Abstract:
Due to the diversity and variability of Chinese syntax and semantics, accurately identifying and distinguishing individual emotions from online texts is challenging. To overcome this limitation, we incorporate a new source of individual sentiment, emojis, which contain thousands of graphic symbols and are increasingly being used for expressing emotion in online conversations. We examined popular sentiment analysis algorithms, including rule-based and classification algorithms, to evaluate the impact of supplementing emojis as additional features to improve the algorithm performance. Emojis were also translated into corresponding sentiment words when constructing features for comparison with those directly generated from emoji label words. In addition, considering different functions of emojis in texts, we classified all posts in the dataset by their emoji usage and examined the changes in algorithm performance. We found that emojis are effective as expanding features for improving the accuracy of sentiment analysis algorithms, and the algorithm performance can be further increased by taking different emoji usages into consideration. In this study, we developed an improved emoji-embedding model based on Bi-LSTM (namely, CEmo-LSTM), which achieves the highest accuracy (around 0.95) when analyzing online Chinese texts. We applied the CEmo-LSTM algorithm to a large dataset collected from Weibo from December 1, 2019 to March 20, 2020 to understand the sentiment evolution of online users during the COVID-19 pandemic. We found that the pandemic remarkably impacted individual sentiments and caused more passive emotions (e.g., horror and sadness). Our novel emoji-embedding algorithm creatively combined emojis as well as emoji usage with the sentiment analysis model and can handle emotion mining tasks more effectively and efficiently.
由于汉语句法和语义的多样性和可变性,准确识别和区分网络文本中的个人情感是一项挑战。为了克服这一限制,我们加入了一种新的个人情感来源,表情符号,它包含数千个图形符号,越来越多地被用于在线对话中表达情感。我们研究了流行的情感分析算法,包括基于规则的算法和分类算法,以评估补充表情符号作为额外特征对提高算法性能的影响。在构造特征以与表情符号标签词直接生成的特征进行比较时,表情符号也被翻译成相应的情感词。此外,考虑到表情符号在文本中的不同功能,我们根据表情符号的使用情况对数据集中的所有帖子进行分类,并检查算法性能的变化。我们发现表情符号作为扩展特征对于提高情感分析算法的准确性是有效的,并且通过考虑不同表情符号的使用可以进一步提高算法的性能。在本研究中,我们开发了一种基于Bi-LSTM(即CEmo-LSTM)的改进表情嵌入模型,该模型在分析在线中文文本时达到了最高的准确率(约0.95)。我们将CEmo LSTM算法应用于2019年12月1日至2020年3月20日从微博收集的一个大型数据集,以了解2019冠状病毒疾病大流行期间在线用户的情绪演变。我们发现,这种流行病显著影响了个人情绪,并导致更多的消极情绪(例如,恐惧和悲伤)。我们的新表情嵌入算法创造性地将表情以及表情的使用与情感分析模型相结合,可以更有效地处理情感挖掘任务。
Main Work:
However, these studies mainly considered emojis as one feature and did not research the sentiment effects of emojis on the whole texts. Little attention has been given to the SA model combined with different emoji usages in texts.
In this study, we proposed an emoji-embedding architecture named CEmo-LSTM to improve the accuracy of sentiment identification and classification in SA tasks. We further evaluated the benefits of introducing emojis to the accuracy of SA in both the traditional rule-based and supervised learning algorithms. Additionally, the most effective approach for embedding emojis in SA algorithms was examined. We compared the performance of the CEmo-LSTM model with that of other mainstream SA models in different experimental settings. Finally, by collecting all posts and embedded emojis published by users on Weibo during the COVID-19 outbreak, we utilized CEmo-LSTM to analyze the sentiment evolution of online users and measured the impact of the COVID-19 pandemic on individual moods. To the best of our knowledge, this is the first study that comprehensively evaluates the effectiveness of introducing emoji usage into SA algorithms.
