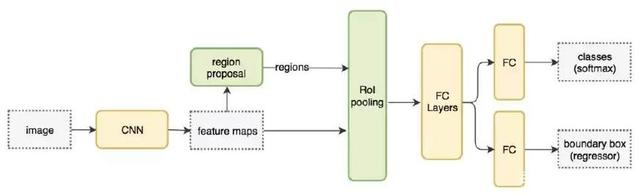
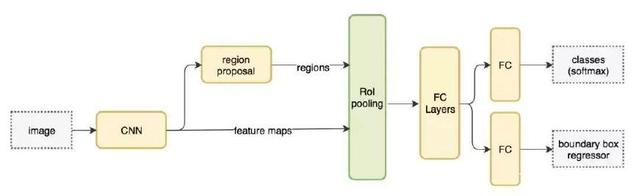
Anaconda官网下载安装下一步进行到底,相关环境那儿记得打勾,不然就自己添加下环境变量就好(另:一般进官网就找Download,再找相关想下载的版本/适配系统之类的)这里下载的是Python 3.7 version for Windows,下完后Ctrl+R,在cmd里输入python,输出>>>,且有备注Anaconda,Inc就没错了
Cuda9.0(NVIDIA官网)&cudnn v7.0.4 for CUDA9.0(cudnn需要注册一下,简单QQ邮箱注册下就行)【地址在这】 Cuda9.0下载一般就local直接下个exe,但可能需要等一段时间,不然就选择network版本的,会先下个小包,相当于setup的东西,再帮你在线安装。