摘要
深度学习是当前人工智能崛起的核心。在计算机视觉领域,它已经成为从自动驾驶汽车到监控和安全等各种应用的主力。虽然深度神经网络在解决复杂问题方面取得了惊人的成功(通常超出了人类的能力),但最近的研究表明,它们很容易受到对手的攻击,这种攻击的形式是对输入的微妙扰动,导致模型预测不正确的输出。对于图像,这样的扰动往往太小而无法察觉,但它们完全欺骗了深度学习模型。对抗性攻击严重威胁了深度学习在实践中的成功。这一事实最近导致了这一方向的大量捐款涌入。本文首次对计算机视觉中深度学习的对抗性攻击进行了全面的调查。我们回顾了设计对抗性攻击的工作,分析了此类攻击的存在,并提出了防御措施。为了强调对抗性攻击在实际条件下是可能的,我们分别回顾了在现实世界场景中评估对抗性攻击的贡献。最后,在文献综述的基础上,对这一研究方向进行了更广阔的展望。
常用术语
-
Adversarial attacks 对抗攻击
-
Adversarial example/image 对抗样本/图像
对抗样本/图像是干净图像的一个修改版本,它被故意干扰(例如通过添加噪声)来混淆/愚弄机器学习技术,如深层神经网络。
-
Adversarial perturbation 对抗性扰动
对抗性扰动是将噪声添加到干净的图像中,使其成为对抗性的例子。
-
Adversarial training 对抗性训练
对抗训练是指除了使用干净的图像外,还使用对抗性图像来训练机器学习模型。
-
Adversary 对抗者
对抗者通常指的是创造对抗性例子的代理人。但是,在某些情况下,示例本身也称为对抗者
-
Black-box attacks 黑盒攻击
黑盒攻击向目标模型提供在不了解该模型的情况下生成的对抗性示例(在测试期间)。在一些情况下,假设对手具有有限的模型知识(例如,其训练过程和/或其体系结构),但是绝对不知道模型参数。在其他情况下,使用有关目标模型的任何信息被称为“半黑盒”攻击。我们在本文中使用以前的约定。
-
Detector 检测器
检测器是一种(仅)检测图像是否是为对抗样本的机制
-
Fooling ratio/rate 欺骗率
欺骗率/比率指示在图像被扰动之后训练模型在其上改变其预测标签的图像的百分比。
-
One-shot/one-step methods 一次/一步方式
一次/一步方式通过执行一步计算(例如,计算一次模型损失的梯度)来产生对抗性扰动。相反的是迭代方式,它们多次执行相同的计算以获得单个扰动。后者通常在计算上很昂贵。
-
Quasi-imperceptible 准不可察觉的扰动
准不可察觉的扰动对于人类的感知来说对图像的损害非常轻微。
-
Rectifier 整流器(校正器)
整流器修改对抗样本,以将目标模型的预测恢复到其对同一示例的干净版本的预测。
-
Targeted attacks 有目标攻击
目标攻击欺骗了模型,使其错误地预测对抗性图像为特定标签。它们与非目标攻击相反,在非目标攻击中,对抗性图像的预测标记是不相关的,只要它不是正确的标记。
-
Threat model
威胁模型是指一种方法考虑的潜在攻击类型,例如黑盒攻击。
-
Transferability
可转移性指的是对抗性例子即使对于用于生成它的模型之外的其他模型也保持有效的能力。
-
Universal perturbation 普遍扰动
普遍扰动能够以很高的概率在任意图像上欺骗给定模型。请注意,普遍性是指扰动的性质是“图像不可知论”,而不是具有良好的可转移性。
-
White-box attacks 白盒攻击
白盒攻击假设了目标模型的完整知识,包括其参数值、体系结构、训练方法,在某些情况下还包括其训练数据。
对抗性攻击
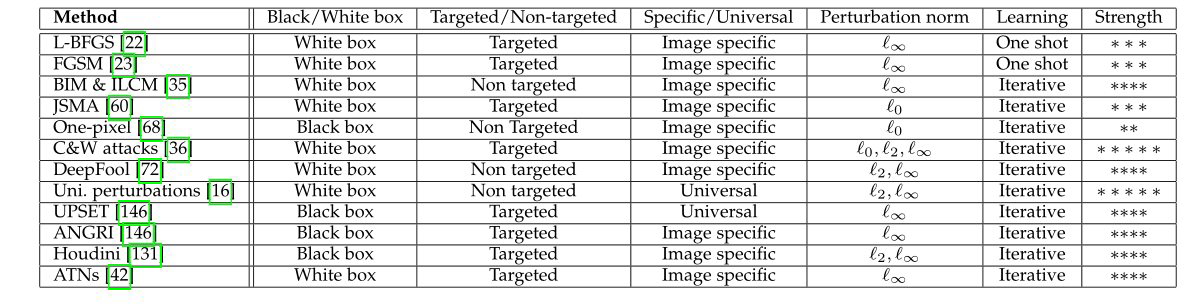
用于分类的攻击
- Box-constrained L-BFGS
- Fast Gradient Sign Method (FGSM)
- Basic & Least-Likely-Class Iterative Methods(BIM)
