前言
NVIDIA 显卡驱动是为了确保 NVIDIA 显卡能够正确运行而开发的软件。显卡驱动负责与操作系统通信,管理显卡的各种功能,并提供性能优化和兼容性保证。安装适用于特定显卡型号和操作系统版本的最新驱动程序是确保显卡能够正常工作的重要步骤。
CUDA 是 NVIDIA 推出的一种并行计算平台和编程模型。它充分利用 NVIDIA 显卡的并行处理能力,使开发人员能够通过编写并行计算任务来加速各种计算工作。CUDA 提供了一组编程接口和工具,使开发人员能够使用标准编程语言(如C/C++、Python)来开发并行计算应用程序。
CUDA 依赖于 NVIDIA 显卡驱动的支持。安装正确的显卡驱动是为了确保 CUDA 开发平台能够顺利工作。通过 CUDA,开发人员可以利用 NVIDIA 显卡的强大算力来加速计算任务,从而提高性能和效率。
因此,NVIDIA 显卡驱动和 CUDA 是相辅相成的,只有在正确安装并配置了适用的显卡驱动程序后,才能利用 CUDA 进行并行计算任务的开发和加速。
1、显卡驱动的安装及卸载
查看独立显卡驱动支持及其支持的最高
cuda版本
:
nvidia-smi
若无输出表示驱动未安装,查询可用的驱动:
ubuntu-drivers devices
上述命令很可能什么都不显示,添加官方 ppa 的源,更新源后即可查询可用驱动:
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
ubuntu-drivers devices
安装
第一种安装显卡驱动的方式(通过命令行安装)
自动安装推荐的驱动:
sudo ubuntu-drivers autoinstall
指定版本安装:
sudo apt install nvidia-driver-515 #指定安装515版本
第二种安装显卡驱动的方式(通过界面安装)
在ubuntu20.04 安装NVIDIA驱动比较简单,打开系统设置->软件和更新->附加驱动->选择NVIDIA驱动->应用更改,该界面会自动根据电脑上的GPU显示推荐的NVIDIA显卡驱动,选择需要的版本安装即可。

卸载
查看当前驱动、卸载驱动:
dpkg -l | grep nvidia #查看当前驱动
sudo apt-get purge nvidia* #卸载当前驱动
sudo apt autoremove #清理链接
2、安装Cuda
查看是否安装了cuda:
nvcc -V
输入nvcc-V后,若显示:Command 'nvcc' not found, but can be installed with:sudo apt install nvidia-cuda-toolkit,
注意:千万不能使用sudo apt install nvidia-cuda-toolkit。
查看CUDA的位置:cd /usr/local,如果该目录下有CUDA文件夹或软链,表示已经安装了cuda,只需要添加cuda相关的环境变量即可。
打开、编辑环境变量的配置文件:
vim ~/.bashrc
在文件末尾添加:
# cuda
export LD_LIBRARY_PATH=/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
然后按:wq保存退出编辑模式。
刷新~/.bashrc文件使其生效:
source ~/.bashrc
重新使用nvcc命令查看CUDA版本:nvcc -V。
安装cuda的步骤
点击网址
https://developer.nvidia.com/cuda-toolkit-archive
,选择需要的CUDA下载。选择runfile(local),并使用生成的指令进行下载和安装。

wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
sudo sh cuda_11.1.1_455.32.00_linux.run
若第1步提示Existing package manager installation of the driver found. It is strongly recommended that you remove this before continuing.选择continue,在下一步中点击回车键去除driver项,之后选择install。

