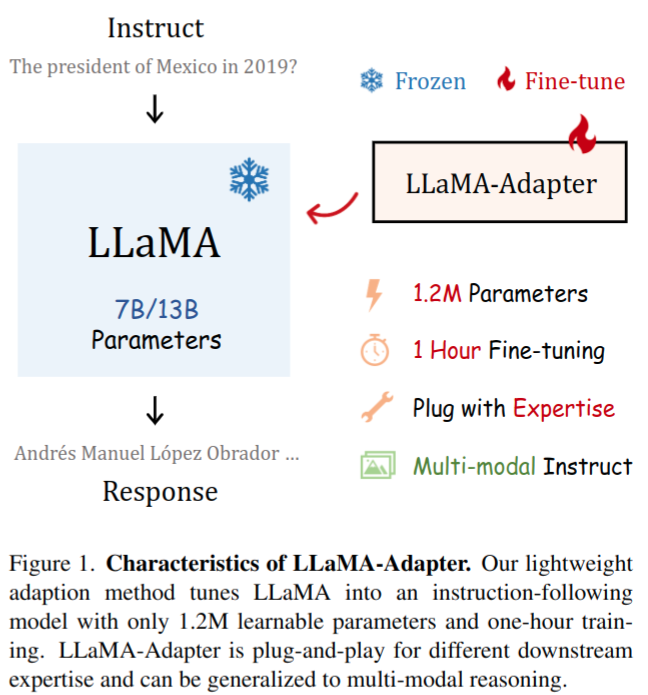
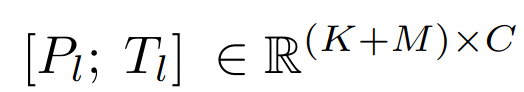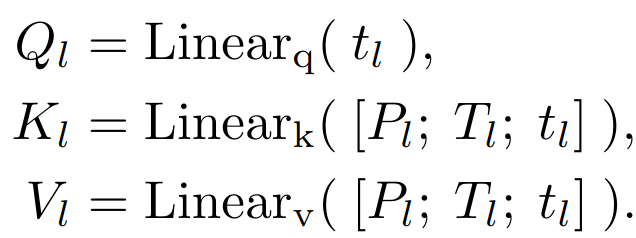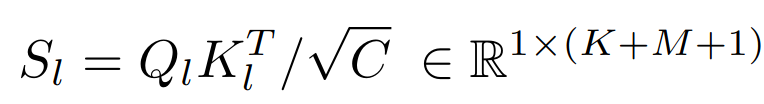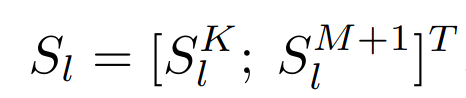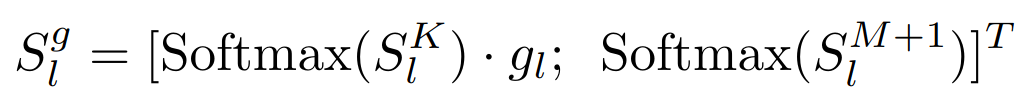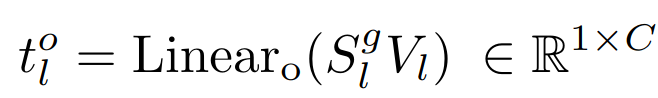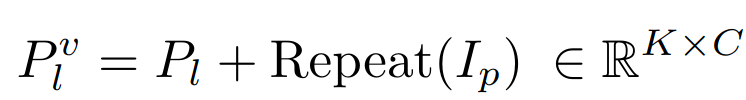将 L 层 transformer 的提示符记为
{
P
l
}
l
=
1
L
\{P_{l}\}^{L}_{l=1}
{Pl}l=1L ,其中
P
l
∈
R
K
×
C
P_{l} \in \mathbb{R}^{K \times C}
Pl∈RK×C , K 表示每一层的提示长度,C 等于 LLaMA transformer 层的特征维数
只对于深层的 L 层插入 adapter,这可以更好地调整具有高级语义的语言表示