然而,这些研究主要将表情符号作为一个特征,而没有研究表情符号对整个文本的情感影响。很少有人关注SA模型与文本中不同表情符号的结合。
在本研究中,我们提出了一种表情符号嵌入架构CEmo-LSTM,以提高SA任务中情感识别和分类的准确性。我们进一步评估了在传统的基于规则和监督学习算法中引入表情符号对SA准确性的好处。此外,还研究了在SA算法中嵌入表情符号的最有效的ap方法。我们比较了CEmo-LSTM模型与其他主流SA模型在不同实验环境下的性能。最后,通过收集2019冠状病毒疾病爆发期间用户在微博上发布的所有帖子和嵌入表情,我们利用CEmo-LSTM分析了在线用户的情绪演变,并衡量了2019冠状病毒疾病疫情对个人情绪的影响。据我们所知,这是第一次全面评估将表情符号使用引入SA算法的有效性的研究。
Research Process:
- Data collection: We collected all data from Weibo that were posted publicly by users located in Wuhan (the capital of the Hubei province in China), including microblog text, posting time, author ID, and gender, from December 1, 2019 to March 20, 2020. By comparing the sentiments in posts published by Wuhan users before and after the COVID-19 outbreak, we can analyze the sentiment evolution of online users and further explore the impact of COVID-19 on individual moods. Overall, 38,183,194 microblog posts from 2,239,472 unique users were collected. We found that emotion tokens (i.e., emoji characters) were commonly used in Weibo posts. There were 15,609,843 posts containing emoji symbols, accounting for 40.88% of the total posts. In addition, 1,279,828 users used emojis at least once, accounting for 57.15% of all unique users.
数据收集:从2019年12月1日至2020年3月20日,我们从位于武汉(中国湖北省省会)的用户公开发布的微博上收集了所有数据,包括微博文本、发布时间、作者ID和性别。通过比较2019冠状病毒疾病爆发前后武汉用户发表的帖子中的情绪,我们可以分析网络用户的情绪演变,进一步探讨2019冠状病毒疾病对个人情绪的影响。总体而言,共收集了2239472名独立用户的38183194篇微博帖子。我们发现,情感标记(即表情符号)在微博帖子中普遍使用。共有15609843条含有表情符号的帖子,占帖子总数的40.88%。此外,1279828名用户至少使用过一次表情符号,占所有唯一用户的57.15%。
- Annotation: Although there have been some annotated corpora on Chinese and English for SA [23,24], they do not explicitly model the interaction between emojis and text. To fill in this gap, we manually annotated a Chinese microblog corpus. A total of 10 annotators (graduate students majoring in data analytics) were engaged to label the corpus, which consists of 10,000 randomly selected microblog posts. The sentiment polarities of the posts were manually classified as positive, negative, and neutral, denoted by 1, -1, and 0, respectively (Table 1). The annotators were asked to label each post by considering both the plain text and embedded emojis.
As there are several principal functions for which emojis are used (e.g., sentiment expression, sentiment enhancement, and sentiment modification) [25], the emoji usage of each post containing emojis was also annotated. Specifically, the emoji usage of each post was classified into three categories, strengthening, reversing (or revising), and uncertain, labelled by 1, -1, and 0, respectively, indicating whether the sentiment of the embedded emojis was consistent (1) or inconsistent (-1) with the sentiment of the text-only post (Table 2). The label 0 was used to denote when the effect of emojis in the post could not be confidently determined. We found that most emojis embedded in the posts were used to strengthen and clarify the sentiment of the original texts, accounting for approximately 73.6% of all posts with emojis included in the corpus. Finally, all 10,000 microblog posts were labelled with their sentiment polarities, of which 5499 posts containing emojis were also annotated with their emoji usages.