- Jacobian-based Saliency Map Attack (JSMA)
- One Pixel Attack
- Carlini and Wagner Attacks (C&W)
- DeepFool
- Universal Adversarial Perturbations
- Upset and Angri
- Houdini
- Adversarial Transformation Networks (ATNs)
- Miscellaneous Attacks
Box-constrained L-BFGS
I
c
∈
R
m
I
c
∈
R
m
I
c
∈
R
m
Ic∈RmIc∈Rm \mathbf{I}_{c} \in \mathbb{R}^{m}
Ic∈RmIc∈RmIc∈RmR(t)。
根据公式Ip的大小在[0,1]之间
Houdini
Houdini是一种用于欺骗基于梯度的机器学习算法的方法,通过生成特定于任务损失函数的对抗样本实现对抗攻击,即利用网络的可微损失函数的梯度信息生成对抗扰动。除了图像分类网络,该算法还可以用于欺骗语音识别网络。
Adversarial Transformation Networks (ATNs)
Baluja 和 Fischer[42] 训练了多个前向神经网络来生成对抗样本,可用于攻击一个或多个网络。该算法通过最小化一个联合损失函数来生成对抗样本,该损失函数有两个部分,第一部分使对抗样本和原始图像保持相似,第二部分使对抗样本被错误分类
结果显示,尽管上述方法能被察觉出来,但是它们的欺骗率是前所未有的高
Miscellaneous Attacks
其他: 混杂攻击
其他的攻击方法包括:
- Sabour等显示了通过改变深层神经网络的内层来生成对抗性例子的可能性。
- Papernot等研究了用于深度学习的对抗性攻击的可转移性以及其他机器学习技术,并进一步介绍了可转移性攻击。
- Narodytska和Kasiviswanathan[54]提出了仅改变图像中的几个像素点来欺骗神经网络的更进一步的黑盒攻击。
- Liu等介绍了“epsilon近邻”这种能够以100%准确率欺骗蒸馏防御网络的白盒攻击方法。
- Oh等从博弈论的角度研究了针对防御对抗的网络的攻击。
- Mpouri等设计了与数据无关的方法来生成通用的对抗扰动。
- Hosseini等引入了“语义对抗样本”的概念,以输入图像能与人类的语义相同但是会被错分为基础思路。
- Kanbak等基于DeepFool方法的缺陷使用了“ManiFool”方法,用于评估神经网络对几何扰动的鲁棒性。
- Dong等提出了一种迭代方法来提升黑盒攻击。
- Carlini和Wagner说明了十种对抗的防御方法可以通过使用新的损失函数而失效。
- Rozsa等提出了“热、冷”的方法,对一张图像生成多个可能的对抗样本。
分类/识别场景以外的对抗攻击
- 在自编码器和生成模型上的攻击
- 在循环神经网络上的攻击
- 深度强化学习上的攻击
- 在语义切割和物体检测上的攻击
现实场景下的对抗攻击
- Attacks on Face Attributes 面部特征攻击
- Cell-phone camera attack 手机相机攻击
- Road sign attack 路标攻击
- Generic adversarial 3D objects 生成敌对3D对象
- Cyberspace attacks 网络攻击
- Robotic Vision & Visual QA Attacks 机器人视觉和视觉QA攻击
对抗样本的存在性分析
这部分不是很懂
- Limits on adversarial robustness 对抗鲁棒性的限制
- Space of adversarial examples 对抗样本的空间
- Boundary tilting perspective 边界倾斜观点
- Prediction uncertainty and evolutionary stalling of training cause adversaries 预测的不准确性和训练中进化的停滞导致了反例的产生
