摘自:https://mp.weixin.qq.com/s/OZnnuA31tEaVt0vnDOy5hQ
作为SLAM中最常用的闭环检测方法,视觉词袋模型技术详解来了
原创 小翼 飞思实验室 今天
基于语义的图像分类研究是一个涉及模式识别、机器学习、计算机视觉及图像处理等多个研究领域的交叉研究方向,并受到学术界的广泛关注。近几年来,国际顶级学术期刊及顶级学术会议都发表了大量关于图像语义分类的研究成果,其中,以视觉词袋模型(Bag ofVisual Words, BoVW)和支持向量机为关键技术的图像分类方法取得的性能最为突出,今天先就视觉词袋模型这块进行详细分享。
首先来看看,基于视觉词袋模型的图像分类系统由哪些结构组成:
2003年,Sivic等提出了视觉词袋模型。该模型将词袋模型(Bag of Words, BoW)引入到了计算机视觉领域,取得了巨大成功。基于视觉词袋模型的图像分类系统主要由四个部分组成,如图1所示,分别为:图像底层特征提取、视觉词典生成、视觉词汇特征构建和分类器。由图1可知,要完成图像分类,首先需要生成一个规模适当的视觉词典,又称为视觉码本;然后,对于一幅待处理图像,提取出相应的底层特征后,依据视觉词典来构建该图像的视觉词汇特征;最后,将该视觉词汇特征输入已训练好的分类器中,得到该图像类别。
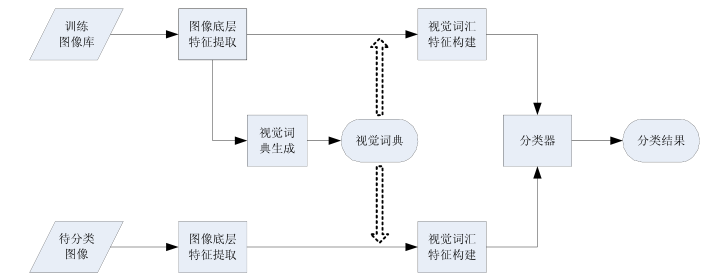
图1基于视觉词袋模型的图像分类系统结构
第一:图像底层特征提取
一幅图像的内容是由其所有像素点的值来表达的,图像底层特征就是通过一些算子从图像,像素值中提取出能够表达图像内容信息的统计量,通常为高维向量。图像底层特征可以用来帮助表达图像内容,分析图像特性及完成基于视觉信息的其它计算处理工作。特征提取是实现图像分类的重要环节,提取的特征能否反映图像的本质属性信息对分类系统的性能有着决定性的影响。
图像底层特征需要考虑四个原则:区分能力、描述能力、计算复杂度以及存储空间需求。总的来说,底层特征可以分为全局特征和局部特征两大类。全局特征指的是作用域为整幅图像的统计量,通常用来代表一幅图像整体的色调、亮度、纹理特征等信息。而局部特征指的是作用域为图像局部区域的统计量,通常用来描述图像中信息丰富区域的特性,可用于图像中物体、目标的检测和定位。下面分别对图像的全局特征和局部特征进行简单的介绍。
1.全局特征
图像全局特征的研究起步较早,技术相对比较成熟,主要包括颜色、纹理、形状等特征,通常用于基于内容的图像检索(Content-Based Image Retrieval, CBIR)。
(1)颜色特征
颜色特征作为最早被开发利用的视觉特征,被广泛用于图像检索中。与其它全局视觉特征相比,颜色特征具有特征提取和相似度计算简便的特点,并且对图像的尺度、方向、视角变化不敏感,具有较强的稳健性。提取图像的颜色特征,首先需要选择合适的颜色色彩空间,较常用的颜色空间有RGB、HSV、YCrCb、HMMD等。全局颜色特征主要包括颜色直方图、颜色矩、 颜色集、颜色熵等。全局颜色特征无法表达图像颜色的空间分布信息,忽略了颜色在二维空间中的分布特性。因此,为了在图像特征中加入图像颜色的空间位置信息,一些新的颜色特征也被研究和应用,主要有颜色聚合向量、颜色相关图、颜色空间分布熵、马尔科夫随机特征等。
(2)纹理特征
纹理特征是所有物体表面共有的内在特性,是一种不依赖于颜色或亮度的反映图像同质现象的视觉特征。纹理特征包含了物体表面结构组织排列的重要信息,其表现为图像上灰度或颜色分布的规律性。早在二十世纪七十年代,Tamura 等就从视觉感知心理学研究出发,提出了纹理特征的表达。Tamura 纹理特征共包含6个分量:粗糙度、对比度、方向度、线性度、规整度和粗略度,分别对应心理学角度上的6种属性。Haralick 等利用共生矩阵描述图像纹理特征的方法,从数学角度研究了图像中灰度级的空间依赖性并采用矩阵的形式记录这种依赖性的统计信息。此外,Gabor 过滤作为一种纹理特征,能够在最大程度上减少空间和频率的不确定性,同时还能有效地检测出图像中不同方向、角度上的边缘和线条。
