动态场景下基于实例分割的SLAM(毕业论文设计思路及流水)
前言
今年选了个比较难的毕设题目,这里记录一下自己思路和流程,为之后的学弟学妹(划掉)铺个方向。会按日期不定期的更新。
一、开题
2019.12.24
考研前选择课题是:利用深度学习对连续帧场景进行深度估计,辅助SLAM进行快速初始化,但是下午查了半天资料,遗憾的发现貌似现在深度估计技术并不能提供很准确的深度图,而SLAM是对数字精度要求很高,是一种严格的几何关系推断,因此这个课题不具有可行性,遗憾,不过看了一下午的深度估计,貌似很有意思,特别是相对深度估计(Single-Image Depth Perception in the Wild这篇文章),无监督估计(monodepth 、 sfmlearner)让我眼界大开,考虑是不是转这个方向做做?
2019.12.25
和老师聊了聊,现在有三个方向:第一个是昨天的深度估计,第二是利用语义分割辅助动态场景下SLAM,第三个是利用SLAM辅助语义分割。最终还是定下来是选择第二个方向。毕竟虽然对第一个课题感兴趣,但是深度学习这个东西吧太玄学了,又要用大量的计算资源,能避开就避开吧。而语义分割毕竟怎么说,Mask R cnn用了8GPU跑了2天迭代16万次才弄完,惹不起惹不起。老师建议我如果有可能的话可以做一个速度估计,大概就是做室外的SLAM,对运动的车辆、行人做个识别(语义分割),行人直接剔除完事,车辆的话做个速度估计就好
天真的我当时还没觉得做速度估计有啥,回去查了下资料。本来想了想,是不是可以用车牌轮廓,线特征面特征做个几何分析?但是后面打开KITTI用右键过了两个序列,发现由于车体有可能拐弯,遮挡,有点难弄,估计也是不行的。现在主流速度估计用的还是IMU惯导那一套,或者就是光流,我本来打算用光流算了,但是总感觉哪里不对,就跑过去又和老师聊了聊。果然,老师说光流第一计算太大(稠密光流)第二效果也是很差,如果不和深度结合基本没法看。我很诧异,因为我一直以为光流法很快的,毕竟大疆啥的不都用的光流吗?后来才被教育到那时稀疏光流,本质上和特征点没啥差别,但是稀疏光流必须要求帧和帧之间间隔很小,像KITTI这样肯定不行的,所以还是要回到特征点或者特征线的老路上,但是这样速度估计就变成了矩阵转换,额,有点困难啊啊啊啊。算了到时候再说吧。
2019.12.26
写开题报告,打字好累啊。
顺便看了下文献,这里把要看的文章列一下:
- 实例分割: Faster R-CNN – FCN – Mask R cnn-- YOLACT
- 语义slam:建议在orbslam2基础上修改 --参考DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
- 利用相对位姿求取速度模型;速度–相对相机方向的速度标量
- 张慧娟, 方灶军, 杨桂林. 动态环境下基于线特征的 RGB-D 视觉里程计[J]. 机器人, 2018, 40(5): 1-8.