- Accuracy-adversarial robustness correlation 准确性-对抗 的鲁棒性相关
- More on linearity as the source 更多关于线性的来源
- Existence of universal perturbations 通用扰动的存在
对抗攻击防御
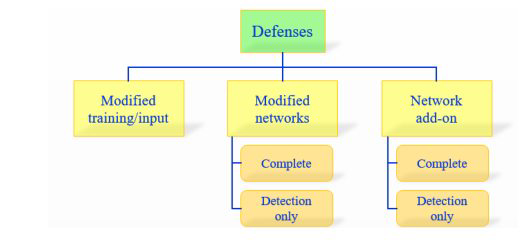
目前,在对抗攻击防御上存在三个主要方向:
1)在学习过程中修改训练过程或者在测试阶段修改的输入样本。
2)修改网络,比如:添加更多层/子网络、改变损失/激活函数等。
3)当分类未见过的样本时,用外部模型作为附加网络。
这些方向具体又可分为(a)完全抵抗(Complete),即能够分对对抗样本的原始类别(b)仅探测方法(Detection only),即只鉴别出哪些是对抗样本。具体分类如下图:
Modified training/input
修改训练过程/ 输入数据
Brute-force adversarial training
通过不断输入新类型的对抗样本并执行对抗训练,从而不断提升网络的鲁棒性。
为了保证有效性,该方法需要使用高强度的对抗样本,并且网络架构要有充足的表达能力。
这种方法需要大量的训练数据,因而被称为蛮力对抗训练。
很多文献中提到这种蛮力的对抗训练可以正则化网络以减少过拟合 [23,90]。
然而,Moosavi-Dezfooli[16] 指出,无论添加多少对抗样本,都存在新的对抗攻击样本可以再次欺骗网络
Data compression as defense
注意到大多数训练图像都是 JPG 格式,Dziugaite等人使用 JPG 图像压缩的方法,减少对抗扰动对准确率的影响。实验证明该方法对部分对抗攻击算法有效,但通常仅采用压缩方法是远远不够的,并且压缩图像时同时也会降低正常分类的准确率,后来提出的 PCA 压缩方法也有同样的缺点。
矛盾: 较大的压缩也会导致对干净图像的分类精度的损失,而较小的压缩通常不能充分消除敌意干扰。
Foveation based defense
Luo等人提出用中央凹(foveation)机制可以防御 L-BFGS 和 FGSM 生成的对抗扰动,其假设是图像分布对于转换变动是鲁棒的,而扰动不具备这种特性。但这种方法的普遍性尚未得到证明。
Data randomization and other methods
Xie等人发现对训练图像引入随机重缩放可以减弱对抗攻击的强度,其它方法还包括随机 padding、训练过程中的图像增强等
Modifying the network
Deep Contractive Networks
人们观察到简单地将去噪自编码器(Denoising Auto Encoders)堆叠到原来的网络上只会使其变得更加脆弱,因而 Gu 和 Rigazio[24] 引入了深度压缩网络(Deep Contractive Networks),其中使用了和压缩自编码器(Contractive Auto Encoders)类似的平滑度惩罚项
Gradient regularization/masking
Ross和Doshi-V Elez[52]研究了输入梯度正则化[167]作为对抗鲁棒性的一种方法。他们的方法训练可微分模型(例如,深度神经网络),同时惩罚导致输出相对于输入变化的变化程度。这意味着,一个小的对抗性扰动不太可能彻底改变训练模型的输出。结果表明,该方法与暴力对抗性训练相结合,对FGSM[23]和JSMA[60]等攻击具有很好的鲁棒性。然而,这些方法中的每一种都几乎使网络的训练复杂度翻了一番,这在许多情况下已经是令人望而却步的
Defensive distillation
据Hinton等[166]介绍,distillation (蒸馏)是指将复杂网络的知识迁移到简单网络上。该知识以训练数据的类概率向量形式提取,并反馈给训练原始模型。Papernot[38] 利用这种技术提出了 Defensive distillation,并证明其可以抵抗小幅度扰动的对抗攻击。防御性蒸馏也可以被看作是梯度遮罩技术的一个例子