(3)形状特征
形状特征以对图像中物体和区域的分割为基础,是图像表达和图像理解中的重要特征。直观上,人们对物体形状的变换、旋转和缩放不敏感,所以,形状特征也应具有对应的不变性。图像形状特征大致分为两:区域特征和轮廓特征,前者基于整个形状区域而后者则利用物体的边界。比较典型的形状特征主要包括傅立叶形状描述符、形状无关矩等。
2.局部特征
全局特征计算简单快捷,但存在明显的缺点:只考虑了图像的全局统计信息,而忽略了图像的局部相关信息。有文献指出,人类视觉系统通常是将物体分成许多区域,并综合各个区域的局部信息加以识别判断。与全局特征相比,局部特征在图像噪声干扰较大、背景复杂、存在重叠及物体形变等情况下仍能保持良好的性能,逐渐成为近年来的研究热点。常用的局部特征,都能够对图像的平移、亮度、旋转和尺度等的变化保持一定的不变性,被广泛应用于图像分类检索、图像配准、目标识别等领域。
图像局部特征提取一般包含两个步骤:局部特征点检测和局部特征描述。局部特征点检测,是通过采用适当的数学算子检测图像中梯度分布极值点所在的位置或区域。相关研究表明,这样的极值点对应的区域包含的视觉信息比较丰富,其对应的特征向量也具有很强的区分能力和描述能力。目前,主要的局部特征点检测算子有: DoG算子、 MSER算子、Hrris-Affine算子和Hessian-Affine算子。确定局部特征点对应的局部区域后,需要生成有效的局部特征描述,通常为高维向量。
现阶段,主流的局部特征主要有形状上下文(Shape Contexts) 、尺度不变特征变换( Scale Invariant Feature Transform, SIFT)、PCA-SIFT、 梯度位置方向直方图( Gradient Location and Orientation Histogram, GLOH) 等。为深入对比分析局部特征性能,Mikolajczyk等对几种常用的局部特征进行了性能测试,结果表明SIFT特征及在其基础上得到的GLOH特征的性能最突出。
SIFT特征最初由Lowe教授于1999年提出,后在2004年Lowe教授又对其进行了进一步完善,是当前最常用的局部特征。SIFT特征能够有效描述图像的局部区域信息,对图像旋转、亮度变化和尺度变化具有不变性,对仿射变化、视角变化和噪声也具有较强的鲁棒性。由于性能突出,SIFT特征被广泛用于图像分类、场景识别和目标检测等计算机视觉领域。
第二:视觉词典生成
局部特征能够表征图像的底层视觉特性,被大量用于图像内容分析中。但是,图像局部特征大多位于高维空间,不便于进行存储和后续计算。此外,高维向量通常还面临稀疏、噪声等“维数灾难”问题,导致在低维空间表现良好的算法到了高维空间其性能急剧恶化。因此,需要将图像的高维局部特征映射到低维空间,以便于存储、索引和计算。将大量局部特征映射到低维空间,得到局部特征对应的编码,这些编码就称为视觉单词,所有的视觉单词构成视觉词典。
视觉词典的优劣直接影响着系统的性能表现,如何构建区分性好、表达能力强的视觉词典,成为近些年来基于视觉词袋模型的图像分类研究的重点。根据视觉词典生成过程中是否利用训练集中已知类别标注等信息,可将视觉词典生成方式分为两类:无监督生成视觉词典和有监督生成视觉词典。
1.无监督生成视觉词典
无监督生成视觉词典,通常是利用成熟的主成分分析,无监督聚类、哈希映射等方法将局部特征集映射为视觉单词集合,得到视觉词典。无监督方法不需要用到局部特征的类别、标注等信息,省略了复杂的学习过程,视觉词典生成速度较快。