- 基于深度学习的动态场景语义SLAM
然后是综述类文章:
- Understanding Deep Learning Techniques for Image Segmentation(语义分割)
- Deep Semantic Segmentation of Natural and Medical Images: A Review(同上)
- Visual SLAM and Structure from Motion in Dynamic Environments: A Survey (动态场景下的SLAM)
不知道什么时候能看完…
2019.12.27
开题报告完成,附百度云链接
链接:https://pan.baidu.com/s/12_mKuVwweLbW290FtuJwNw
提取码:y27p
二、语义分割研究阶段
2019.12.28
读FAST-R-CNN论文。
因为FAST-R-CNN是在R-CNN基础上改进的,所以又滚去查R-CNN的内容;然后又涉及到SPPnet,所以又去看这个文章。本来想做个笔记的,但是网上有更好的,就不献丑了。
R-CNN参考博客:https://www.jianshu.com/p/c1696c27abf8
SPPnet参考博客:https://blog.csdn.net/v1_vivian/article/details/73275259
FAST-R-CNN参考博客:https://www.cnblogs.com/CodingML-1122/p/9043124.html
其实之前我一直有误解,我以为卷积必须定尺寸的,今天看文章才知道原来卷积其实变尺寸的,毕竟卷积核啥的都是定尺寸的,和整幅图像无关,真正麻烦的是后面的全连接层,所以SPPnet采用图像金字塔提出定尺寸的特征向量,解决了这个问题。
但是SPPnet网络有一个问题没有看懂:”SPP-Net 很难通过fine-tuning对SPP-layer之前的网络进行参数微调 “(出自FAST-R-CNN论文解释)怎么理解?原文解释为:
“SPP layer is highly inefficient when each training sample (i.e. RoI) comes from a different image, which is exactly how R-CNN and SPPnet networks are trained. The inefficiency stems from the fact that each RoI may have a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image)”
大概解释是:反向传播需要计算每一个RoI感受野的卷积层梯度,通常所有RoI会覆盖整个图像,如果用RoI-centric sampling方式会由于计算too much整幅图像梯度而变得又慢又耗内存 。
写着写着我好像有点明白了,意思是ROI数量达到了2K,每个都做反向传播太多了,貌似是这个意思。
另一点不解的就是这段:
In Fast R-CNN training, stochastic gradient descent (SGD) mini-batches are sampled hierarchically, first by sampling N images and then by sampling R/N RoIs from each image. Critically, RoIs from the same image share computation and memory in the forward and backward passes. Making N small decreases mini-batch computation.
主要他没有说R代表什么,R/N代表什么,为什么同一张图片可以共享内存的计算,为什么能减小N?
后来网上找到了答案:N和R分别代表,N张图片和从N张图片中选取的R个候选框 ,这R个候选框可以复用N张图片前5个阶段的网络特征 。
附上博客:https://www.jianshu.com/p/fbbb21e1e390
2019.12.29
继续读FAST-R-CNN论文,找了个翻译版本的辅助一下:https://blog.csdn.net/xiaqunfeng123/article/details/78716060,毕竟英文看的还是有点小头疼。建议一开始读论文的时候千万不要直接上手英文,先从国内的顶级实验室文章读起,如果英语贼溜的当我没说。之后慢慢的过渡到纯英文,虽然很困难,但还是要练习啊。
代价函数中smooth函数除了靠近0的地方用了l2范数,其余都用l1范数,就是不太清楚0.5怎么来的,回头问问老师,总不会又是经验值或者超参吧?
The lower threshold of 0.1 appears to act as a heuristic for hard example mining
这一段是Mini-batch sampling 部分选择训练时的ROI区域正负样本框的时候的一句话,作者把IoU在[0.1,0.5)范围内的ROI作为负样本,但是说ROI在0.1以下的部分不能使用,难道是过小的ROI会使整个训练跑偏?有点没看懂。
作者还在后面用到了奇异值分解,并用前t个特征值近似代替以加速全连接层计算。顺便复习一下奇异值分解:https://www.cnblogs.com/endlesscoding/p/10033527.html。有个疑问U和V不是正交矩阵吗?他的维数为什么不同啊?(在博客的推导)
还有就是选择框和密集框,我的理解是选择框是FAST-R-CNN使用卷积策略选择的特征框,而密集框是传统R-CNN使用的那种4.5K的。不知道自己理解的有没有问题。
2019.12.30
惊天大雷!