Biologically inspired protection
使用类似与生物大脑中非线性树突计算的高度非线性激活函数以防御对抗攻击 [124]。另外一项工作 Dense Associative Memory 模型也是基于相似的机制 [127]。Brendel和Bethge[187]声称,由于计算的数值限制,这些攻击在生物激发的保护上失败了[124]。稳定计算再次让攻击受保护的网络成为可能。
Parseval Networks
这些网络通过控制网络的全局Lipschitz常数来分层正则化。网络可以被看作是函数(在每一层)的组合,通过对这些函数保持一个小的Lipschitz常数,可以对这些函数对抗小的干扰。
DeepCloak
在分类层(一般为输出层)前加一层特意为对抗样本训练的遮罩层。添加的层通过向前传递干净的和对抗性的图像对进行显式的训练,它为这些图像对编码先前层的输出特性之间的差异。它背后的理论认为添加层中最主要的权重对应于网络最敏感的特性(就对抗操纵而言)。因此,在进行分类时,这些特征被强制将添加的层的主导权重变为零。
Miscellaneous approaches
这章包含了多个人从多种角度对深度学习模型的调整从而使模型可以抵抗对抗性攻击。
Zantedeschi等[46]提出使用有界的ReLU[174]来降低图像中对抗性模式的有效性。
Jin等[120]介绍了一种前馈CNN,它使用附加噪声来减轻对抗性示例的影响。
Sun et al.[56]提出了以统计过滤为方法使网络具有鲁棒性的超网络。
Madry et al.[55]从鲁棒优化的角度研究对抗性防御。他们表明,与PGD对手进行对抗性训练,可以成功地抵御一系列其他对手。后来,Carlini等[59]也证实了这一观察。
Na等[85]采用了一种统一嵌入的网络进行分类和低水平相似度学习。该网络使用的是干净图像和相应的对抗性嵌入样本之间的距离。
施特劳斯等人[89]研究了保护网络免受扰动的集成方法。
Kadran等[136]修改了神经网络的输出层,以诱导对对抗攻击的鲁棒性。
Wang et al.[129],[122]利用网络中的非可逆数据变换,开发了抗敌对神经网络。
Lee等人[106]开发了多种规则化网络,利用训练目标来最小化多层嵌入结果之间的差异。
Kotler和Wong[96]提出学习基于相关性的分类器,该分类器对小对抗扰动具有鲁棒性。他们训练一个神经网络,在一个标准设置中,它可以很好地达到高精确度(90%)。
Raghunathan等[189]研究了具有一个隐藏层的神经网络的防御问题。他们的方法在
MNIST数据集上生成一个网络和一个证书,达到一个防御目的。
Kolter和Wong[96]和Raghunathan等[189]是为数不多的几种可以证明的对抗敌对攻击的方法。考虑到这些方法在计算上不适用于更大的网络,唯一被广泛评估的防御是Madry等人[55]的防御。
Detection Only approaches
这章介绍了 4 种网络,SafetyNet,Detector subnetwork,Exploiting convolution filter statistics 及 Additional class augmentation。
- SafetyNet 介绍了 ReLU 对对抗样本的模式与一般图片的不一样,文中介绍了一个用 SVM 实现的工作。
- Detector subnetwork 介绍了用 FGSM, BIM 和 DeepFool 方法实现的对对抗样本免疫的网络的优缺点。
- Exploiting convolution filter statistics 介绍了同 CNN 和统计学的方法做的模型在分辨对抗样本上可以有 85% 的正确率。
使用附加网络
- Defense against universal perturbations 防御通用扰动
- GAN-based defense 基于 GAN 的防御