安装完成后,显示如下:
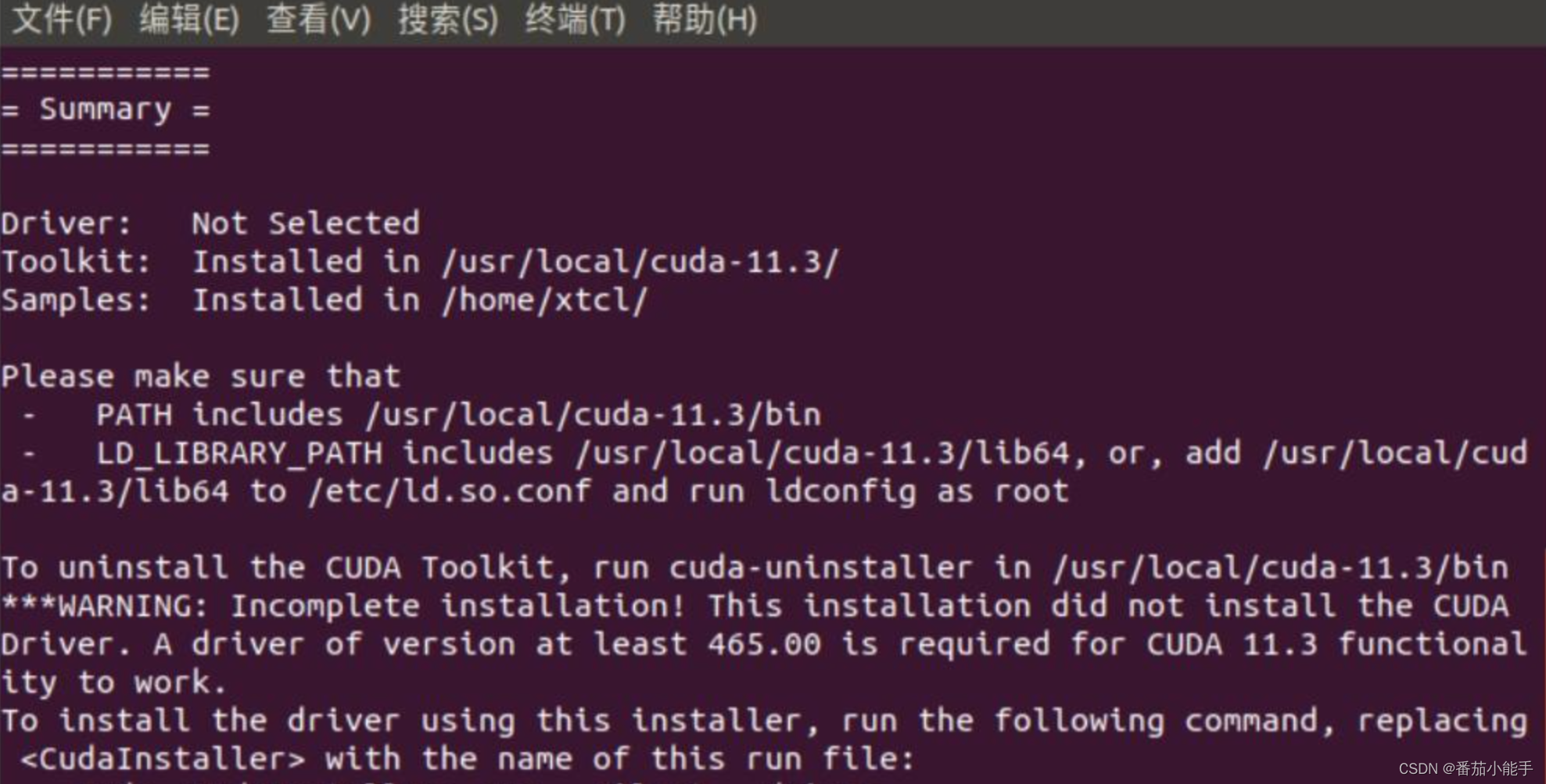
在~/.bashrc文件中添加如下环境变量:
export PATH=/usr/local/cuda-11.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
验证是否安装成功:
nvcc -V
完毕!!!
文章到此就结束了,下篇文章将的的如何安装cuda对应版本的cudnn,因为安装cudnn适合99%的linux系统,所以单独拿出来讲解,cudnn详细安装讲解请看下篇文章:
Linux系统配置深度学习环境之cudnn安装