今天去和老师沟通了一下,发现犯了一个错误(严格来说也不全是我的错吧)。之前的语义分割思路有些问题,对于MASK-R-CNN这类型的,虽然可能是实例分割,但是他是不区分前景和背景(比如天空),是单独将物体从背景中分割出来的。从原理上来说,这种实例分割的思路是先进行一个目标检测,再在目标检测的基础上进行语义分割,但是对于天空等一些比较独特的区域很少有人去做这种目标检测。所以另一种思路是FCN这种,即直接语义分割,然后在语义分割的结果上对每个像素进行聚类。虽然吧,我觉得问题不是太大,但是老师说最好用FCN based的网络。
顺便老师也回答了我之前的几个问题:1. 那个smooth函数的0.5可能是工程结果,如果直接用1的话,可能绝大部分数字都落在了1以内,这样就没有意义了。2. ROI在0.1以下由于完全没有意义,不能提高训练的精度,最好的负样本应该是和目标有交集但是完全推测出整体的部分,比如人的一双鞋。3. 奇异值分解要求U、V正交,但是不一定方阵,详见数值计算这本书。
另外就是SPPnet这类变尺寸的图像输入的问题,沈老师没有了解过,但是理论上来说我现在做的这个项目并不是太需要这个功能,原来我想KITTI的图像相当长,不符合一般的图像输入,如果直接处理可能会变形,但是老师解释道,KITTI数据集之所以长,是因为所使用的的相机采集图像的时候是隔行扫描的方式的,行与行之间曝光时间有一定的偏差。为了避免这种偏差,最终数据集将奇数行或者偶数行抽掉了,因此显得比较宽。所以,可以直接对KITTI数据集的图片进行线性插值运算,影响不大。
后来老师又提出一个思路,就是将FCN的前后景分割和MaskRCNN的物体分割结合起来,毕竟FCN的精细程度并不是这么高。不过这个任务就交给小学弟吧,毕竟还有SLAM这个大坑呢。
明天开始看FCN。(但实际上隔了超长时间)
2020.1.3
前几天复习备考+元旦出去玩,没来及看,今天抓紧补上。
in which each pixel is labeled with the class of its enclosing object
or region, but with short-comings that this work addresses.
最后一句话没找到合适的翻译,我的理解是 “这项工作仍然有存在一些缺点”
Patchwise:一个术语,介于像素级别和图像级别的区域,也就是块,每个patch都是由好多个pixel组成的 。
superpixels:超像素主要功能:作为图像处理其他算法的预处理,在不牺牲太大精确度的情况下降维,详见:https://www.zhihu.com/question/27623988?sort=created
3.1. Adapting classifiers for dense prediction 这一节有很多都看不懂:
另外从文章中貌似知道了FCN这类全景卷积大概叫做Dense prediction吧,回去搜搜,不太确定。
The spatial output maps of these convolutionalized models make them a
natural choice for dense problems like semantic segmentation. With
ground truth available at every output cell, both the forward and
backward passes are straightforward, and both take advantage of the
inherent computational efficiency (and aggressive optimization) of
convolution. The corresponding backward times for the AlexNet example
are 2.4 ms for a single image and 37 ms for a fully convolutional 10 ×
10 output map, resulting in a speedup similar to that of the forward
pass.
这一块没有看懂,正推法和逆推法指的什么?
This coarsens the output of a fully convolutional version of these
nets, reducing it from the size of the input by a factor equal to the
pixel stride of the receptive fields of the output units.
大概就是最后一步你把网络化为7x7,然后直接用7x7的滤波器卷积,不过为什么就变得粗糙了…emm,没懂。
3.2章节是 Shift-and-stitch is filter rarefaction,更是难懂,我把翻译找来反复看了好几遍也摸不到头脑,搜了一下,才发现理解不了的不仅仅只有我一个,博客:https://www.jianshu.com/p/e534e2be5d7d,比较清楚解释了什么是 shift and stitch。但是原理归原理,我还是没有看懂这个方法是想要干什么?作者隐藏的含义貌似是这种方法做dense prediction,但为什么会从一个5x5的图片下采样又恢复为5x5吗?难道是类似于编码和解码的概念吗?在后面,作者又提到了在此基础上的技巧:多孔算法(a` trous algorithm )这个我也没有看懂,不过作者最后没有用到它们就是的了,因为上采样算法更加高效。
我要吐血了,这个表述我换了中文都反复看十几遍还有点疑惑。
random selection of patches within an image may be recovered simply.
Restricting the loss to a randomly sampled subset of its spatial terms
(or, equivalently applying a DropConnect mask [36] between the output
and the loss) excludes patches from the gradient computation.