K-Means算法作为一种最常用的聚类方法,因其直观易懂,被广泛用于对图像局部特征进行聚类,生成视觉词典。早在2003年,视觉词袋模型的提出者就是采用K-Means聚类算法对局部特征集进行聚类得到视觉词典。针对传统基于K-Means聚类生成视觉词典存在的一些问题,研究人员提出了一系列改进方案。
为减弱局部特征高维度和稀疏性对K-Means聚类效果的影响,Zhong等提出了球形K-Means聚类算法( Spherical K-Means)。Bolovinou 等进一步验证了采用该聚类方法生成的视觉词典,其表达能力得到了增强。
为提高K-Means聚类收敛速度, Philbin提出了近似K-Means聚类算法( ApproximateK-Means, AKM),并将其应用到目标检索领域。Wang 等提出了快速近似K-Means聚类算法(Fast Approximate K-Means, F-AKM),通过有效识别簇之间交界处的数据点,减少了每轮迭代的计算量,进一步加快了聚类收敛速度,提高了生成视觉词典的效率。
此外,考虑到常用的局部特征,如SIFT 特征,实质上都是高维直方图,为提高高维直方图相似性度量的有效性, Wu等提出了一种基于直方图相交核( Histogram IntersectionKernel, HIK) 的K-Means聚类方法生成视觉词典,并在目标识别实验中验证了该视觉词典的良好性能。
由于传统K-Means聚类方法得到的视觉词典内部没有任何索引结构,查找特定视觉单词的复杂度较高,有研究者采用分层K-Means聚类算法( Hierarchical K-Means, HKM)生成词汇树( Vocabulary Tree)提高了视觉单词的查找速度。
除了K-Means及其改进算法,也有研究者采用高斯混合模型(Gaussian Mixture ModelGMM)生成视觉词典。Avithis 等提出一种近似高斯混合模型(Approximate GaussianMixtures)并将其用于构建大规模视觉词典。该方法不但计算复杂度低,而且图像检索实验也表明采用该方法生成的视觉词典具备良好的表达能力。
除了聚类方法,哈希映射方法也常被用来生成视觉词典。Mu等借助位置敏感哈希(Locality Sensitive Hashing, LSH) 对局部特征进行降维映射,生成了一组随机化位置敏感词典(Randomized Locality Sensitive Vocabularies, RLSV)。与K-Means方法相比,该方法计算复杂度低,能够有效减弱“维数灾难”带来的问题。
2.有监督生成视觉词典
为进一步提高视觉词典的表达能力,越来越多的研究者开始探讨有监督生成视觉词典的方法。
Moosmann等借鉴极端随机树( Extremely,Randomized Trees, ERT)和随机森林(Random Forests, RF)算法思想,构建了一组随机聚类森林( Randomized ClusteringForests)作为视觉词典。该视觉词典具有规模大,视觉单词区分能力强的特点,能够很好地用来描述图像内容。Lopez-Sastrel等提出了一种新的聚类质量评价准则来评价视觉单词的语义代表能力,并在聚类过程中引入局部特征的类别信息,大幅度提高了视觉词典的区分能力和语义表达能力。Kontschieder等提出将训练集图像中物体标签的拓扑信息整合到随机森林的训练当中,有效地提高了视觉词典的区分能力,改善了图像标注的性能。此外,考虑到来自相同类别目标的视觉特征之间具有一定的相关性,Zhou 等提出采用Fisher判别准则对视觉词典的生成过程进行监督,增强了特定视觉单词对相应类别目标的表达能力,提高了目标识别的准确率。上述有监督生成视觉词典的方法,都利用了局部特征的类别信息,并设定相应准则指导视觉词典的生成过程,达到提高视觉词典表达能力的目的。
