1.引言
贝叶斯方法是一个历史悠久,有着坚实的理论基础的方法,同时处理很多问题时直接而又高效,很多高级自然语言处理模型也可以从它演化而来。因此,学习贝叶斯方法,是研究自然语言处理问题的一个非常好的切入口。
2.朴素贝叶斯分类方法
前面学的knn算法,是看结果划分到哪个类。而朴素贝叶斯的结果是分完以后讲样本归类到后验概率最大的那个类。本节典型的例子是垃圾短信,邮箱的分类。
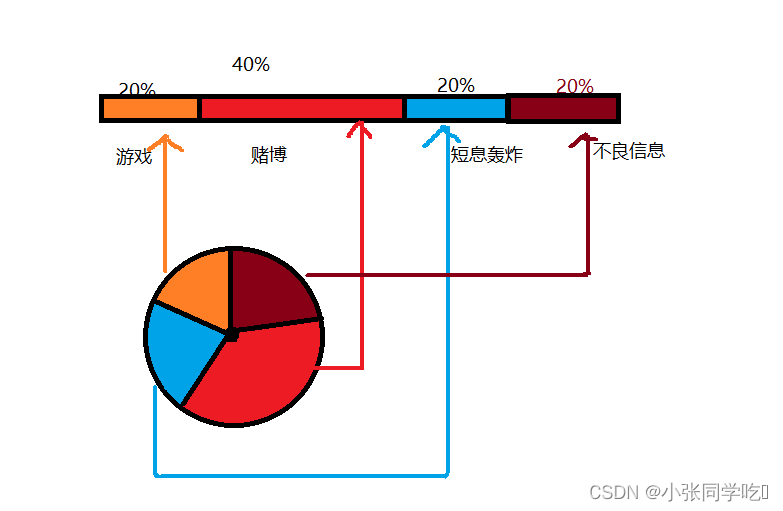
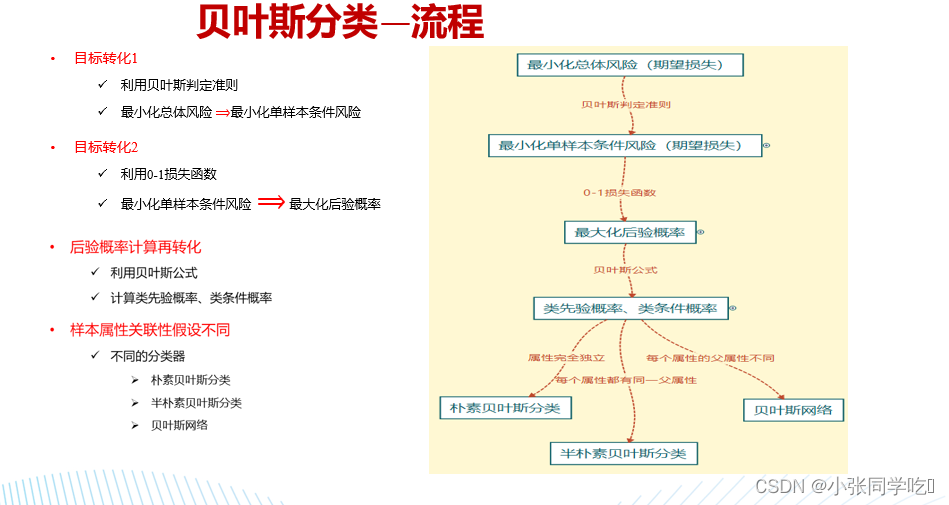
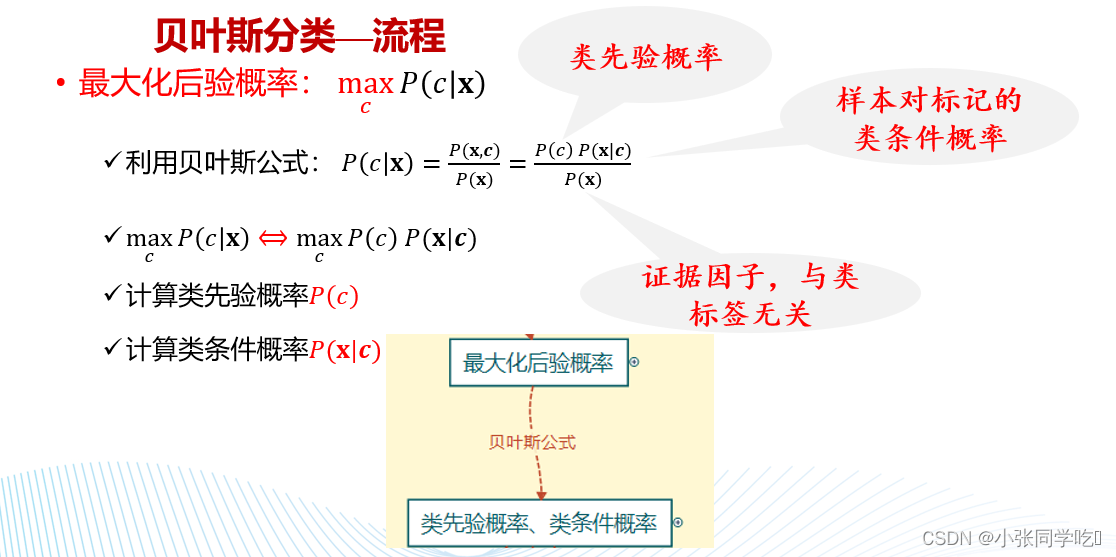
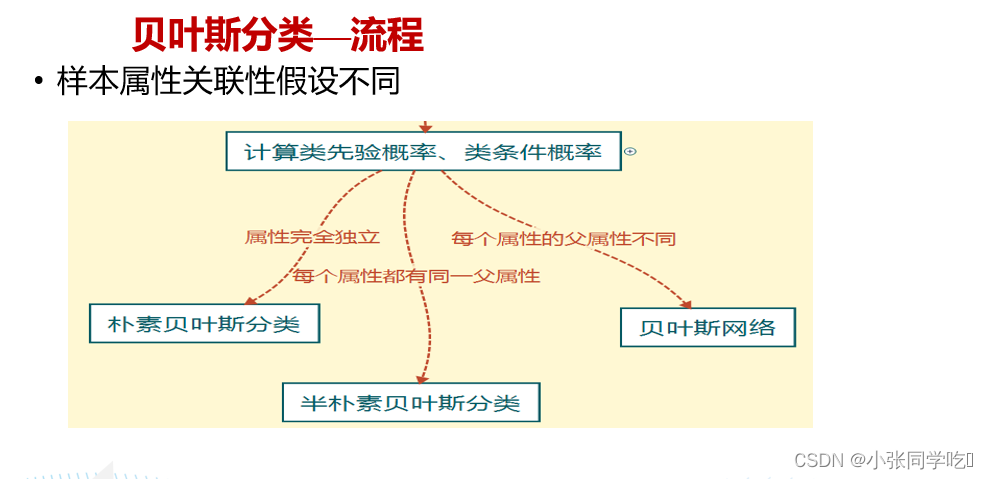