以第 l 个插入层为例,将长度为 M 的词 token 表示为
T
l
∈
R
M
×
C
T_{l} \in \mathbb{R}^{M \times C}
Tl∈RM×C 。然后,将自适应提示符按照 token 维度作为前缀与
T
l
T_{l}
Tl 连接,表达式为: 这样
P
l
P_{l}
Pl 内部学习到的指令知识可以有效地引导
T
l
T_{l}
Tl 生成上下文响应
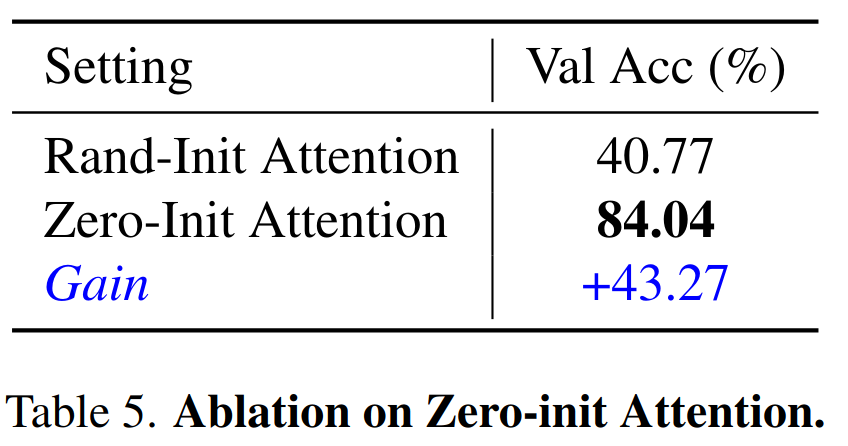
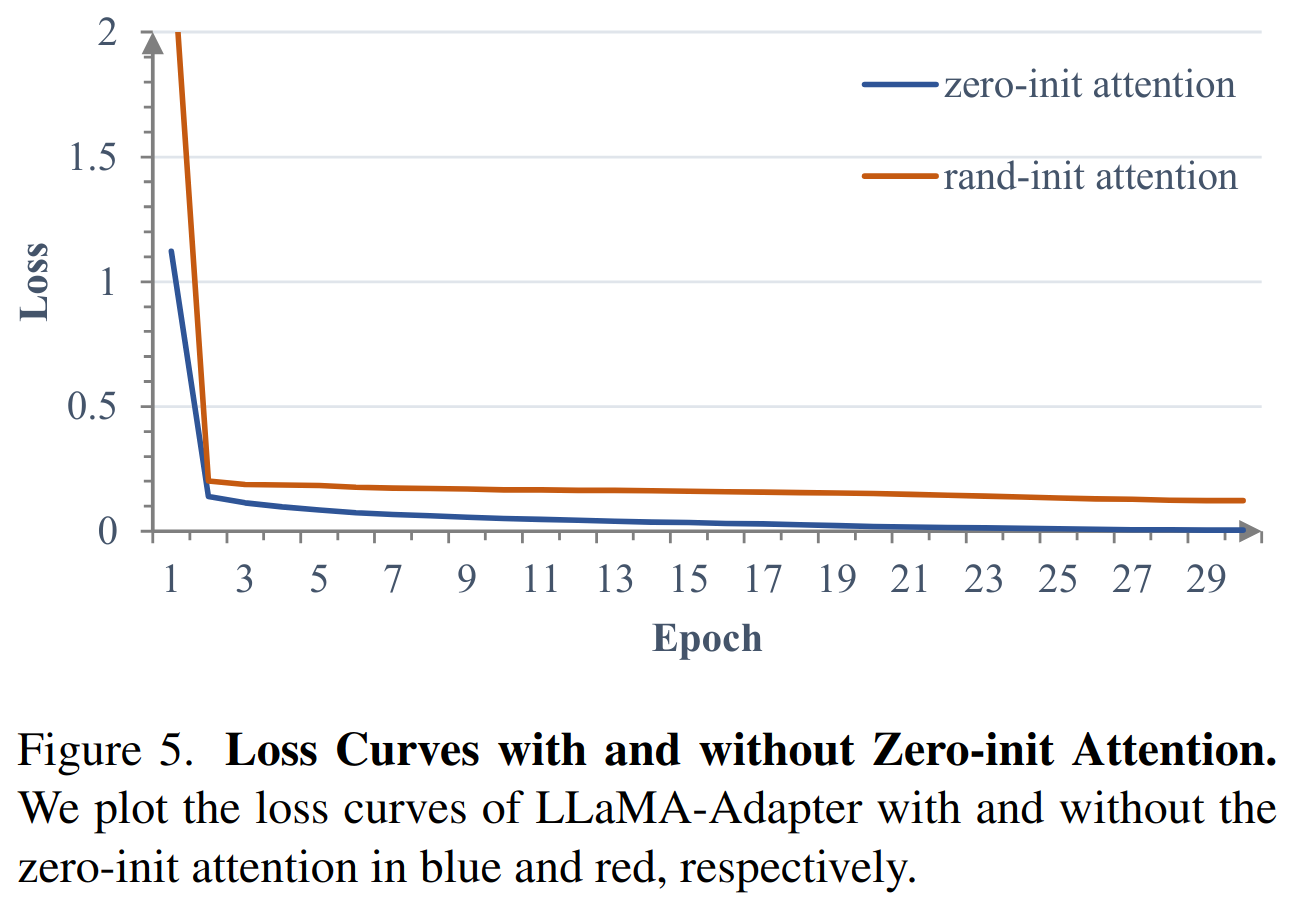
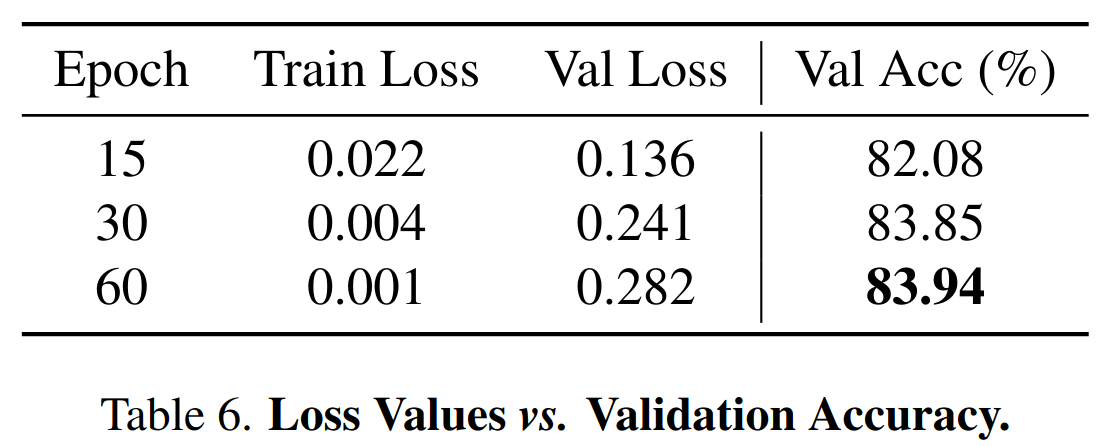
Zero-init Attention
如果适应提示是随机初始化的,可能会在训练开始时对词 token 带来干扰,不利于调优的稳定性和有效性。考虑到这一点,修改了最后 L 个 transformer 层的传统注意机制为零初始注意
假设模型基于
[
P
l
;
T
l
]
[P_{l}; T_{l}]
[Pl;Tl] 信息,在生成第 (M + 1)-th 个单词,将对应的 (M + 1)-th 个词表示为
t
l
∈
R
1
×
C
t_{l} \in \mathbb{R}^{1 \times C}
tl∈R1×C , attention 首先基于如下 linear 层对 qkv 进行计算 然后,计算softmax函数前的注意得分为 记录了
t
l
t_{l}
tl 和所有 K+M+1 token 之间的特征相似性。同时,
S
l
S_{l}
Sl 可以由两个组分重新计算为 其中
S
l
K
∈
R
K
×
1
S_{l}^{K} \in \mathbb{R}^{K \times 1}
SlK∈RK×1 和
S
l
K
∈
R
K
×
1
S_{l}^{K} \in \mathbb{R}^{K \times 1}
SlK∈RK×1 分别为 K 个适应提示和 M + 1 个词 token 的注意得分。前者
S
l
K
S^{K}_{l}
SlK 表示可学习提示符对
t
l
t_{l}
tl 的贡献,这可能会在训练早期造成干扰
为此,采用一种可学习的门控因子
g
l
g_{l}
gl ,自适应控制关注中
S
l
K
S^{K}_{l}
SlK 的重要性 单独的 softmax 函数确保第二项与添加的适应提示无关,
g
l
g_{l}
gl 训练开始会初始化为 0,然后再逐渐增大。注意力的每个头会采用不同的
g
l
g_{l}
gl 进行独立学习。最后,计算带有线性投影层的注意层的输出为