目录
前言
1. DeepXplore
1.1 DeepXplore工作流程
1.2 DeepXplore主要的贡献是:
1.3 论文中的示例
2. DEEP CONTRACTIVE NETWORK—深度压缩网络
3. DeepFool
参考文献:
前言
传统软件需要测试,对于深度学习系统的对抗攻击会使得深度学习模型产生错误的行为,因此对于深度学习系统也需要测试。
DLFuzz,是检测深度神经网络健壮性的差分模糊测试框架。DLFuzz目标是最大化神经元覆盖率并生成更多的针对深度学习模型的对抗样本。相比于DeepXplore使用高神经元覆盖率和多错误触发数联合进行样本的优化和选取。输入的是原始的测试数据样本。输出的是基于原始样本生成的对抗样本,对抗样本可以触发模型的错误预测。
本文讨论的是DLFuzz的相关扩展知识,在这里只简单说明一下,有时间下回在描述DLFuzz。接下来讨论DeepXplore、DEEP CONTRACTIVE NETWORK深度压缩网络和DeepFool。
1. DeepXplore
(DeepXplore: Automated Whitebox Testing of Deep Learning Systems)
1.1 DeepXplore工作流程

图1. DeepXplore工作流程
如上图1所示,DeepXplore将未标记的测试输入作为种子(seeds),通过同质异构的DNN模型表现出不同的行为,同时经过联合优化控制各个DNN之间的行为差异化程度和最大化神经元覆盖率,最后输出新的可以触发深度学习系统不同行为的输入集。
1.2 DeepXplore主要的贡献是:
(1)神经元覆盖率;
(2)生成新输入集;
(3)新输入集自动打标签;
(4)对新输入集的再训练。
(1)神经元覆盖率:DNN 中的每个神经元往往需要负责提取其输入的一个特定的特征,因此神经元覆盖率的提升可以有效测试深度学习系统的行为。
提升神经元覆盖率,一般通过迭代找到没有激活的神经元,对输入进行干扰,使得经过该神经元的输出大于阈值,则此神经元被激活。即该神经元被覆盖。
(2)生成新的输入集进行测试
通过梯度来计算联合优化问题,最终生成新的输入集。联合优化的目标:其一是最大化神经元覆盖率;其二是最大化各个深度学习模型的行为差异。
最大化神经元覆盖率在于覆盖更多的数据特征。而最大化行为差异是使得新的输入集可以使得深度学习模型训练得出错误的结果,以此来测试深度学习系统的鲁棒性。
(3)新输入集自动打标签
如图1.所示,将未标记的测试输入作为种子,训练多个DNN模型,这些DNN模型的本质是类似的,主要的区别就是神经元数量的不同,通过控制神经元数量也可以比较深度神经网络模型的鲁棒性。输入种子数据后,多个DNN模型进行训练,然后进行投票,获取标签数据。
(4)对新输入集的再训练
用新输入集对模型进行再训练,用来提升模型的准确性和识别污染的数据。
1.3 论文中的示例

图2. 两个深度神经网络用于将图像分类为汽车或者人脸
两个网络均把给定的图像以高概率归类为汽车;然后,DeepXplore会试图通过修改输入以使一个神经网络继续将输入的图像归类为汽车,而DNN2则会认为它是一个面孔,从而最大化发现差异化行为的可能性。
2. DEEP CONTRACTIVE NETWORK—深度压缩网络
(TOWARDS DEEP NEURAL NETWORK ARCHITECTURES ROBUST TO ADVERSARIAL EXAMPLES )
论文中实验验证发现,对去噪自编码(Denoising Auto Encoders,DAE)输入对抗样本时,输出为去噪声后的样本,能够去除大量的对抗噪声,但是如果把去噪自编码和深度网络堆叠起来,反而变得更加脆弱,新的深度网络同样会受到对抗样本的攻击。
然后作者又对压缩自编码(CAE)进行分析和实验。压缩自编码是在自编码的损失函数的基础上引入分层收缩惩罚,使得输入的微小变化不会给隐层激活值带来太大改变,从而使输出变量对一定范围内的输入变量的变化不敏感。因为损失函数的平滑度惩罚项,增强了压缩自编码(CAE)的泛化能力,对于对抗样本这种输入变化不明显的样本具有较好的鲁棒性。
借助压缩自编码(CAE) 的思想,将压缩自编码(CAE)扩展到深度网络,对惩罚项的近似处理减少计算代价,提出深度收缩网络(DCN)。深度压缩网络(DCN)使用了和压缩自编码器(Contractive Auto Encoders)相同的分层收缩惩罚,类似的平滑度惩罚项,通过平滑模型输出的机制来加强模型在类似对抗样本这样的小扰动下的鲁棒性。作者进行实验也证明了该网络可提高深度神经网络对对抗样本的鲁棒性。
3. DeepFool
( DeepFool:a simple and accurate method to fool deep neural networks )
作者讨论的内容是寻求最小的扰动来达到生成对抗样本。在这篇论文中作者提出DeepFool算法,来生成最小最优的扰动使得样本成为对抗样本,并且提出了一个简单的精确的方法来计算对抗扰动以及比较不同分类器的鲁棒性。

图3. 两种模型加入的扰动
DeepFool论文中比较了FGSM(fast gradient sign method), FGSM虽然计算快,但只是提供了最优扰动的一个粗略的估计,它使用的是梯度的方法,容易得到局部最优解,DeepFool能够得到更小的扰动。
如图3. DeepFool算法生成的扰动和FGSM算法生成的扰动。可以看到当生成的target label都为turtle时,DeepFool算法所加入的扰动,明显低于FGSM。
文中首先对于二分类器进行鲁棒性评估。

图4. 二分类
分类器在x处的鲁棒性:

如图4,分类器在x处的鲁棒性,即x到分类边界的距离。
分类器的鲁棒性:

样本离分类边界越远,样本2范数越小,评测数值越大表示越鲁棒。
在多分类分类器上的DeepFool实际上可以看作是,在二值分类器上DeepFool的聚合。

图5. 多分类器
如图5,对于多分类器问题,需要得到一个点到某分类函数边界的最小距离:
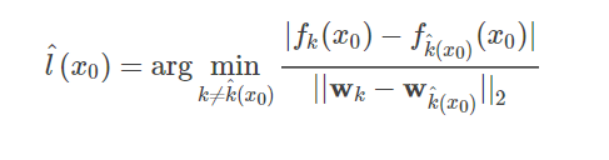
便可以得到最小扰动:

DeepFool训练出来的对抗样本进行Fine-tuning后,网络的鲁棒性变的更好。FGSM的Fine-tuning却让网络的鲁棒性变差。作者认为用变动过大的扰动来进行Fine-tuning会让网络的鲁棒性变差。经过实验对比,使用DeepFool算法得到的更小扰动的对抗样本,并且使用这样的对抗样本来增强实验数据能够增加神经网络模型对对抗扰动的鲁棒性。因为DeepFool生成的精确的最小的扰动,所以可以用来评估模型的鲁棒性。
参考文献:
[1] DeepXplore: Automated Whitebox Testing of Deep Learning Systems
[2] TOWARDS DEEP NEURAL NETWORK ARCHITECTURES ROBUST TO ADVERSARIAL EXAMPLES
[3] DeepFool:a simple and accurate method to fool deep neural networks
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)