验也证明与随机搜索相比在一些较高层次相关结构的选择方面会更有效。
supernet训练后的第二个阶段就是选择最具潜在价值的架构,这也是绝大多数NAS研究的任务,不管是SMASH还是随机搜索都会对搜索到的一系列架构根据性能排序。
其中SMASH会根据所有网络架构验证的性能进行排序,以及[230]观察到具有堆成KL散度更小的体系结构往往性能更好:
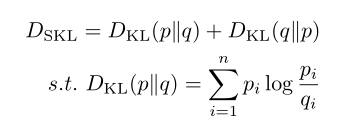
因为计算KL散度需要的算力还是很小的。
另一种就是基于进化算法进行评估。比如SPOS就是用进化算法才能够supernet中搜索架构,并且比第四小节中介绍的EA效率更高,因为每一个采样的结构仅进行推理阶段即可。
而SETN则是使用一个estimator来估计每一种架构具有更低验证损失的概率,并且实验也证明SETN比随机搜索效果更好。
Section VII Open Problems and Future Work
本小节主要讨论AutoML一些开放性问题,以及指明未来的研究方向。
Part A Flexible Search Space
第四小节总结了多种类型的搜索空间,基本操作主要有卷积和池化,一些研究尝试加入更为复杂的模块,如MBConv,虽然这些搜索空间已经证明能生成性能良好的神经网络但他们都是基于人类的先验知识不可避免的引入了偏见,依旧没能摆脱人工的设计范式。
AutoML-Zero使用非常简单额数学运算(sin,cos,mean,std)作为搜索空间的原始操作,并使用EA发现完整的机器学习算法,从而尽量避免人类偏见的影响。虽然AutoML-Zero设计的网络仅有两层与NAS设计的复杂网络相去甚远但实验结果表明在最少人类干预下有助于发现新的模式。
因此如何设计一个更加通用灵活的、无人类先验影响的搜索空间、如何基于这一搜索空间发现新的神经架构,是一个极具挑战也极具优势的方向。
Part B Applying NAS to More Areas
第六小节已经介绍目前NAS已成功用于CIFAR-10和ImageNet上的分类任务,除此之外Table 5还展示了NAS用于其他CV任务,如语义分割、物体检测、行人重识别、超分等。

但是在NLP任务中,目前大多数研究还局限于在PTB数据集上进行研究,并且Fig 22显示出目前NAS性能距离人工设计的网络模型仍有很大差距,因此NAS在NLP领域仍有很长路要走。
除此之外,NAS有其他有意义的应用,如网络压缩、推荐系统审甚至寻找损失函数等,这些有趣的应用都显示NAS在其他领域有非常广阔的应用潜力。
 Part C 可解释性
Part C 可解释性
虽然AutoML已经证明在探索多边形上比人类更高效,但是仍然缺乏有效性的可解释性说明。比如在Block QNN中人们依旧不清楚为什么NAS倾向于选择“Concatenation”处理每个cell内block的输出,而不是选择element-wise addition操作。近期的研究也多半是事后诸葛亮,缺乏严谨的数学证明。因此AutoML的可解释性研究也是一个重要的研究方向。
Part D 可复现性
众所周知ML一大问题就是可复现性,AutoML也不例外,特别是NAS目前仍有许多参数需要手动设定,但是原始文献中并没有包含太多实现上的细节。比如[120]的实验表明seed的设置十分重要但文章中并没有明确实验中设定的seed到底是多少;此外巨大的算力消耗也是难以复现的一大障碍,因此使用NAS-Bench是一个较好的策略,这样可以让研究者聚焦在优化设计上而不用浪费大量时间在模型评估上。
Part E 鲁棒性
目前NAS搜索得到的一些结构已经在一些开源数据集取得了较好的效果,但是这些数据集一般都提供很完善的标记信息。但是在现实世界中数据往往会有噪声、标记信息不足,还会有许多被精心设计的对抗性数据,DL就很容易被这些对抗性数据迷惑,NAS自然也不例外。因此有的研究致力于如何提升NAS的对抗性和鲁棒性。
Part F HPO
绝大多数NAS研究都将超参数优化和结构优化作为两个独立的阶段,但正如本文前面提到的,这些方法之间有很大的重叠,因此如何优雅的将超参数优化和结构优化联合进行是一个值得探究的方向。
Part G 搭建完整的AutoML
流程
目前诸多研究仅聚焦在AutoML整个流程中的一部分,因此设计一个易于使用的完整的AutoML流程是很有必要也是十分有前景的。
Part H Lifelong Learning
终生学习问题,目前绝大多数AutoML算法仅聚焦基于特定数据集解决特点问题,比如在CIFAR-10上进行图像分类任务,但是一个高质量的AutoML系统应该具备终身学习的能力,也就是:
(1)有效的学习新数据;
(2)同时记住旧的知识。
learn new data
首先AutoML系统应该能根据先验知识解决新的任务,也就是学会“学习”,就想小朋友可以快速区分老虎、兔子,但是深度学习却需要大量的训练数据进行训练后才能正确区分。一个热门的研究课题就是元学习(meta-learning),旨在基于先验经验学习解决新任务。
Meta Learning
已有的NAS可以为单个任务搜索到较好的网络架构,但是面对新任务就必须重新搜索。已有研究提出基于元学习的迁移NAS(TNAS)可以较为快速的适应新任务。
学习新数据的另一挑战就是如何在少样本场景下学习新任务。
Unsupervised Learning:
元学习聚焦于有标签数据,但是某些情况下无法获取全部的标注数据,因此就需要以无监督的方式进行NAS。目前已有研究证明基于无标签数据进行搜索结果与有标签数据进行搜索性能相当,由此引发人们思考:标签信息是否对NAS是必要的?以及什么才是真正影响NAS的?
Remember old knowledge
此外AutoML系统还亚能够在坚持获取新知识点的同时记住旧知识,但是目前当在一个新的数据集训练一个预训练模型后性能会大大下降。
Incremental Learning增量学习也许可以减轻这一问题,还有研究提出[305]Learning without forgetting(LwF)即学习不遗忘,仅使用一小部分旧的数据进行预训练,然后逐渐增加新数据的比例。
Section VIII Conclusion
本文对AutoML流程进行了细致且系统的综述,从数据准备到模型评估,并且还对当前一些NAS算法的性能和效率进行了总和对比;随后对NAS不同的研究方向进行了深入的探讨。
最后还就未来一些有趣的或者指的探究的方向进行了讨论。
尽管AutoML方兴正艾,正处萌芽,但我们相信未来诸多问题都会得到解决。
因此本文对目前AutoML的工作进行综合明细的分析,希望惠及研究人员以协助他们未来的工作。