中文:
在一张图片中随机选择patches可能更容易被重新找到。限制基于它的空间位置随机取样子集产生的损失(或者可以说应用输入和输出之间的DropConnect
mask )排除来自梯度计算的patches。
我不能理解的地方在于为什么会可能更容易被找到?而且最后一句话压根没看懂。看这篇文章有种吐血的感觉。
2020.1.4
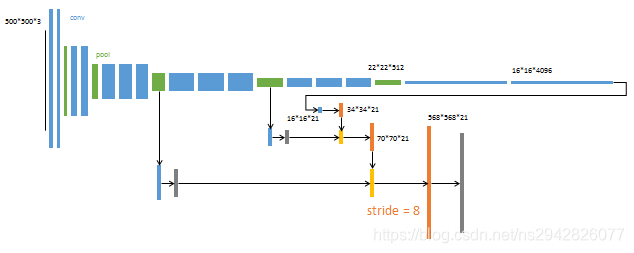
论文的上图3展示结构一开始没看懂,但是我在博客上https://www.cnblogs.com/kk17/p/9851773.html看到的DAG网络很好的展示了其结构精髓。
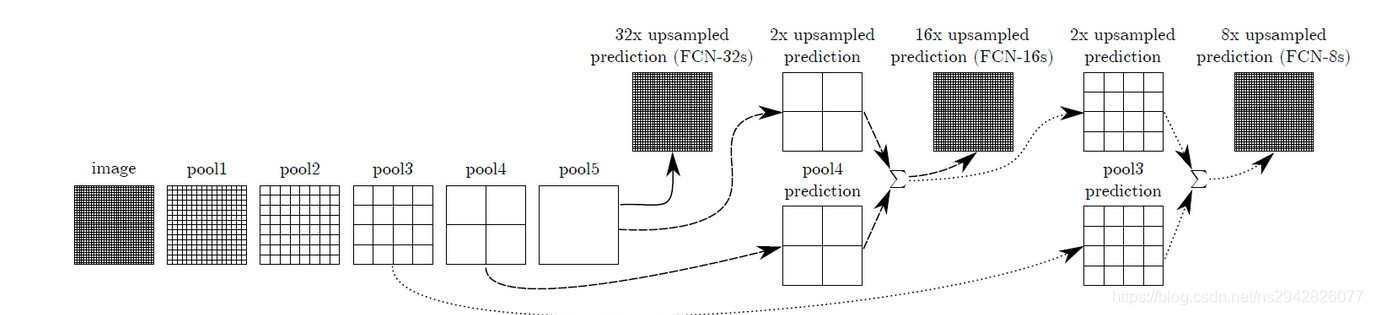
此外:
and doubled learning rate for biases, although we found training to be
sensitive to the learning rate alone
上面这句话的“对偏差的学习率”和“尽管单独对学习率敏感”没有看懂。
另外今天在知乎上有了意外的收获,终于明白了这种全像素分类叫做什么了:全景分割。真的魔幻,居然用了一星期才明白自己在做的东西叫做什么。今天把FCN勉强看完了,但是有很多疑问,明天复习备考期末,等后天见老师再说。下周开始看下篇论文:Mask R CNN。
2020.01.07
今天又和老师沟通了一下,我之前一直疑惑为什么非要分为全景(全像素级)语义分割和实例分割(针对特定目标),为什么不能用实例分割的目标框去检测天空不行吗?为什么要用全景分割识别天空背景?老师解释说天空其实是一个不规则形状(树木、高楼等)和不规则图案(不同天气,阳光等)的目标,不连续且变化较大,不适合直接做目标检测。另外,本来想接着看何恺明的全景分割网络的,结果老师提醒我貌似这个没有开源……emmm,然后不知道接下来用哪个的时候,老师教导我上可以去KITTI官网上语义分割这一个章节看看,于是惊喜地发现上面按照全像素分割和实例分割分出了两个部分,上面罗列着各个算法排名及实验结果。实例分割Mask -R-CNN领跑全程,ok,实例网络就选它了;而全像素分割我所熟悉的FCN才仅仅排到倒数第一,emm,ok,我觉得排名第一的算法也值得研究一下,接下来的路就很清楚了,真不愧是导师啊。
mask r cnn 的思路是并行进行掩码和类标签的预测,并没有沿袭了fast r cnn 那种先识别再分割,(其实本来还在疑惑为什么没人先分割后识别,想了一下发现我傻了,仅仅目标分割没必要全像素分割的,而且全像素分割也不会给目标识别带来什么精度上的提升(大概)。mask r cnn论文也提过这样做的前辈,但明显效果不是很好。)与之前想象的相反,mask r cnn并行计算标签和掩码没有降低精度,反而是精度提升的关键。
讲解博客:https://blog.csdn.net/wangdongwei0/article/details/83110305
FPN架构比较:https://blog.csdn.net/WZZ18191171661/article/details/79494534,简单来说就是将图像金字塔与深度学习结合,更容易检测小目标。
顺便Mask R CNN文章感觉比FCN要容易懂很多(大概是中国人一作的原因吧),所以很快看完,下一篇文章是KITTI像素级分类排名第一的Improving Semantic Segmentation via Video Propagation and Label Relaxation,他也是有开源的,不过代码藏得差点没看到。
2020.01.08
这篇文章比较新,暂时没有找到论文详解之类的东西,只有一个概括:https://blog.csdn.net/kevin_zhao_zl/article/details/100605690,所以只能自己做一下笔记。
从绪论可以看出他的主要工作是 synthesizing new training samples,提出了一种基于视频帧预测的方法合成训练样本来对训练数据集进行增广 ,比较了传统的深度网络生成(慢),人工合成标注(假),网络训练标注(依赖于训练方法),连续帧法(有各种缺点,具体在第二部分相关工作里)
标签增强算法:https://blog.csdn.net/Katherine_hsr/article/details/82343647
看到这里不想看了,涉及大量我没接触过的东西,半监督学习不太熟,所以直接看结果吧。
============================================================