除了利用局部特征的类别信息,有的视觉词典生成方法进一步利用了局部特征间的相关性信息。有专家团队将图像块在特征域的相似性与空间域上的上下文语义共生关系相结合,构造出语义含义更明确的视觉单词,提高了视觉词典性能,改善了场景分类的效果。
Zhou等采用了空间约束的分层模糊k-Mcans ( Hierarchical ruzzy k-Means with Spatial Constraints, FCM-HS)方法将SIFT特征的空间上下文信息植入到词汇树的生成过程中,提高了聚类准确度,有效地减弱了视觉单词的语义模糊度。Yang 等提出了一种有监督的EM迭代算法,将局部特征的空间上下文信息作为边信息(Side Information),对聚类生成视觉词典的过程进行约束,提高了视觉单词的语义区分能力。
第三:视觉词汇特征构建
依据生成的视觉词典,可以对图像底层特征进行编码,将图像的底层特征表示转化为视觉单词表示,构建图像的视觉词汇特征。
传统的视觉词袋模型采用矢量量化( Vector Quantization)对底层特征编码,从而构建图像的视觉词汇直方图。矢量量化的具体过程为:对于待编码的底层特征,计算它与视觉词典中各个视觉单词间的距离,找到与其相距最近的视觉单词代替这个底层特征。矢量量化的编码方式简单易懂,也最容易被接受,因为人们通常认为相距越近的特征越相似。对图像中所有底层特征进行矢量量化,得到每个底层特征对应的视觉单词,再统计图像中每个视觉单词出现的频次就可以得到视觉词汇直方图来表示该图像。
Philbin等提出采用软分配方法( Soft Assignment, SA)构建视觉词汇直方图,将SIFT特征分配给多个与其相距较近的视觉单词。该方法能够有效地减小由量化误差引起的噪声,在一定程度上减弱了视觉单词同义性和歧义性的负面影响。Jegou等应用汉明嵌入(Hamming Embedding, HE)记录SIFT特征在特征空间的粗略位置信息,弥补了传统矢量量化方法的不足,有效提高了SIFT特征与视觉单词的匹配准确度。Jiang 等提出了软加权方法(Soft-Weighting) 将SIFT特征分配给多个近邻视觉单词,并赋予不同的权重,提高了图像分类的准确率。Gemert 等提出了视觉单词不确定性( Visual Word Uncertainty )模型,该模型同样是采用软分配策略对SIFT 特征编码,进一步验证了软分配方法对于减弱视觉单词同义性和歧义性影响的有效性。Liu等针对传统软分配方法中忽略了SIFT特征潜在的流形结构的问题,提出了一种局部软分配(Localized Soft Assignment)的编码方式,进一步提升了视觉词汇特征的准确性,提高了图像分类准确率。Wang 等提出了一种多重分配( Multiple Assignment)和视觉单词加权方案,同样将SIFT特征与多个视觉单词进行匹配,有效地减弱了视觉单词同义性和歧义性对图像检索性能的影响。Yu等提出了上下文嵌入直方图(Context-embedded BoVW Histogram)模型,充分利用语义上下文信息减弱视觉单词的歧义性。
另一方面,视觉词汇直方图作为图像的视觉词汇特征,只刻画了视觉单词在图像中出现的频次,忽略了视觉单词在图像中的空间信息。合理地利用视觉单词的空间信息,有助于构建信息量更丰富的视觉词汇特征,从而提高图像分类的准确率。为此,研究人员进行了深入研究。
