前言
本博文主要对论文中提到的图构造方法进行梳理,论文自己提出的模型并未介绍,感兴趣的可以阅读原文
摘要
基于图的半监督学习GSSL主要包含两个过程:图的构建和标签推测。传统的GSSL中这两个过程是完全独立的,一旦图结构构建完成,标签推断的结果也不再改变。因此,图的结构直接影响GSSL的效果。传统的图构造方法对数据的分布做了一个具体的假设,导致图的质量严重依赖于这些假设的正确性。因此,对于传统图构造方法很难应用再复杂多样的数据分布上。本文提出了一个框架叫做通过动态地提升图质量的图半监督学习。在本方法中,图的构建是基于多个聚类结果的加权融合,并且把标签推断也整合进一个统一的框架达到相互引导,动态提升的效果。
引言
GSSL方法主要可以分为两个角度即标签推测和图的构建。标签推测主要关注于如何根据有标签的样本和相似样本提供的信息在图上进行标签学习。而GSSL成功的关键在于构建高质量的图而非好的标签推测算法。GSSL核心的假设是图中相似的样本应该有相同的标签。根据这个标准,如果样本的相似程度与真实标签一致,那么未标记的样本便可以被正确预测。相反,如果相似性与真实标签相反则会得到错误的结果。因此,图的质量对于GSSL方法的表现至关重要。
由于没有可用的评价方法来度量图的质量,图的质量一般是通过标签推测的准确率来间接度量的。这是一种事后的验证方法,对于图的构建没有任何帮助。这也就是构建高质量图的难点所在。那么问题就来了,为什么不让图的构建和标签推断彼此指导达到共赢呢?在本文中,我们将图的构建和标签推测放入一个优化模型中来解决问题。
我们需要先大致重温一下现有的图构造方法。图构造方法的基本任务就是度量样本之间的相似性。根据相似度的计算方法,现有图构造方法可以分为两类
基于距离的方法
基于距离的构图方法通过计算样本之间的距离来度量节点间的相似度。直观来讲,距离越小,相似度越高。常见的方法有基于欧式距离的方法如KNN graph和e-ball neighborhood图。在KNN图中,当节点的度差异非常大时,图的质量也会下降。为了克服该问题,b-matching图通过把图中每个节点的度约束为b来构图。除了使用欧式距离外,基于流型假设的构图方法通过测地距离来度量样本之间的相似性。
一些工作通过样本标签提供的监督信息来构图。给有标记的节点更多边可以使标记信息高效的传递到无标记的样本中。
基于距离的方法需要选择合适的度量方法,同样构图中的一些参数也是非常重要的图邻居数量,距离阈值等。并且一旦图构造完成后,图的结构会固定下来,不能自适应处理多种数据分布。
基于数据表示的方法
基于数据表示的构图方法通过样本之间的表示系数来建模样本的相似度。样本之间的表示系数通过一个数据表示模型来得到。L1 graph使用稀疏表示学到的表示系数的绝对值来度量样本之间的相似度来构建图。因为这类方法是单独优化每个样本的表示系数的,因此表示系数矩阵无法捕获数据分布的全局信息。而有的工作通过把L1 norm和nuclear norm正则项共同应用在所有样本的表示系数矩阵中同时捕获局部和全局信息。
基于数据表示的方法可以学习邻接结构和边的权重,对数据噪声有一定的鲁棒性。但是当数据分布不能满足子空间假设时,这种方法无法正确反映数据分布,无法保证模型结果。
可以看到,基于距离的方法和基于数据表示系数的方法都严重依赖于对应的假设。如果假设不对,两种方法都无法正确捕获与数据分布一致的相似性,导致效果下降。但是现实中数据分布复杂且多样,很难基于特定的假设自适应的度量样本间真实的相似度。因此,要想构建高质量的图,需要设计一个图构造方法可以降低复杂多样的数据分布的影响同时还能自适应的挖掘潜在的数据分布。
