摘要
全局定位是SLAM的核心要素。基于外观的方法虽然很成功,但是在视觉条件随时间变化很大的环境中仍然面临许多开放的挑战,随着时间的变化,外观会发生巨大的变化。 在本文中,我们提出了一种集成解决方案,以利用物体级别的密集语义和对环境的空间理解进行全局本地化。 我们的方法使用3D密集语义,语义图及其拓扑对环境建模。 然后,该物体级表示用于通过语义对象关联进行位置识别,然后通过语义级点对齐进行6自由度姿势估计。
大量的实验表明,我们的方法可以在极端外观变化下实现强大的全局定位。 它还能够应对其他挑战性场景,例如动态环境和不完整的观察。
I. INTRODUCTION
对于许多现实世界中的机器人来说,长期的自主导航是一项至关重要的功能。 这需要机器人来处理场景变化,以便随着时间的推移稳固地定位自身。 尽管基于视觉的定位问题与位置识别,闭环检测以及同时定位和地图绘制(SLAM)密切相关,已经有多很多的研究,但仍存在许多开放性挑战。
基于外观的全局本地化方法将环境建模为在建图期间捕获的图像的数据库。 然后,可以通过从数据库检索图像并计算和获得的环境观察信息的相对变换来对进行定位。 这种方法通常使用词义(BoW)描述符[1]来表示图像,这些词是根据局部特征[2] – [4]构建的。 当数据库和查询图像描述相似条件下的场景时,许多最新的SLAM算法[5] – [9]都可以显示准确的定位。
尽管取得了显著成果,但大多数现有方法仍受到许多现实世界挑战的影响。 例如,季节性或天气变化,自然或人工照明变化以及新的静态对象或动态元素的出现会极大地改变场景的外观和相关特征。在终身导航的背景下,基于视觉外观的鲁棒定位至关重要,但仍然是一个难题。 另一方面,在密集的地图中包含丰富的语义信息可能会提高定位的鲁棒性。 这是因为,类似于人类的感知,语义本质上是外观变化的不变性。例如书桌会保持它的语义而和夜间还是白天采集图像无关。此属性使它们成为定位任务的可靠地标。 近年来,许多地点重识别和全局定位的工作都在探索采用与环境的语义描述关系更紧密的高级视觉特征[10]-[17]。
在本文中,我们研究了如何在3D中利用对象级语义信息来实现基于视觉的全局本地化。我们的主要贡献有三点:
1、我们创造性地将有关密集语义[9],[18],[19],3D拓扑[14],图匹配和3D对齐[20]的现有技术集成到一种新颖的对象级全局定位算法中。 它在6自由度全局本地化方面实现了最先进的性能。
2、我们证明了对象级语义信息在不使用常规特征描述符的情况下有利于鲁棒的位置识别和全局定位。 它对照明变化,场景变化等具有鲁棒性。
3、我们证明了对象级对齐可以处理具有挑战性的3D点对齐,即使观测不完整也可以实现精确的定位。
我们在公开可用的数据集和收集的数据集上评估我们提出的方法,以验证其性能。
II. RELATED WORK
A. Traditional Approaches
基于BoW [1]技术的视觉特征匹配已应用于许多现有的定位框架中,例如,基于快速外观的MAPping(FAB-MAP)[5]。 这些方法使用根据局部不变特征(例如SIFT [2],SURF [3]和ORB [4])构建的紧凑描述符来表示图像,每个图像都与一个位置相关联。 然后,将全局拓扑定位转化为图像检索问题。 这些方法在相似的感知条件下已经建立了令人印象深刻的结果。这些方法的后续进一步结合了空间信息,例如建立空间字典和地标共视图,以减少感知混叠[21]-[24]。
6自由度相机姿势可以通过查询和全局地图点之间的2D-3D或3D-3D特征匹配并解决Perspective-nPoint问题来获得,以进行精确定位。[25] 但是,当场景外观存在强烈变化时,这些依赖局部(点)特征的方法可能无法稳固地定位。 相比之下,我们提出的方法使用高级语义而不是局部特征来计算6自由度相机姿势。
B. High-Level Features for Localization