Lazebnik等从原始的金字塔匹配出发,提出了空间金字塔匹配模型。该模型能够粗略利用视觉单词在图像中的绝对位置信息。Shotton等采用与金字塔匹配类似的方法开发利用高维局部特征空间的分层结构信息,提出了语义纹理基元森林方法,在图像分类实验中性能表现出色。Sharma等对原始的空间金字塔匹配方法进行了扩展,提出了一种图像空间自适应分割方法,将局部特征的空间位置信息融入到视觉词汇特征的构建过程中。实验结果表明了该方法能够很好地刻画视觉单词在图像空间上的位置分布信息,提高了图像表达的准确度和图像分类的效果。
第四:分类器
得到图像的视觉词汇特征后,为了完成图像分类,需要建立分类器。分类器模型的研究已有很长的历史,广义上可以划分为两个类别:生成模型(Generative Model)和判别模型(Discriminative Model)。
生成模型对样本的联合概率分布建模,得到联合概率分布后,即可利用贝叶斯公式得到后验概率,从而完成分类。图像分类中常用的分类模型主要有:概率隐语义分析( Probabilistic Latent Semantic Analysis, PLSA)模型以及隐狄利克雷分布(LatentDirichlet Allocation, LDA) 模型等。
判别模型根据训练样本确定特征空间中分割两类对象的决策边界,从而完成两类或多类的分类。判别模型没有考虑样本的联合概率分布,直接对后验概率进行求解。图像分类中常用的分类模型主要有:支持向量机( Support Vector Machine, SVM)和条件随机场(ConditionalRandom Field, CRF)等。
生成模型能够很好地处理小样本问题,容易实现增量学习,所包含的信息也比判别模型更丰富,但模型的学习过程比较复杂。判别模型对分类特征的选择比较灵活,学习过程也相对简单,分类速度比较快。但该模型的决策边界取决于训练样本,对训练样本数量需求较大。而且,一旦样本出现变化,需要重新学习新的分类模型。
当前,在图像分类领域,支持向量机是主流的分类方法。支持向量机建立在统计学习理论基础上,在解决有限样本、高维和非线性模式识别问题中表现出优异性能。支持向量机的基本原理是,在线性可分情况下,寻找最优分类超平面(Optimal Hyperplane),而对于线性不可分情况,首先通过非线性变换将输入空间变换到一个高维空间,然后在这个新的高维空间中求取最优分类超平面。
尽管视觉词袋模型为现在研究热点,但是也不可避免的存在着一些问题,我们一起来看一下:
现阶段的图像分类方法大都依赖于图像的底层特征,而“语义鸿沟”的存在会导致计算机无法准确地从语义层面理解图像,这是图像分类研究无法回避的难题。虽然基于视觉词袋模型的图像分类技术得到了大量的理论研究和实践,成为当前解决图像分类问题的主流方法,但离真正的实用化还有很长距离。其存在的主要问题可归结为以下三个方面。
1.视觉单词的同义性和歧义性问题
视觉单词的同义性是指,多个视觉单词所描述的视觉内容具有很强的相似性,而歧义性是指多个视觉差异明显的图像内容对应同一个视觉单词。与文本分析中的单词不同,视觉单词是人为学习图像底层特征的分布得到的,没有明确的语义含义。当前,视觉词典主要是采用K-Means及其改进聚类算法生成的,这类聚类方法存在以下两个缺陷:①在数据点密集区域得到的聚类中心偏多,而在数据点稀疏区域得到的聚类中心偏少;②远离聚类中心的数据点会使导致聚类中心向数据稀疏区域漂移。这两个缺陷分别对应视觉单词的同义性和歧义性问题。视觉单词的同义性和歧义性问题严重制约了视觉词袋模型的性能。如何通过有效的聚类、随机映射和距离度量学习等方法生成区分性好、表达能力强的视觉词典是图像分类领域的一大难题。
2.视觉词汇特征中空间信息缺失的问题
视觉词汇直方图表达图像内容的方式忽略了视觉单词的空间信息。这种空间信息既包括视觉单词的绝对位置信息,还包括视觉单词间的相对位置关系信息。一幅图像中视觉单词的分布和排列并不是杂乱无章的,视觉单词的共生特性和空间依赖性是图像内容、语义信息的重要体现。因此,视觉单词间的空间位置关系信息对于图像内容和语义的表达是不可忽略的。充分挖掘和利用视觉单词的空间分布信息,并将其有效地引入到视觉词袋模型中,能够增强模型的表达能力,提高图像分类准确率。
