文章来源:SIGIR’20
摘要
文章基于BERT提出了一个跨模态检索模型,该模型并不是一个通用的检索模型,主要用于电商领域时尚用品(Fashon)检索,作者是阿里巴巴。
框架图

文章框架和之前基于transformer的文章网络架构大致相同,
输入
输入文本和图片,对文本取token对图片取patch
输出
[CLS]用来判断文本和图片是否对齐
训练任务
遮挡图片(文本)预测图片(文本),预测文本和图片是否匹配
Whole Word Masking (WWM)
BERT会对输入的文本进行wordpiecce操作,具体如下:
比如"loved",“loving”,“loves"这三个单词。其实本身的语义都是“爱”的意思,把上面的3个单词拆分成"lov”,“ed”,“ing”,"es"几部分,减少词表数量。
这就会导致在进行mask操作时会只对一个词进行了mask。文章采用了Whole Word Masking方法,使得可以对一个完整的词进行mask。如下所示

Masked Patch Modeling (MPM)
考虑到Fashion数据集中图片的ROI区域往往只有一个,所以不采用FAST-RCNN来提取ROI区域,而采用直接分块的方法。
Adaptive Loss
Loss1 Whole Word Masking (WWM) 交叉熵
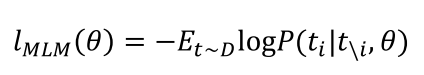
Loss2 Masked Patch Modeling (MPM) KL散度
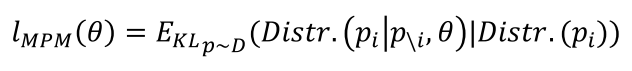
Loss3 图片文本是否匹配 二分类
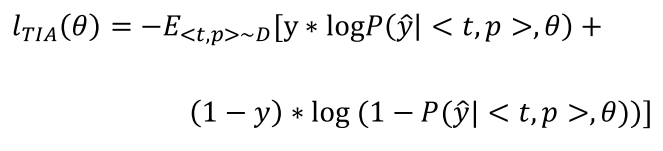
Adaptive Loss
讲上面三个loss加权求和,权重
ω
i
\omega_{i}
ωi的优化可以通过新的优化算法,基于KKT条件求得

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)