一、错误示范
我们在VS环境下进行CUDA编程的时候可能会出现如下MSB1721的错误

二、解决方式
首先确保好是在x64平台下运行:

确定无误然后如果还有问题的话,依次点击调试->最下面的调试属性(前面的名字取决于你项目的名称)
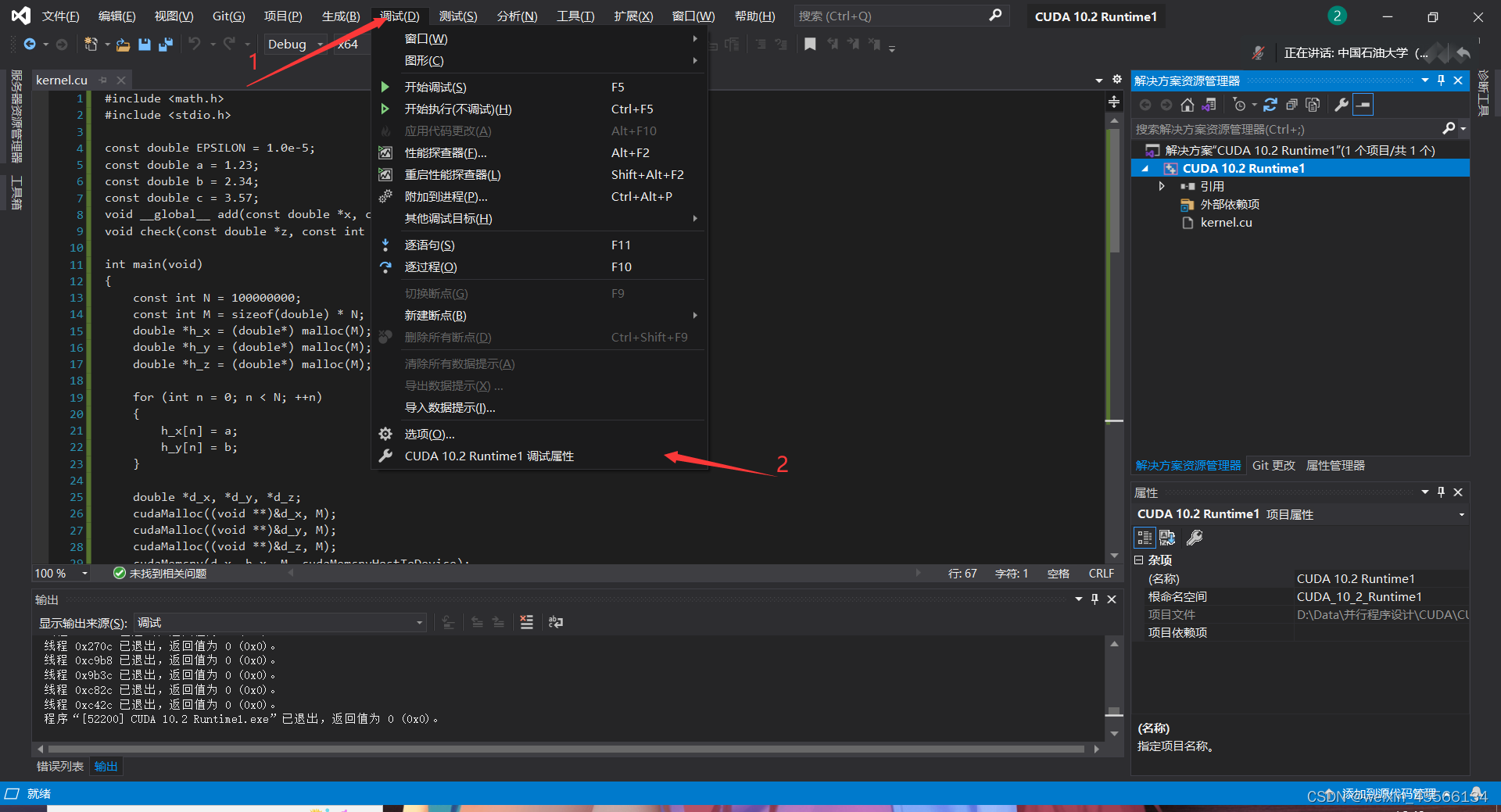
进入调试属性界面之后,点进CUDA C/C++->Common->CUDA Toolkit Custom Dir进入编辑:

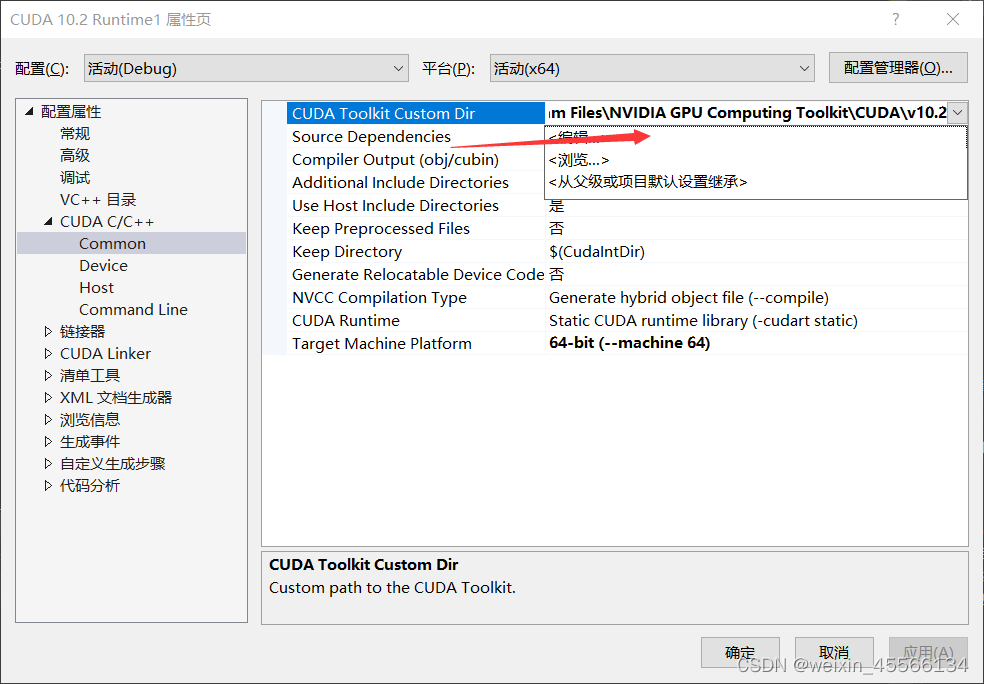
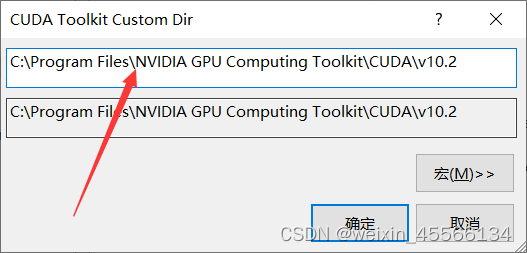
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
注意不要少了或者多了路径,最后的v10.2是我安装的CUDA版本,例如你安装的是11.0版本的CUDA,那么最后的路径相应地改为v11.0,就应该能解决问题了,希望对你有所帮助!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)