3.视觉单词间语义相关性的度量问题
为提高视觉词典的表达能力,一方面要通过有效的聚类、度量学习等方法生成视觉单词同义性和歧义性弱的视觉词典;另一方面, 对于生成好的视觉词典,也需要有效地挖掘和度量视觉单词间的语义相关性,如含义是否相近、相反等。有效地度量和利用视觉单词间的语义相关性,并采用合理的方法构建视觉词汇特征,可以提高视觉词袋模型的语义表达能力,提高图像分类的准确率。当前,关于视觉单词间语义相关性的研究还很少。如何快速有效生成区分性好、表达能力强的视觉词典,如何将视觉单词的空间信息融入到图像视觉词汇特征中,如何有效地度量和利用视觉单词间的语义相关性,是当前基于视觉词袋模型的图像分类技术的研究重点。

词袋模型是目前SLAM研究中最常用的闭环检测方法,而且基于ORB词袋模型的SLAM系统,具有良好的实时性,能够有效提高SLAM系统的重定位准确性,增强了系统的鲁棒性。
特别是现在一些企业已经开发好的双目视觉slam研发平台,就是先利用视觉slam的位姿估计模块实时获取到双目相机的图像信息和IMU的位姿信息,然后通过视觉惯性融合算法计算出相机的深度信息、位置信息和运动姿态信息,并转换为实时位姿信息,最后通过无人机位姿解算算法将相机的位姿信息转换为无人机的位姿发送给无人机,实现无人机的自主定位。同时,视觉slam算法支持GPU加速技术,大幅提升运算速度与精度。再基于词袋技术,构建视觉slam回环检测模块,使视觉slam所计算出来的位姿信息更加准确。由相机发布的三维点云信息获取无人机与障碍物之间的距离,并应用自主导航避障算法生成可执行路径,实现无人机自主导航避障功能。

它在平台组成方面,主要由信息交互与任务控制平台、无人机系统等组成。
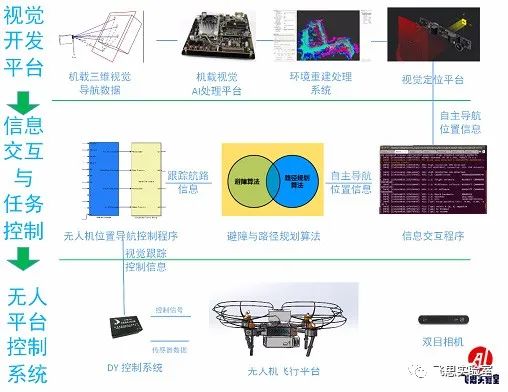
可提供的技术方案支持也非常具有前沿性,和适用性:
1、可提供视觉导航、SLAM、视觉避障、人工智能等领域最新的技术。
2、可提供完整的无人平台控制、通讯链路、视觉图像采集、图像识别、三维重建、定位解算等软件算法解决方案。提供VIO、LocalPlanner等多种实例程序,用户只需要简单配置即可实现完整的自主定位、自主建图、自主导航、自主避障等功能。
3、可提供全套的机器视觉与视觉导航的开发环境、仿真环境、硬件平台,所提供的硬件均提供完善的二次开发接口和实例代码,省去用户从头搭建开发平台的繁杂工作。
4、可提供全套的学科教学课程以及示例算法等,帮助快速展开相关课程设计,进行实际教学应用阶段
可开设实验课程如下:
⦁SLAM教学;
⦁飞思视觉slam硬件平台介绍;
⦁飞思视觉slam软件平台介绍;
⦁相机原理、点云原理、GPU加速原理简介;
⦁飞思视觉slam平台支持的视觉slam架构,
包括VINS,ORB_SLAM和Rovio,降低学校教师或学生学习SLAM的门槛;
⦁视觉slam主流技术介绍,包括多传感器融合算法,KLT光流算法双目VIO;
⦁视觉词袋技术介绍;
⦁回环检测技术介绍,包括重定位技术、全局位姿估计技术;
⦁无人机通信技术,包括Mavlimk介绍和Mavros介绍;
⦁自主导航避障算法介绍;
⦁飞思视觉slam平台应用实例介绍;
⦁ 航线飞行实例,自主导航避障实。

随着互联网上图像数据的急剧增长,基于语义的图像分类研究成为了当前计算机视觉领域的研究热点。视觉词袋模型作为基于语义的图像分类主流方法存在诸多问题,成为了研究的重点。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)