
阿里妹导读:OCR作为智能审核的重要环节,其识别准确率影响着最终审核效果的好坏,而来自扫描仪、智能手机的文档图像多存在卷曲、折叠。本文旨在利用深度学习算法对文档图像的形变进行矫正,从而提高OCR识别效果,为智能审核保驾护航。
一、背景
随着集团业务的高速发展以及集团对用户群体信用要求的提高,证件审核成为业务中必不可少的一个环节。譬如:支付宝需要对用户的身份证信息进行审核,1688需要对卖家的营业执照进行审核。此外,还有一些业务涉及的是需要专业人士才有足够能力进行审核的信用证和保单。

近年来,人工智能在越来越多的任务中的表现已经超过了人类。如果能将AI引入审核场景,实现智能审核,将大大提高审核的效率。智能审核相比人工审核具有以下优势:
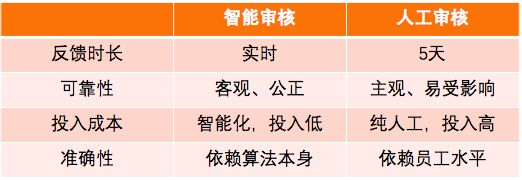
而要做到高水平的智能审核,难度颇大,需要做好以下几点:
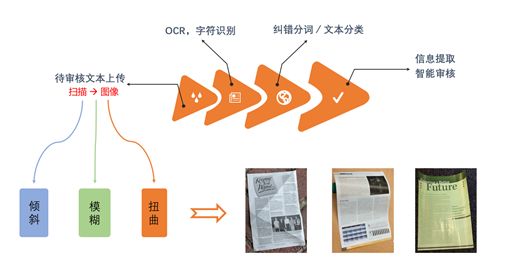
要让机器代替人去做证件审核乃至于文本审核,首先需要让机器看到人所能看到的(OCR:将文本图像转化成文本),而后才是理解人所能看到的(NLP:如纠错分词/文本分类等)。作为后面一切算法的源头,OCR算法在智能审核中起着至关重要的角色。除却算法本身,图像质量乃是影响OCR识别准确率的最大因素。一般从三个方面来衡量图像的质量:倾斜、清晰度、扭曲。而本文的目的则在于如何通过算法使得扭曲的文档图像变得平整,从而改善扭曲文档图像的OCR识别准确率,为智能审核保驾护航。
二、相关工作
2.1 传统方法
当前针对扭曲文档图像的矫正算法主要有以下三类:
该类方法通常使用特制的硬件设备扫描纸张的三维形状信息。比如采用结构光源来对文档进行扫描从而获取文档的三维信息即深度信息,然后根据深度信息对文档图像进行矫正。
该类方法主要从造成文档扭曲的因素出发,包括文档及其摆放角度、光源方向、图像获取设备特征等因素。通过对文档进行3D建模,并利用已有的数学知识对扭曲进行矫正。
该类算法摈弃对扭曲的几何模拟与3D建模,直接对文档图像进行分析,包括倾斜角、文本行、字符或词组特征等,然后设计出一种不受文档图像以外因素影响的扭曲矫正算法。此类算法的优点在于不需要清楚地知道扭曲造成的原因。
三类算法各有优点,但也都有各自的局限性,可总结为:
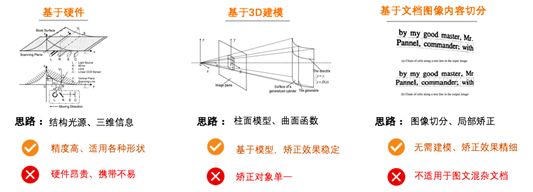
可以看出,传统方法多是针对特定场景进行建模,而一旦跳出当前场景,模型就无法起作用。随着深度学习的兴起,有学者提出用深度学习相关算法对扭曲文档图像进行矫正。
2.2 深度学习方法
随着深度学习近几年的兴起,有学者提出用语义分割相关的模型对扭曲文档图像进行建模,将像素级的分类问题转化为像素级的回归问题,实现扭曲文档图像的矫正,模型具有一定的泛化能力,可针对复杂场景下的扭曲或折叠图像进行矫正。