换文章,换成排名第五的算法(因为第五才有开源的代码),文章出自论文:Ladder-style DenseNets for Semantic Segmentation of Large Natural Images,论文及代码网址为:https://ivankreso.github.io/publication/ladder-densenet/。
该文章从DenseNet 架构改进而来,关于DenseNet可以用论文中一张图简单介绍:

相关工作里面提到 the dilated convolution ,即著名的空洞卷积,来复习一下:https://www.jianshu.com/p/f743bd9041b3,里面提到一些之前没有注意到过的细节。但是作者提出空洞卷积有两个缺点:一个是占用内存开销过于庞大;另一个是:
Second, dilatedfiltering treats semantic segmentation exactly as if it
were ImageNet classification, which, in our view, should not be the
case. Semantic segmentation has to provide accurate location
information: one pixel left or right must make a difference between
one class and another. We find it hard to accept that deep semantic
layers alone are the optimal place for bringing such
location-dependent decisions, and that brings us close to the focus of
our research.
所以最后作者放弃了空洞卷积。第二点从provide accurate location information这句我猜是空洞卷积无法准确的提供定位信息而是简单的对像素进行分类,沈老师也赞同了我的看法。
2020.01.09
文献6和19是本文研究的基础,文献6是Laplacian Pyramid Reconstruction and Re nement for Semantic Segmentation,博客参考:https://blog.csdn.net/u010158659/article/details/72511428?locationNum=7&fps=1,这个稍微有点迷,先看看后面是不是有解释;关于梯形网络他举例文献19的Multipath refinement networks for high-resolution semantic segmentation,参见博客https://www.cnblogs.com/fourmi/p/9983019.html;
另外就是参考文献26提到的两条处理流的网络Full-Resolution Residual Networks (FRRNs),参考博客https://blog.csdn.net/u011974639/article/details/79561297,没有看论文,毕竟不是专门研究语义分割的,但是思路还是很有意思的,它将网络分为池化流和残差流,一个用做语义,一个做细节。
他还提到了另一个用稠密网络+梯形结构的文章(文献12)The One Hundred Layers Tiramisu:Fully Convolutional DenseNets for Semantic Segmentation ,可惜那篇文章的图画的难懂不说还丑的要死(严格来说这篇也是),引以为戒。有介绍的博客,可惜没看太懂:https://blog.csdn.net/sunyao_123/article/details/75449116。但是作者认为他们的结构是对称的,直观感受上来看,patch-level classification should be more difficult than finding the object boundary by blending(?不应该是找到物体边界更难吗?)
剩下都是这个网络的细节一些东西,配合代码还挺清晰的。简单概括一下就是梯形网络+稠密网络,没啥特殊的,就不在多说了。不过随着这个文章读完,语义分割论文部分要先放下了,接下来是SLAM的论文及复习SLAM相关的学习,我要重新开一篇文章了,csdn每改一次都要审核挺麻烦的。