流程:





3.概率基础
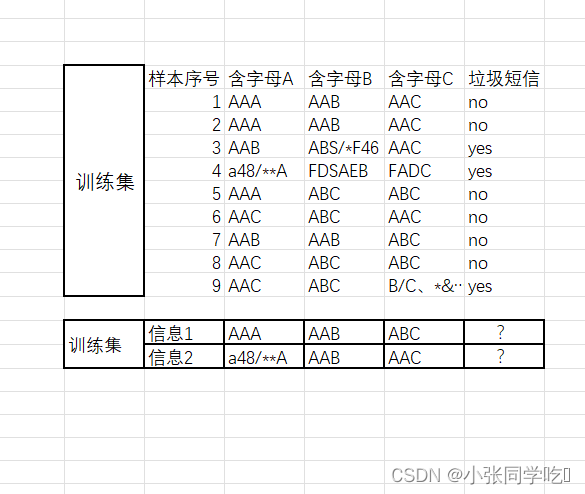
问题1:垃圾短信的概率?
问题2:信息含字母A(内容为AAA)且含字母B(内容为AAB)的概率?
问题3:在是垃圾短息的情况下,含字母A内容为AAA的概率?
问题4:在不是垃圾短息的情况下,含字母A内容为AAA的,且含字母B(内容为AAB)概率?
答案1: P(垃圾短信): 3/9 ==1/3
答案2:
P(AAA,AAB) = 2/9
答案3: P(AAA|垃圾短息)= 0/3 = 0

答案4:P(AAA,AAB|不是垃圾短信)= 2/(9-3) = 1/3
贝叶斯公式:

注意:我们计算出某个概率为0,合适吗?