在刚刚结束不久的CVPR 2018中,Ke ma等人提出一种基于语义分割中U-net模型[1],利用图形学方法生成逼近真实场景的扭曲文档图像,通过这些样本集训练出可实现端到端矫正的Stacked U-net网络。
深度学习的优势在于如若有足够丰富和质量高的训练样本集,其深层网络结构令其具有一定的泛化能力,可针对多种扭曲实现矫正,跳出传统方法的场景限制。
考虑到实际业务的复杂性,传统方法无法胜任,因此本文结合深度学习语义分割领域的相关知识,针对现有方法的不足提出优化方案,实现扭曲文档的矫正。
三、数据集生成
对机器学习或深度学习有一定了解的人都知道,很多时候,数据决定着你的模型能做到什么程度。而关于扭曲文档复原,一方面当前的开源数据集较少;另一方面,我们的目标是要建立能够实现像素级别回归任务的神经网络结构,这下子,开源且标注好的数据集几乎就是没有。因此,我们参考文献[1]中的方法,自行生成数据集。
3.1 扭曲文档图像生成
扭曲又分为折叠和卷曲,利用图形学相关知识,我们通过以下步骤实现了文档的折叠和卷曲:
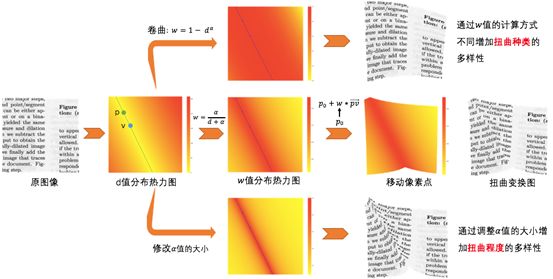
其中,卷曲和折叠的区别是的计算公式的差异:
卷曲: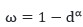
折叠: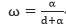
而通过调整超参数的大小,可实现不同程度的扭曲变换,如下图所示:
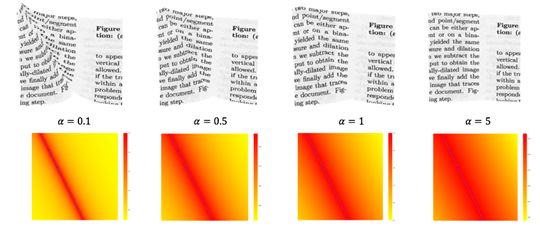
3.2数据集生成过程的问题解决
当然,在进行数据集生成的时候,也是遇到了很多的问题,比如:
样本集的标签如何生成?
生成图片时遇到空点如何处理?
首先,是样本的标签问题,我们要实现像素集的回归,则每个像素都必须有一个标签,而如何设计标签才能让网络结构更好的完成该任务呢?
我们是这么设计的:
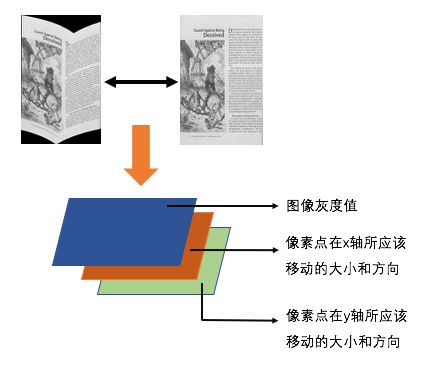
首先对比扭曲变换后的图像和原图像,得到折叠变换后的图像上的每个像素点所应该移动的位移大小和方向,然后构造一个3维的矩阵,一维用于存扭曲变换后的图像灰度值信息,另外两维用于存在x轴和y轴方向所应该移动的位移大小和方向,这样就实现了样本和标签的构造。
此外,在变换过程中,我们还发现生成的图像有一些会带有黑点或黑线,如下图所示:

上图中三幅小图分别代表变换过后的图像以及每个像素点的标签图像。我们通过分析发现,其之所以会存在黑点,是因为这个坐标下的像素是空的,而像素是空的原因是因为我们在进行变换的过程中,其实有一个取整操作,而这样的取整操作可能让原本相邻的两列像素点中间空出一列,如下示意图所示:
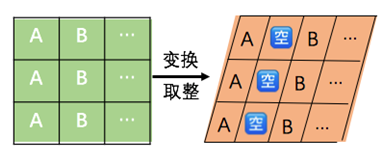
后来,我们通过最近邻插值解决了这个问题,上述存在黑点的图经过插值后得到如下变换图像:

当然,也可通过其他插值或修复方法修复这样的空白点。
解决了数据集问题,相当于解决了模型的食粮问题。那我们的模型具体长什么样呢?莫慌,下面我们将为你细细道来。
四、模型构建与优化
4.1基于U-net的扭曲文档矫正复原
我们一开始选用的是在语义分割中最为常用的U-net模型,其网络架构如下图所示[2]:
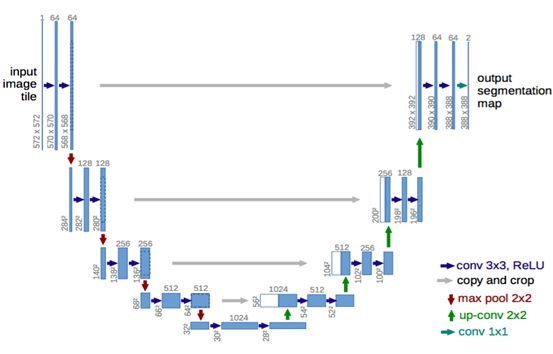
其网络架构形如字母“U”,因此被称为U-net,可以将此类神经网络理解为一个Encoder-Decoder结构,其中Encoder是收缩路径,主要是由卷积层和池化层组成,主要目的在于实现特征的提取或者说捕捉语义,而Decoder是扩展路径,主要通过转置卷积和跳跃连接实现,其主要目的是为了实现上采样,由于Pooling操作进行了下采样导致图像维度减小,而转置卷积可以让feature map的维度变大,从而恢复到原图的大小,从而实现像素级回归。但是这样得到的结果是很粗糙的,所以一般还通过跳跃连接将浅层的特征concat到upsampling之后的feature map中以实现精准定位。
但是,基于U-net模型的效果并不如我们预料的那般好:

主要是会出现诸如文字扭曲变形和行间扭曲错位这样的现象,严重的时候甚至可能出现图片撕裂现象:

为了对模型进行优化,我们需要定位问题出在哪里,因此,我们对模型的预测结果进行可视化,得到如下图:

可以发现,预测出来的标签和真实的标签虽然大体的趋势是差不多的,但都是以团状形式出现,无法像真实标签那样精确,即:分辨率不够或者说定位精度不够。因此,我们从三个角度进行模型的优化:
下面,将详细介绍每个优化步骤。
4.2基于StackedU-net的扭曲文档矫正复原
(1)修改网络结构:U-net —> Stacked U-net

stacked u-net网络结构如上所示,我们参考了论文中的Stacked结构,考虑到分辨率的问题并对其进行了改进,其堆叠了两个u-net,目的先利用第一个U-net得到一个粗粒度的预测结果,并可将其视为一种先验,而后再将预测结果和原始扭曲图concat后,再放入第二个U-net中进行实现,目的在于结合深层抽象低分辨率的特征和浅层原始高分辨率的特征,以实现细粒度的预测。
(2)改进损失函数:添加尺度不变损失
在U-net中,我们用的是如下的均方根误差函数:
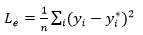
其中,y代表的是一个二维向量。但这样的损失函数容易导致字符之间出现扭曲现象,因此,我们通过添加尺度不变损失,对当前结果进行改进,希望映射之后的相对位移和它们对应的 ground truth 相对位移之间的相对误差尽可能小:
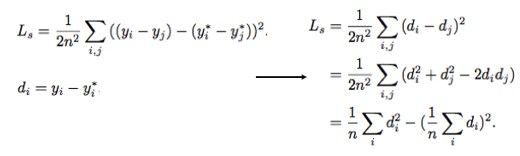
此外,我们还发现,当用如下L1 loss形式的时候会比L2 Loss得到更好的效果:
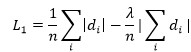
其中,乃是控制均方误差和尺度不变误差比重的超参数。
展示一下L2 Loss和L1 Loss下的效果对比:

可以看到,L1 Loss可以在细节处做到更好的效果,究其原因,可以理解为:
L2 Loss由于其函数中的平方操作更容易受到大误差值的影响,而忽略小误差值,比如在像素点A的mae误差为2,而在像素点B的误差mae为0.02,此时他们相差100倍,而在进行平方操作,像素点A误差值变为4,像素点B的误差变为0.0004,相差了10000倍,故L1 Loss可以在细节处做的更好。
(3)平滑后处理
我们发现,U-net预测出来的图像时常存在一些噪点甚至于断层、撕裂现象,为什么会产生这样的现象,究其深层的原因是由于相邻或相近的像素点理应也有相近的预测值,但如果相邻的像素点的预测值相差极大,则容易出现噪点甚至于图像断层、撕裂现象。因此,我们通过对预测出来的标签进行平滑处理,虽然简单粗暴,但也改善了这一现象:

对Stacked U-net生成的图像进行分析,我们可以发现,经过优化过后,虽然对扭曲/噪点等有一定改善作用,但文档图像还是存在一定的扭曲现象:

那到底是哪个地方我们没有做好导致这样的现象呢?我们从不同角度对U-net的定位精度、文字扭曲、行间错位、噪点现象进行改进,但StackedU-net这种网络结构虽然能在训练集上取得很好的效果,但在验证集上的效果还是不如我们的预期。也就是说Stacked U-net这种网络结构在训练集上产生了过拟合现象。那现在我们遇到了很矛盾的两个点:
这时候,我们就在思考,能否找到一种轻型的网络结构,既能保证感受野足够大,又能减轻过拟合现象?
于是,我们发现了空洞卷积(Dilated Convolution)这样的卷积方式。
4.3基于DilatedU-net的扭曲文档矫正复原
空洞卷积(dilated convolution)是指在卷积核之间注入空洞,相比于标准的卷积多了一个称为dilation rate的超参数,当dilationrate = 1时,其为标准的卷积操作;当dilation rate = 2时,则表示在卷积核的每个元素之间注入一个空洞。其示意图如下所示:
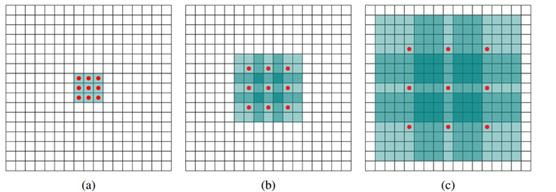
图a对应 3x3 的 1-dilated conv,和普通的卷积操作一样。
图b对应 3x3 的 2-dilated conv,实际的卷积kernel size还是3x3,空洞为1,可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到 7x7。
图c是4-dilated conv操作,同理跟在两个1-dialted conv和2-dialted conv的后面,能达到 15x15 的感受野。
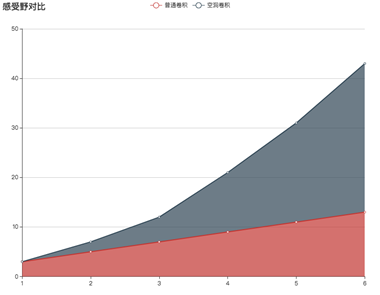
对比传统的conv操作,3层 3x3 的卷积加起来,stride为1的话,只能达到(kernel - 1) * layer + 1 = 7的感受野,也就是感受野和层数layer成线性关系,而dilated conv的感受野也是呈指数级的增长,如下图,代表分别堆叠6层普通卷积和空洞卷积时的感受野对比情况:
dilated conv的好处可以总结为:
基于Dilated Convolution和U-net的网络架构,我们设计了如下结构的Dilated U-net:
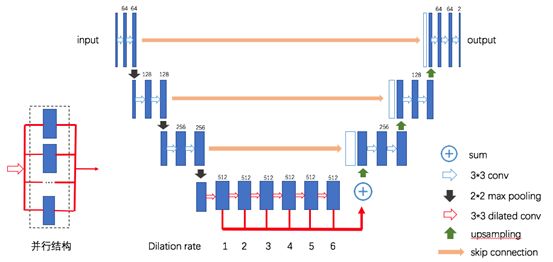
其中,我们基于空洞卷积分别设计了并行多尺度空洞卷积U-net结构和串行多尺度空洞卷积U-net结构,其中串行的结构表现更佳,原因是因为其串行叠加后,就类似于串级放大器般增大感受野,让每个像素点可以看到周边更多像素点的信息,从而得到更为精确的结果。
对比其他模型与Dilated U-net模型,我们可以得到如下图所示的结果:
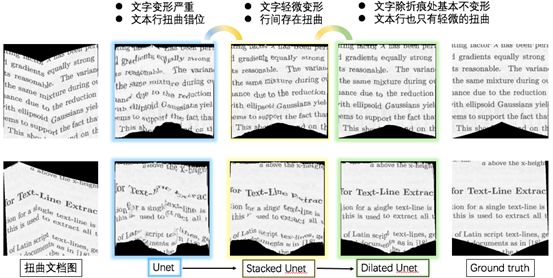
可以发现,在Dilated U-net模型的矫正下,矫正后的文档图片基本上只有轻微的扭曲和变形。
五、模型评价
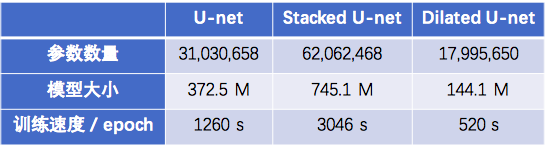
5.1 模型基本参数对比
总结各个模型,首先看下各个模型的参数和模型大小的对比:
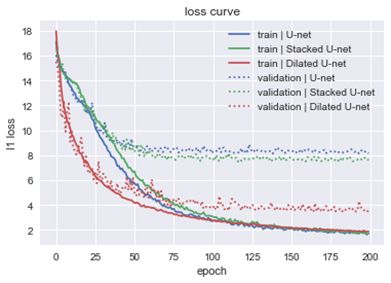
再看看各个模型在训练集和验证集上的loss curve:
L1 Loss
L2 Loss
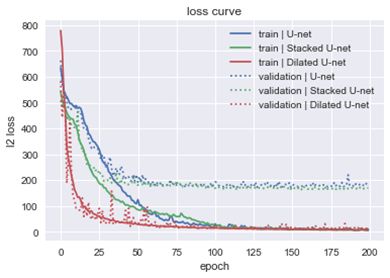
其中,实线代表的是在训练集上的效果,虚线代表的是在验证集上的效果,可以发现无论是U-net还是StackedU-net,其在训练集和验证集上的loss都存在较大的差异,也就表面模型存在过拟合,而Dilated U-net过拟合的情况就会好很多。
因此,我们可以发现,Dilated U-net不仅参数量少,训练速度快,而且精度更高,真是应了那句“less is more”的至理名言。
5.2 模型评价
在最后的模型评价中,我们采用MS-SSIM指标对矫正前后的图片相似度进行评价,MS-SSIM全称为Multi-ScaleStructural Similarity,顾名思义,其是多尺度下的SSIM(结构相似性)的汇总。
要计算MS-SSIM,得先计算SSIM,SSIM是一种衡量两幅图像相似度的指标,其计算思路是将人类主观感知纳入考量:
在非常亮的区域,失真更难以察觉。(luminance, 亮度)
在“纹理”比较复杂的区域,失真更难以察觉。(contrast, 对比)
空间上相邻的像素之间形成某种“结构”,而人眼对这种结构信息很敏感。(structure,结构)
具体而言,SSIM通过以下公式测度以上三者:
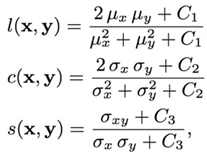
SSIM考虑了亮度、对比、结构因素,然而,还有一个主观因素没有考虑,分辨率。显然,在不同分辨率下,人眼对图像差异的敏感程度是不一样的。比如,在高分辨率的视网膜显示器上显而易见的失真,在低分辨率的手机上可能难以察觉。因此,后来又进一步提出了MS-SSIM指标,即多尺度(Multi-Scale)SSIM。对图像进行降采样处理,在多尺度上分别计算对比比较和结构比较,最后汇总多尺度上的SSIM分数,其计算过程如下示意图所示:

其计算公式为:
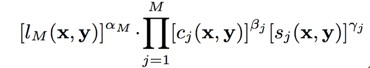
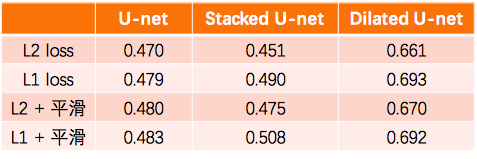
在训练集和验证集之外,随机生成100张扭曲变换的图片作为测试集,从而利用MS-SSIM指标对各个模型的矫正效果进行评价,最终,各个模型的MS-SSIM得分如下:
这样看可能不是很直观,让我们用柱状图展示一下结果:
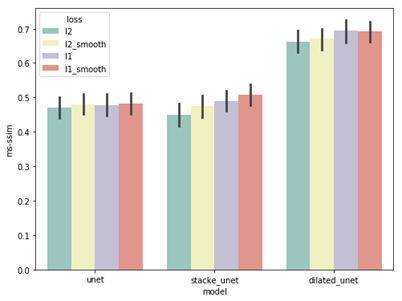
从上述图表中,我们可以得出如下结论:
六、后续展望
本文旨在对扭曲文档图像进行矫正,基于图像语义分割领域的U-net模型,将扭曲文档图像矫正问题转化为像素级别的回归问题,针对模型结果中出现的文档扭曲错行以及预测结果分辨率不足等问题,参考前沿文献,实现了Stacked U-net并提出了相应的优化算法模型DilatedU-net,虽然能够在简单场景下得到不错的效果,但仍然存在一定的不足,具体可描述为以下几点:
数据集:为了解决标注问题,目前的数据集是参考图形学的相关知识自行构造而成,导致神经网络能学到的知识有限,一旦遇到自然场景中的复杂问题,神经网络的性能将受到限制。因此,后续研究中,一方面可增加自然场景中的数据集;另一方面,可引入生成对抗网络的相关知识,让模型更具泛化能力。
神经网络结构:目前的神经网络结构Dilated U-net相对于Stacked U-net,虽然更轻型且训练速度更快,但最终若要实现网络模型在移动端的部署,其响应速度仍然存在优化之处。
此外,可尝试DeepLab相关的网络模型以及基于CRF的后处理方式等以提高预测精度。
关于我们
我们是新零售增值业务技术团队,旨在用科技的力量,为中小微贸企业提供在贸易和供应链场景下的金融,风控,信用,保险等增值服务。通过链接中小企业和金融机构,运用新技术、大数据和平台优势,让无数中小微企业能够从银行获取到只有大型企业才能得到的服务,为无数中小企业提供高效,安全,低成本的金融服务,让企业的信用转化为财富。
欢迎加入增值业务技术团队!团队业务处于高速增长期,长期招聘算法模型和JAVA开发同学,有意向欢迎邮件至jinghua.fengjh@alibaba-inc.com
参考文献:
[1] Ma K, Shu Z,Bai X, et al. DocUNet: Document Image Unwarping via A StackedU-Net[C]//Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 2018: 4700-4709.
[2] RonnebergerO, Fischer P, Brox T. U-net: Convolutional networks for biomedical imagesegmentation[C]//International Conference on Medical image computing andcomputer-assisted intervention. Springer, Cham, 2015: 234-241.
[3] Yu F, KoltunV. Multi-scale context aggregation by dilated convolutions[J]. arXiv preprintarXiv:1511.07122, 2015.
[4] Wang Z,Simoncelli E, Bovik A. Multi-scale structural similarity for image qualityassessment[C]//ASILOMAR CONFERENCE ON SIGNALS SYSTEMS AND COMPUTERS. IEEE;1998, 2003, 2: 1398-1402.

你可能还喜欢
点击下方图片即可阅读

《码出高效:Java 开发手册》正式发布

达摩院一年香,阿里CTO张建锋公布了哪些成果?

这是从云栖大会现场发来的报道

关注「阿里技术」
把握前沿技术脉搏