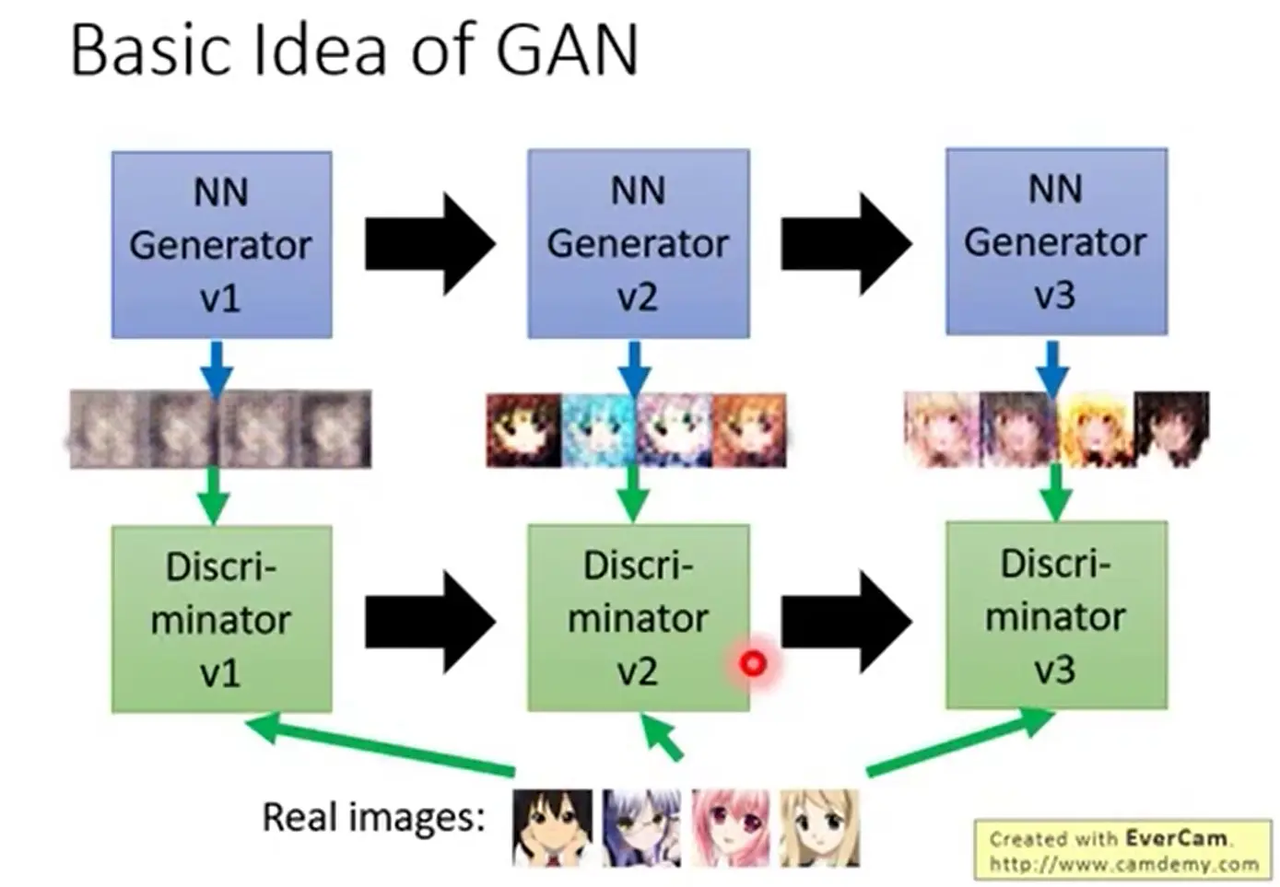
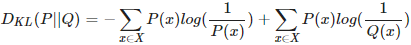GAN 中的训练算法可以表述为如下: 上图中,蓝色的框表示 discriminator 的训练,红色框表示 generator 的训练。输入到 generator 中 的向量
z
z
z$可以从一个分布中随机采样得到。它和数据集中的数据
x
x
x 并没有直接的关系,
x
~
\widetilde{x}
x 表示生成的数据。 下面重点来探讨两个
V
~
\widetilde{V}
V 的函数。需要调整参数使得
V
~
\widetilde{V}
V 最大,因此使用的是梯度上升的方法而不是梯度下降,所以参数更新那里会有一个负号的差距。
对于判别器,当判别器的输入为数据集中的真实图片,那么
D
(
x
i
)
D(x^i)
D(xi) 越大,对应的
V
~
\widetilde{V}
V 将增大,而对于生成器产生的数据
x
~
\widetilde{x}
x 越小,对应的
V
~
\widetilde{V}
V 增大。这样判别器优化的最终结果是对于数据集中的数据,会给出一个很高的分数(接近 1),而对于生成器生成的数据,则给出很低的分数。
对于生成器,优化目标依然是使得
V
~
\widetilde{V}
V 最大,但是需要固定住判别器。这样的训练的最终结果是生成器骗过判别器,使得生成的数据经过判别器输出接近 1。
WGAN 是 GAN 训练优化非常重要的技术, wasserstein 距离也可以用来描述分布之间的差距,但是克服了JS 散度的缺陷。 为了衡量
P
G
P_G
PG和
P
d
a
t
a
P_{data}
Pdata之间的 wessertein 距离,
V
(
G
,
D
)
V(G, D)
V(G,D) 修改为:
V
(
G
,
D
)
=
m
a
x
D
∈
1
−
L
i
p
s
c
h
i
t
z
{
E
x
→
P
d
a
t
a
[
D