问题3求出的答案是0,得到0的结果是由于样例较少,这里引入一个处理方法:拉普拉斯平滑系数(目的:防止计算出的分类概率为0)

解决问题3: P(AAA|垃圾短信)= 分子:0+1 分母:特征词出现的个数:5个特
征词有AAA,AAB,AAC,ABC,FDSAEB
最终答案:P(AAA|垃圾短信)= 0+1/3+5 = 1/8
4.朴素贝叶斯特征提取
# 导入TfidfVectorizer
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 输入训练集矩阵,每行表示一个文本
train = ["生活是一种律动,须有光有影,有左有右,有晴有雨,趣味就在这变而不猛的曲折里,微微暗些,再明起来,则暗得有趣,而明乃更明",
"照片这种东西不过是生命的碎壳,纷纷的岁月已过去,瓜子仁一粒粒咽了下去,滋味各人知道,留给大家看的唯有那狼藉的黑白的瓜子壳",
"有才而性缓定属大才,有智而气和斯为大智,人褊急我受之以宽容,人险仄我持之以坦荡。缓事宜急干,敏则有功;急事宜缓办,忙则多错",
"才不足则多谋,识不足则多虑,威不足则多怒,信不足则多言,勇不足则多劳,明不足则多察,理不足则多辩,情不足则多仪"]
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
def cut_test(train):
te = ' '.join(list(jieba.cut(train)))
return te
def tf():
train_new = []
for i in train:
train_new.append(cut_test(i))
# 实例化tf实例
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
tv_fit = tv.fit_transform(train_new)
# 查看一下构建的词汇表
print(tv.get_feature_names_out())
# 查看输入文本列表的VSM矩阵
print(tv_fit.toarray())
if __name__ == '__main__':
tf()
5.朴素贝叶斯分类的sklearn实现



6.垃圾短息分类
#!/usr/bin/env python
# encoding: utf-8
"""
思路:
1、数据集读取,数据处理及训练集和测试集划分
2、选取不同分布的朴素贝叶斯模型进行分类模型训练与测试、评价
"""
import pandas as pd
import warnings
from sklearn.feature_extraction.text import TfidfVectorizer # 文本型数据处理
from sklearn.preprocessing import LabelEncoder # 字符串型数据编码
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from matplotlib import rcParams
import matplotlib
# matplotlib.use("Agg") # 输出时不显示绘图
import matplotlib.pyplot as plt # matplotlib.use('agg')必须在本句执行前运行
rcParams['font.family'] = 'simhei' # 可以让图像中显示中文(黑体),无需引用
rcParams['axes.unicode_minus'] = False # 解决负数坐标显示问题
warnings.filterwarnings('ignore')
# #############################################################################################
# 公共部分:分类模型评价体系evaluation
# todo: 构建分类模型的评价体系并存储在evaluation中,方便对比查看,全局变量
evaluation = pd.DataFrame({'Model': [],
'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': [],
'AUC值': [],
'5折交叉验证的score': []})
# #############################################################################################
# 步骤1 todo: 数据读取、单词文本处理及标签数值化处理、数据集划分
def data_preprocess(train_size):
# 步骤1.1 todo: 读取数据并统计数据类别信息
df = pd.read_csv('./data/SMSSpamCollection', delimiter='\t', header=None) # 利用pandas直接读取已有数据,数据以tab分割
print(df.describe()) # 了解数据的基本信息
print('为spam短信数量:', df[df[0] == 'spam'][0].count())
print('为ham短信数量:', df[df[0] == 'ham'][0].count())
# 步骤1.2 todo: 对数据集中单词文本进行处理
# 由于数据集为单词文本数据,构建TfidfVectorizer来计算每个单词的TF-IDF权重
tfidf_vectorizer = TfidfVectorizer()
X = tfidf_vectorizer.fit_transform(df[1])
X = X.toarray() # 将数据矩阵转化为数组
voc = tfidf_vectorizer.get_feature_names_out() # 构建的词汇表
print(len(voc))
# 步骤1.3 todo: 目标变量中为字符串型数据,使用labelEncoder处理(spam-1,ham-0)
le = LabelEncoder() # 对定型特征多值化
y = le.fit_transform(df[0])
# 步骤1.4 todo: 对整体数据按照train_size进行划分,得到训练集和测试集, random_state确保结果的一致性
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=train_size, random_state=0)
return X_train, y_train, X_test, y_test, df
# #############################################################################################
# 步骤2 todo: 进行朴素贝叶斯分类模型训练与测试、评价
# 由于选取的不同分布的朴素贝叶斯分类器,写成函数形式,便于引用
def naive_bayes_with_diff_distribution(model, model_name, X_train, y_train, X_test, y_test):
# 步骤2.1 todo: 调用不同分布的朴素贝叶斯分类实例,进行训练测试
NB_model = model
NB_model.fit(X_train, y_train)
y_test_predict = NB_model.predict(X_test)
