这里不过多阐述NER任务是啥了,具体来看看他的作用,并且举了一个例子,让大家理解更加深刻

、
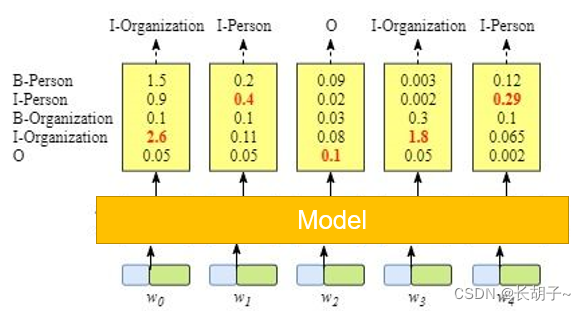
上图说明模型的输出是每个标签的分数。例如,对于w0, 模型的输出为1.5 (B-Person)、0.9 (I-Person)、0.1 (B-Organization)、0.08 (I-Organization)和0.05 (O),这些分数将作为CRF层的输入。然后,将模型预测的所有分数输入CRF层。在CRF层中,选择预测得分最高的标签序列作为最佳答案。例如,对于w0,“B-Person”得分最高(1.5),因此我们可以选择“B-Person”作为其最佳预测标签。同样,我们可以为w1选择“I-Person”,为w2选择“O”,为w3选择“B-Organization”,为w4选择“O”。虽然在这个例子中我们可以得到正确的句子x的标签,但是并不总是这样。再试一下下面图片中的例子。显然,这次的输出是无效的。因为“I-Organization I-Person”不符合我们的规则。
CRF层可以从训练数据中学到约束
CRF层可以在最终的预测标签添加一些约束,以确保它们是有效的。这些约束可以由CRF层在训练过程中从训练数据集自动学习。
约束条件可以是:
- 句子中第一个单词的标签应该以“B-”或“O”开头,而不是“I-”
- “B-label1 I-label2 I-label3 I-…”,在这个模式中,label1、label2、label3…应该是相同的命名实体标签。例如,“B-Person I-Person”是有效的,但是“B-Person I-Organization”是无效的。
- “O I-label”无效。一个命名实体的第一个标签应该以“B-”而不是“I-”开头,换句话说,有效的模式应该是“O B-label”
- …
下面是具体的一个过程
步骤1:模型的Emission和transition得分
假设,我们有一个包含三个单词(w0w1w2)的句子:标签为I1,I2
模型得到了Emission分数,从下面的CRF层得到了transition分数:

Xij表示wi被标记为lj的得分。

tij是从标签i转换成标签j的得分。
步骤2:开始推理
我们将从句子的左到右进行推理算法,如下图所示:

你会看到两个变量:obs和previous。previous存储前面步骤的最终结果。obs表示当前单词的信息。
Alpha0是历史最好得分,Alpha1是历史对应的索引。这两个变量的细节将在它们出现时进行解释。请看下面的图片:你可以把这两个变量当作狗在探索森林时沿路留下的“记号”,这些“记号”可以帮助狗找到回家的路。

现在,我们观察到第一个单词,现在,对于是很明显的。
比如,如果obs=[x01=0.2 , x02=0.8],很显然,w0的最佳的标签是l2。
因为只有一个单词,而且没有标签直接的转换,transition的得分没有用到。

- 把previous扩展成:

- 把obs扩展成:

- 把previous, obs和transition 分数都加起来:

然后:

为下一次迭代更改previous的值:

比如,如果我们的得分是:

我们的下个迭代的previous是:

previous有什么含义吗? previous列表存储了每个当前的单词的标签的最大的得分。
举个例子:
我们知道在我们的语料中,我们总共只有2个标签,lable1(l1)和lable2(l2)。这两个标签的索引是0和1。
previous[0]是以第0个标签为结尾的路径的最大得分,类似的previous[1]是以第1个标签为结尾的路径的最大得分。在每个迭代中,变量previous存储了以每个标签为结尾的路径的最大得分。换句话说,在每个迭代中,我们只保留了每个标签的最佳路径的信息,具有小得分的路径信息会被丢掉。

回到我们的主任务:
同时,我们还有两个变量用来存储历史信息(得分和索引),Alpha0和Alpha1。
在这个迭代中,我们把最佳得分加上,为了方便,每个标签的最大得分会加上下划线。

另外,对应的列的索引存在里。



 说明一下,l1的索引是0,l2的索引是1,所以(1,1)=( l1, l2)表示对于当前的单词wi和标签l(i),当路径是的时候,我们可以得到最大的得分是0.5,当路径是的时候,我们可以得到最大的得分是0.4。是过去的单词的标签。
说明一下,l1的索引是0,l2的索引是1,所以(1,1)=( l1, l2)表示对于当前的单词wi和标签l(i),当路径是的时候,我们可以得到最大的得分是0.5,当路径是的时候,我们可以得到最大的得分是0.4。是过去的单词的标签。

- 把previous扩展成:

- 把obs扩展成:

- 把previous, obs和transition 分数都加起来:

然后:

为下一次迭代更改previous的值:

这次迭代我们得到的分数是:

我们得到最新的previous:

实际上,previous[0]和previous[1]中最大的那个就是预测的最佳路径。
同时,每个标签和索引的最大得分会加到上和上。

步骤3:找到具有最高得分的最佳路径
这是最后一步!你就快完成了!在此步骤中,将使用Alpha0和Alpha1来查找得分最高的路径。我们将从最后一个到第一个的元素检查这两个列表中。


 首先,检查Alpha0和Alpha1的最后一个元素:(0.8,0.9)和(1,0)。0.9表示当label为l2时,我们可以得到最高的路径分数0.9。我们还知道l2的索引是1,因此检查(1,0)[1]=0的值。索引“0”表示前一个标签为l1(l1的索引为0),因此我们可以得到是的最佳路径是
首先,检查Alpha0和Alpha1的最后一个元素:(0.8,0.9)和(1,0)。0.9表示当label为l2时,我们可以得到最高的路径分数0.9。我们还知道l2的索引是1,因此检查(1,0)[1]=0的值。索引“0”表示前一个标签为l1(l1的索引为0),因此我们可以得到是的最佳路径是

 其次,我们继续向后移动并得到Alpha1:(1,1)的元素。从上一段我们知道w1的label是l1(index是0),因此我们可以检查(1,1)[0]=1。因此,我们可以得到这部分的最佳路径:
其次,我们继续向后移动并得到Alpha1:(1,1)的元素。从上一段我们知道w1的label是l1(index是0),因此我们可以检查(1,1)[0]=1。因此,我们可以得到这部分的最佳路径:
 我们这个例子中的最佳路径是:
我们这个例子中的最佳路径是:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)