问题描述
在Ubuntu18.04上编译安装支持CUDA(11.2)版本的OPENCV4.3.0的时候,出现了如下的报错
下面展示一些 。
**CMake Error: The following variables are used in this project, but they are set to NOTFOUND.
Please set them or make sure they are set and tested correctly in the CMake files:
CUDA_nppicom_LIBRARY (ADVANCED)
原因分析:
这个问题我解决了一天,参考了网上很多教程:
链接1:https://blog.csdn.net/u014613745/article/details/78310916
链接2: https://stackoverflow.com/questions/46584000/cmake-error-variables-are-set-to-notfound
但是都没有解决,这些好像都是针对CUDA_nppi_LIBRARY (ADVANCED)这个问题的。总体就是说由于CUDA9以后就去掉了nppi,分成了很多小的部分,但是对于我来说不管用!
链接3:https://blog.csdn.net/dawn_chen121/article/details/82828629
这个可能有用,是我解决完之后才看见的,有问题的小伙伴可以试试
解决方案:
直到我查了一天,偶然看到一个这个:https://stackoverflow.com/questions/62297025/build-opencv-4-0-0-with-cuda-11-on-ubuntu-18-04。
里面有这样两条评论:
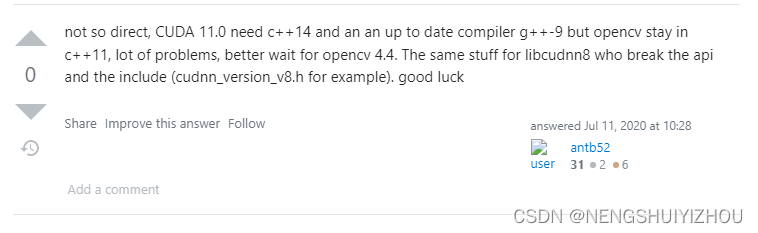
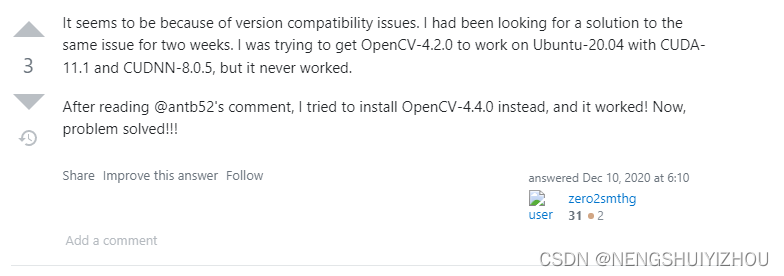
老铁们,我就放弃了安装opencv4.3.0,开始安装opencv4.4.0。成了!!!!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)