考虑到以上需求,我们将目标转向聚类集成,通过将多个聚类结果整合到一个最终的聚类结果中可以获得一个更加鲁棒的聚类结果。在大量的聚类集成方法中,基于相似度的方法最为灵活高效。通过融合多个基础的簇来构建一个简单的相似度矩阵。该方法高效的原因在于不同类型的簇互补了不同类型的数据分布,通过融合多个不同分的聚类结果可以获得一个鲁棒的相似度计算方法,提升最终聚类的鲁棒性。
基于此,我们是设计了一个图构造方法通过加权融合多个距离结果来度量样本之间的相似性。首先,不同的聚类算法获取多个聚类结果,捕获复杂多样的数据分布。然后,加权融合聚类结果用于构图,其中权重会根据样本标签和标签推测的结果提供的“必须连接”和“不能连接”约束条件动态的调整。在整个学习过程中,图的动态构建和标签推断过程交替的优化,可以动态的提升构图质量。
图构造方法
1. Nearest neighbor graph
0-1kNN graph和weighted kNN graph是最常见方法,其中边权重矩阵W定义为
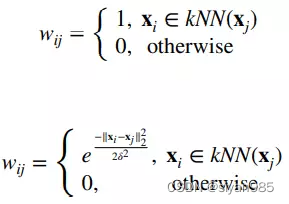
当然还有其他的变体如e-ball nearest neighbor graph,mutual kNN graph等。
2. b-matching graph
为了避免在kNN graph中有的节点度很大而有的却非常小,b-matching通过把每个节点的度约束为b。对应优化过程如下,该算法可以通过loopy belief propagation算法高效解决。
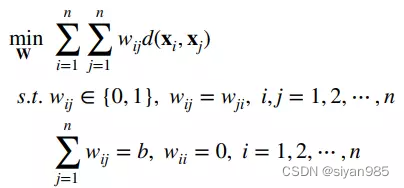
3. Linear neighbor graph
不同于直接使用距离来建模建模样本之间的相似度,一些工作采用了线性的基于表示的相似度计算方法。具体来说,对于样本xi,首先计算出它k个最近邻的邻居kNN(xi)。然后通过kNN(xi)的凸组合重构样本xi。最终,组合系数视作节点之间边的权重。
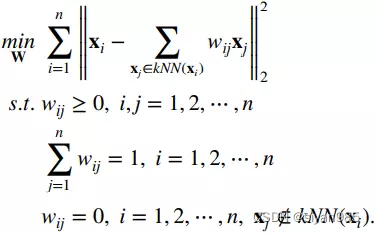
4. l1 graph
为了挖掘数据的子空间,l1 graph同时学习邻接结构和边的权重。样本之间的相似度通过稀疏表示学到的线性组合系数的绝对值来表示。具体来说,第i个样本通过剩余的其他样本来重建。其中I为重建样本xi中噪声的偏置项。
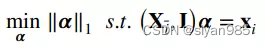
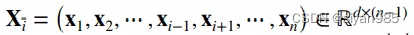
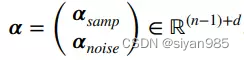
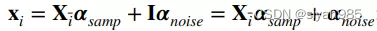
5. LRR graph and SSLRR graph
低阶表示是一种鲁棒的子空间重建方法。不同于稀疏表示模型为每个样本单独学习表示系数。低阶表示通过给表示系数矩阵上应用低阶正则项可以更好的捕获数据的全局结构。||*||*用于估计矩阵的阶,因此,低阶表示模型可以表示为
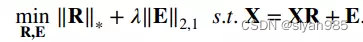
在获得最优表示矩阵R后,节点i和j之间的边的权重可以表示为

为了更好利用监督信息提升图的质量,一个半监督图构造方法SSLRR通过把“不能连接”约束加入低阶表示模型中使不同类别样本的表示系数为0.
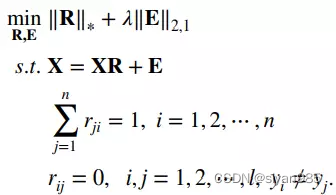
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)