# 步骤2.2 todo: 计算分类评价指标:测试集的准确率accuracy、精确率precision、召回率recall和综合评价指标 F1 值
# 精确率是指分类器预测出的垃圾短信中真的是垃圾短信的比例
# 召回率是所有真的垃圾短信被分类器正确找出来的比例
# F1 值是精确率和召回率的调和均值
acc_test = accuracy_score(y_test, y_test_predict) # 和模型自带的score一致
precision_test = precision_score(y_test, y_test_predict)
recall_test = recall_score(y_test, y_test_predict)
f1score_test = f1_score(y_test, y_test_predict)
# 步骤2.3 todo: 绘制ROC曲线,计算auc,度量分类模型的预测能力
# ROC曲线以召回率为纵轴,以假正例率为横轴,ROC曲线下的面积为AUC值
y_test_predict_proba = NB_model.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test, y_test_predict_proba[:, 1])
roc_auc = auc(false_positive_rate, recall) # 计算auc的值
plt.figure()
plt.title('%s 模型的 ROC-AUC 图' % model_name)
plt.plot(false_positive_rate, recall, 'r', label='AUC = %0.3f' % roc_auc)
plt.legend(loc='best')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('真正例率(召回率)')
plt.xlabel('假正例率')
plt.savefig('./results/ROC_AUC_with_model_{}.png'.format(model_name))
plt.show()
# 步骤2.4 todo: 计算测试集的5折交叉验证的score
cv_test = float(format(cross_val_score(NB_model, X_test, y_test, cv=5).mean(), '.3f'))
# 步骤2.5 todo: 将朴素贝叶斯分类模型计算的相关评价信息存入evaluation中
r = evaluation.shape[0]
evaluation.loc[r] = ['{}分类模型'.format(model_name), acc_test,
precision_test, recall_test, f1score_test, roc_auc, cv_test]
# 步骤2.6 todo: 将评价指标写入csv文件中,便于查看
evaluation.to_csv('./results/evaluation.csv', sep=',', header=True, index=True,
encoding='utf_8_sig') # encoding防止中文乱码
# #############################################################################################
# 程序入口
if __name__ == '__main__':
# 步骤1 todo: 读取数据集,并给出训练集和测试集
train_size = 0.67
X_train, y_train, X_test, y_test, df = data_preprocess(train_size)
# 步骤2 todo: 进行朴素贝叶斯分类模型训练与测试、评价
# 'GaussianNB':Gauss朴素贝叶斯
# 'BernoulliNB':伯努利朴素贝叶斯
# 'MultinomialNB':多项式朴素贝叶斯
models = [GaussianNB(), BernoulliNB(), MultinomialNB()]
model_names = ['GaussianNB', 'BernoulliNB', 'MultinomialNB']
for i, model in enumerate(models):
naive_bayes_with_diff_distribution(model, model_names[i], X_train, y_train, X_test, y_test)
print('模型测试结束!')
源码:阿里云盘地址
补充
一、先验概率:
通过经验来判断事情发生的概率 ,比如说“贝叶斯”的发病率是万分之一,就是先验概率。再比如南方的梅雨季是 6-7 月,就是通过往年的气候总结出来的经验,这个时候下雨的概率就比其他时间高出很多。
二、后验概率:
后验概率就是发生结果之后,推测原因的概率。 比如说某人查出来了患有“贝叶斯”,那么患病的原因可能是 A、B 或 C。患有“贝叶斯”是因为原因 A 的概率就是后验概率。它是属于条件概率的一种。
三、条件概率:
事件 A 在另外一个事件 B 已经发生条件下的发生概率, 表示为 P(A|B),读作“在 B 发生的条件下 A 发生的概率”。比如原因 A 的条件下,患有“贝叶斯”的概率,就是条件概率。
对于离散值的分类,对于连续值的分类
对于离散值我们直接进行概率计算,对于连续的值我们需要将其看成正态分布,然后计算均值和标准差,通过均值和标准差来求解概率。
Sklearn提供了3个朴素贝叶斯算法:
高斯朴素贝叶斯: 特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯: 特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
伯努利朴素贝叶斯: 特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。
TF-IDF值:
词频 TF 计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。
计算公式:词频 TF=单词出现的次数/该文档的总单词数
1
逆向文档频率 IDF ,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF 越大就代表该单词的区分度越大。
计算公式:逆向文档频率 IDF=log(文档总数/该单词出现的文档数+1)
1
TF-IDF 实际上是词频 TF 和逆向文档频率 IDF 的乘积 。这样我们倾向于找到 TF 和 IDF 取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。
例子
假设一个文件夹里一共有 10 篇文档,其中一篇文档有 1000 个单词,“this”这个单词出现 20 次,“bayes”出现了 5 次。“this”在所有文档中均出现过,而“bayes”只在 2 篇文档中出现过。我们来计算一下这两个词语的 TF-IDF 值。
针对“this”,计算 TF-IDF 值:
词频 TF =20/100=0.02
逆向文档频率 IDF = log(10/10+1)=-0.0414
TF-IDF=0.02*(-0.0414)=-8.28e-4。
1
2
3
4
针对“bayes”,计算 TF-IDF 值:
词频 TF =5/1000=0.005
逆向文档频率 IDF = log(10/2+1)=0.5229
TF-IDF=0.005 * 0.5229=2.61e-3。
1
2
3
4
总结:
“bayes”的 TF-IDF 值要大于“this”的 TF-IDF 值。这就说明用“bayes”这个单词做区分比单词“this”要好。