- Detection Only approaches 仅探测方法
Defense against universal perturbation
Akhtar等人[81]提出了一种防御框架,该框架将额外的预输入层附加到目标网络中,并训练它们对对抗样本进行校正,使分类器对同一图像的干净版本的预测与对抗样本预测相同。通过提取训练图像输入输出差异的特征,对分离的检测器进行训练。利用一个单独训练的网络加在原来的模型上,从而达到不需要调整系数而且免疫对抗样本的方法
GAN-based defense
Lee等人[101]利用生成性对抗网络的流行框架[153]来训练一个对FGSM[23]类攻击健壮的网络。作者建议沿着一个生成网络直接对网络进行训练,该网络试图对该网络产生扰动。在训练过程中,分类器不断尝试对干净和扰动的图像进行正确的分类。我们将此技术归类为附加方法,因为作者建议始终以这种方式训练任何网络。在另一个基于GAN的防御中,Shen等[58]人使用网络的生成器部分来修正一个受干扰的图像。
Detection Only approaches
介绍了 Feature Squeezing、MagNet 以及混杂的办法。
- Feature Squeezing 方法用了两个模型来探查是不是对抗样本。后续的工作介绍了这个方法对 C&W 攻击也有能接受的抵抗力。
- MagNet:作者用一个分类器对图片的流行(manifold)测量值来训练,从而分辨出图片是不是带噪声的,值得注意的是,Carlini和Wagner[188]最近证明,这种防御技术也可以在稍大的扰动下被击败。
- 混杂方法(Miscellaneous Methods):作者训练了一个模型,把所有输入图片当成带噪声的,先学习怎么去平滑图片,之后再进行分类。
对研究方向的展望
-
The threat is real
这种威胁是真实存在的 : 我们可以断言,对抗性攻击在实践中对深度学习构成了真正的威胁
-
Adversarial vulnerability is a general phenomenon
敌意脆弱性是一种普遍的现象:我们可以很容易地发现深度学习方法通常容易受到敌意攻击。
-
Adversarial examples often generalize well
对抗性例子通常具有很好的通用性:文献中报道的对抗性例子最常见的属性之一是它们在不同的神经网络之间很好地转移。对于架构相对相似的网络尤其如此。黑盒攻击中经常利用对抗性例子的泛化。
-
Reasons of adversarial vulnerability need more investigation
对抗性脆弱性的原因需要更多的研究:关于深层神经网络对微妙的对抗性扰动的脆弱性背后的原因,文献中有不同的观点。通常,这些观点彼此不能很好地对齐。显然有必要在这个方向上进行系统的调查。
-
Linearity does promote vulnerability
线性确实促进了脆弱性:古德费罗等人。[23]首先提出,现代深层神经网络的设计迫使它们在高维空间中线性行为,也使它们容易受到对手的攻击。虽然这一概念很受欢迎,但在文学中也遇到了一些反对意见。我们的调查指出了多个独立的贡献,认为神经网络的线性是它们易受对手攻击的原因。基于这一事实,我们可以认为线性确实提高了深层神经网络对敌意攻击的脆弱性。然而,这似乎并不是成功地用廉价的分析扰动愚弄深度神经网络的唯一原因。
-
Counter-counter measures are possible
反措施是可能的:虽然存在多种防御技术来对抗对抗性攻击,但文献中经常显示,被防御的模型可以再次通过制定反措施成功攻击,例如见。这一观察结果表明,新的防御措施还需要对它们对抗明显的反措施的健壮性进行估计。
原文链接:https://blog.csdn.net/qq_33935895/article/details/104705524
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)