(
x
)
]
−
E
x
→
P
G
[
D
(
x
)
]
}
V(G, D) = \mathop{max}\limits_{D \in 1-Lipschitz} \{E_{x \to P_{data}}[D(x)] - E_{x \to P_G}[D(x)] \}
V(G,D)=D∈1−Lipschitzmax{Ex→Pdata[D(x)]−Ex→PG[D(x)]} x 从
P
d
a
t
a
P_{data}
Pdata 取出来时,
D
(
x
)
D(x)
D(x)越大越好;相反当 x 从
P
G
P_G
PG 取出来时,
D
(
x
)
D(x)
D(x)越小越好。
判别器 D 必须是 1-Lipschitz 函数,即这个判别器函数要比较平滑。 所谓的 Lipschitz 函数是指满足如下要求的函数:
∣
∣
f
(
x
1
)
−
f
(
x
2
)
∣
∣
≤
K
∣
∣
x
1
−
x
2
∣
∣
||f(x_1) - f(x_2)|| \leq K ||x_1 - x_2||
∣∣f(x1)−f(x2)∣∣≤K∣∣x1−x2∣∣ 令 K = 1,即为
1
−
L
i
p
s
c
h
i
t
z
1-Lipschitz
1−Lipschitz,表达式为:
∣
∣
f
(
x
1
)
−
f
(
x
2
)
∣
∣
≤
∣
∣
x
1
−
x
2
∣
∣
||f(x_1) - f(x_2)|| \leq ||x_1 - x_2||
∣∣f(x1)−f(x2)∣∣≤∣∣x1−x2∣∣ 这样很显然就限制了函数的变化率,让函数变得更加平滑。
在最原始的 WGAN 论文中,通过限制住判别器的网络的权重的大小来解决这样的问题。 WGAN 相较于原始 GAN 的改动主要如下:
去掉判别器 discriminator 输出的 sigmoid 激活函数;
对于判别器的损失函数,修改为
V
~
=
1
m
∑
i
=
1
m
D
(
x
i
)
−
1
m
∑
i
=
1
m
D
(
x
~
i
)