注释:尽管有一些关于SA的中英文注释语料库[23,24],但它们并没有明确地模拟表情符号和文本之间的交互。为了填补这一空白,我们手动注释了一个中文微博语料库。共有10名注释员(数据分析硕士研究生)参与了语料库的标注工作,语料库由10000条随机选择的微博帖子组成。这些帖子的情感极性被手动分为积极、消极和中性,分别用1、-1和0表示(表1)。注释者被要求通过考虑纯文本和嵌入表情来标记每篇文章。
由于使用表情符号有几个主要功能(例如,情感表达、情感增强和情感修改)[25],因此还对每个包含表情符号的帖子的表情符号用法进行了注释。具体而言,每个帖子的表情符号用法分为三类,强化、反转(或修订)和不确定,分别用1、-1和0标记,表明嵌入表情符号的情绪与纯文本帖子的情绪是一致的(1)还是不一致的(-1)(表2)。标签0用于在无法确定帖子中表情符号的效果时进行注释。我们发现,大多数嵌入在帖子中的表情符号被用来加强和澄清原文的情感,约占语料库中包含表情符号的所有帖子的73.6%。最后,所有10000条微博帖子都贴上了情感极性标签,其中5499条包含表情符号的帖子也标注了表情符号的用法。
- CEmo-LSTM model:
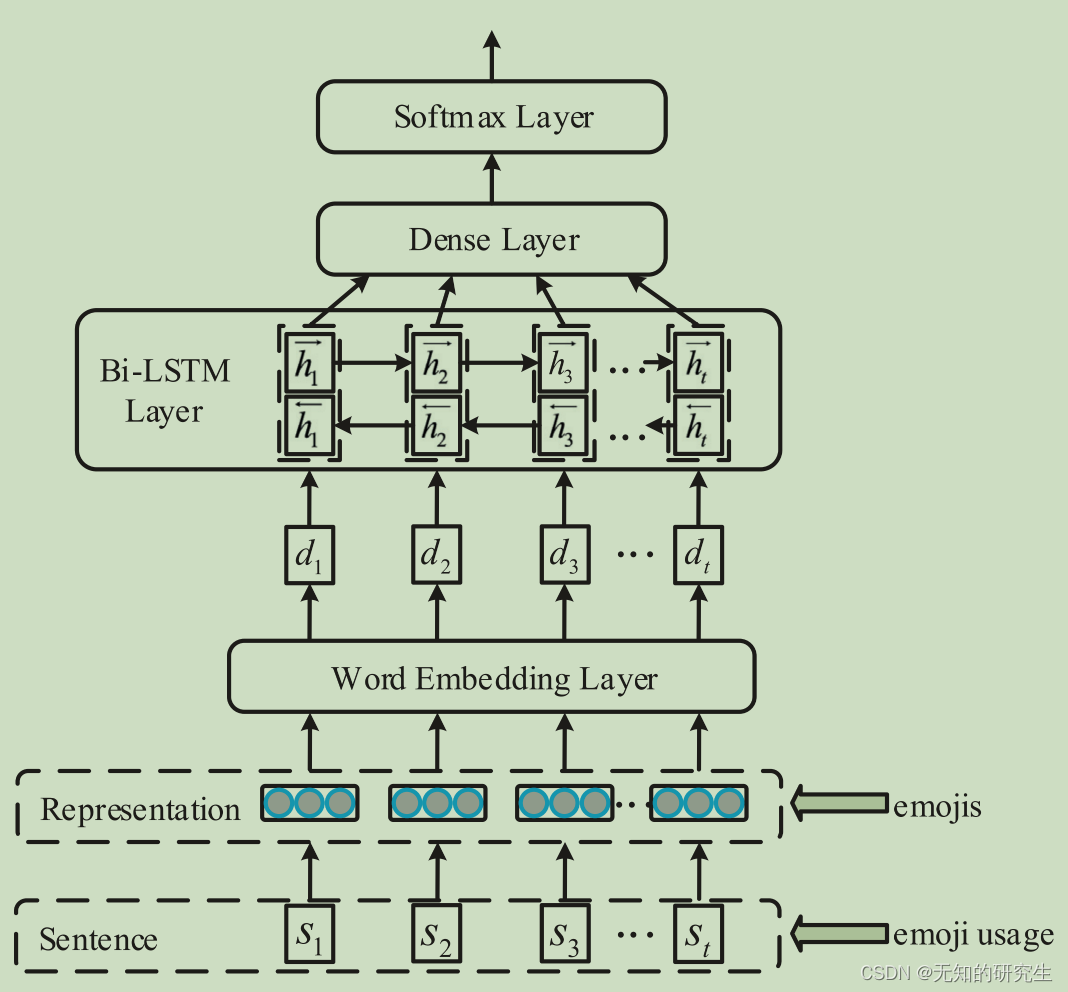
As illustrated in Figure 1, our model includes the input sentence, word (emoji) representation, word embedding layer, Bi-LSTM layer, dropout layer, and a softmax layer. Given an input post
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)