\widetilde{V} = \frac{1}{m} \sum_{i=1}^m D(x^i) - \frac{1}{m} \sum_{i=1}^m D(\widetilde{x}^i)
V=m1∑i=1mD(xi)−m1∑i=1mD(xi),求梯度上升;
其计算方式如下:
l
n
=
−
w
n
[
y
n
∗
l
o
g
(
x
n
)
+
(
1
−
y
n
)
l
o
g
(
1
−
x
n
)
]
l_n = -w_n [y_n * log(x_n) + (1 - y_n)log(1 - x_n)]
ln=−wn[yn∗log(xn)+(1−yn)log(1−xn)] 其中 n 表示一条数据条目,一个 batch 由 N 个数据条目组成。
w
n
w_n
wn表示第 n 条数据的损失函数权重,一般不考虑,这已经部分的实现了 WGAN 。
训练分为生成器 generator 和判别器 discriminator 的训练。 对于经典的 GAN 模型,训练过程首先固定生成器,训练判别器 k 次;
之后会固定判别器,训练生成器,一般而言生成器仅迭代一次。
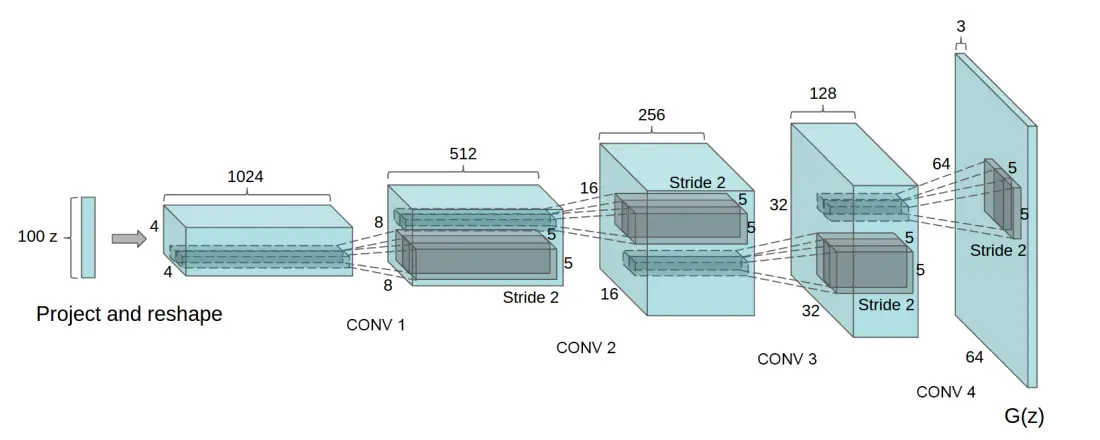
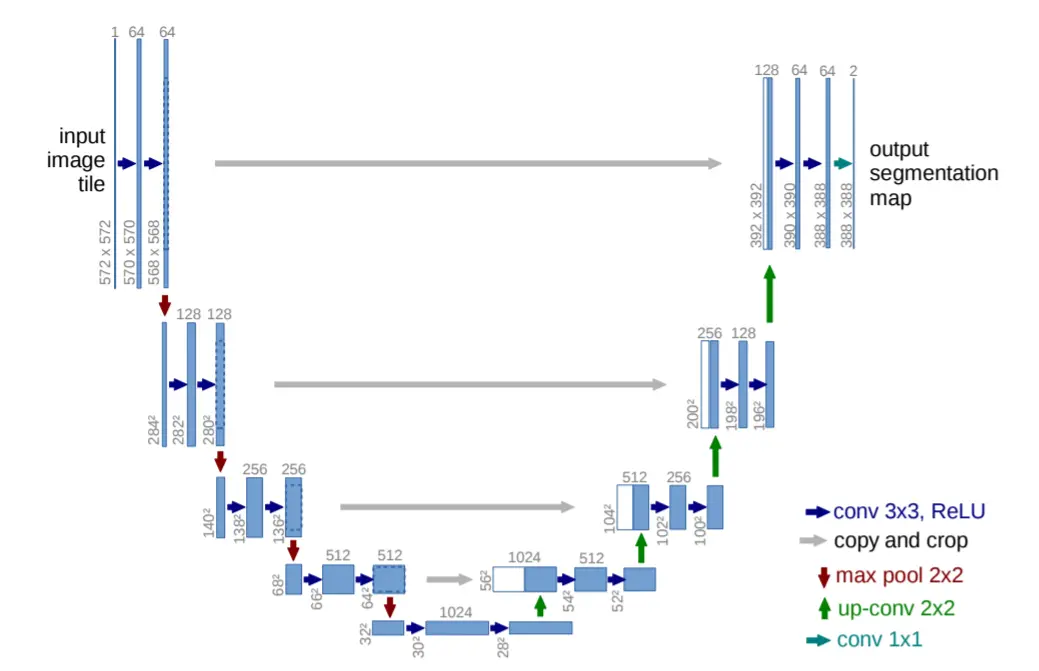
image-to-image模型搭建
Image-to-Image Translation with Conditional Adversarial Network https://arxiv.org/abs/1611.07004 将抽象的简单的房屋示意图转换为真实的房屋图像 生成器搭建:UNet,是一种 U 形的网络,通过卷积下采样和反卷积的上采样形成 U 形的结构,同时增加层之间的 skip 操作。 为了搭建模型的方便,首先对常用的 conv-batchnorm-relu 以及 transconv-batchnorm-relu 做了简单的一步封装,即下方的 ConvBnReLU 类和 TransConvBnReLU 类。