为了更好地应对外观变化,最近的研究已转向采用高级视觉提示。例如,An等。 [26]提出了一种语义辅助的概率模型来丢弃城市动态环境中的模棱两可的局部特征。 Snderhauf等。 [27]将图像中的显着区域作为高级地标,并使用卷积神经网络(CNN)的内层输出作为其特征。 Cascianell等。 [16]扩展了Snderhauf的工作,包括了共视图[21],以将环境建模为视觉地标的结构化集合。
Yu等人以类似的方式代替了基于RGB的区域建议[28],利用聚类点云,将具有相似曲率的表面组合为高级地标。 Dube等。
[29]还通过使用群集的3D LiDAR分割和全局形状描述符解决了环路闭合检测问题。
也有工作探索了基于物体功能的定位。 一种流行的趋势是结合基于图像的对象检测[15],[30]。 其他尝试,例如[10],通过将基本形状的预定义原始内核补丁与密集的3D全局地图进行卷积来检测对象。 随着基于学习的语义提取方法的最新进展,Gawel等人。 [14]使用CNN进行语义分割以获得语义查询和全局地图,然后基于对象的拓扑构建描述符。 McCormat等。 [19]结合最新技术的SLAM和语义分割CNN,通过概率融合来自不同视角的多个语义预测来构建一致的语义图。 最近,McCormac等人。 [31]应用实例分割来构造6-DoF对象姿态图,通过对物体执行跟踪,重新定位和闭环检测进一步实现SLAM。
C. Graph Matching
在将位置表示为视觉对象的结构时,一些文献选择了图结构示来描述对象及其拓扑[10],[14],[28],[32]。 因此,位置之间的相似性降低到测量其图之间的成对相似性。 图匹配可以作为一个分配问题[10],[28],[32],解决两个图的节点和边之间的精确对应关系。 不幸的是,以这种方式解决问题通常是NP难的[33]。
或者,不精确的图匹配不会显式求解成对的对应关系。 例如,图可以通过其邻接矩阵来概括,以捕获重要的拓扑属性;例如, 因此,图匹配简化为测量矩阵相似度[34],[35]。 其他人则尝试使用基于行走的图形内核来解决图形匹配[14],[36]。 在[36]中,作者计算了步行组成节点和边缘之间的成对相似度,并计算了场景建模问题的最终匹配分数。 另一方面,诸如[14]的其他比较每个节点的随机游走描述符,其中每个描述符编码对应节点的本地连通性。在我们的工作中,我们还将场景表示为语义图,并实现了受[14]启发的随机游走描述符版本。
III. GLOBAL LOCALIZATION WITH OBJECT-LEVEL SEMANTICS AND TOPOLOGY
在本节中,我们介绍了我们的全局定位框架。 该方法从查询RGB图像,深度图和语义分割中构建基于对象的语义图。 根据语义图,我们通过在查询和全局场景之间匹配随机游动图描述符来关联对象节点。 然后执行对象关联和对齐以获得相对于全局地图的6自由度相机姿态。 图2总结了所提出的方法。
![图2:建议的方法概述。 我们的方法采用3D全局地图(以及其RGB关键帧和姿势),查询RGB-D流和外部测距法作为输入。 然后进行语义分割和融合,以建立全局和查询语义图。 接下来,从各自的地图中提取全局和查询语义图,并为图中的所有节点获取基于[14]的随机游走描述符。 我们将每个查询图的随机游历描述符与全局图的随机游历描述符进行匹配,以找到最佳的对应关系。 最后,将关联的对象密集对齐以估计全局地图中查询的相对6自由度本地化。](https://img-blog.csdnimg.cn/20200504163727844.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzIzNDE4MDgx,size_16,color_FFFFFF,t_70)
图2:方法概述。 我们的方法采用3D全局地图(以及其RGB关键帧和姿势),RGB-D流和外部测距法作为输入。 然后进行语义分割和融合,以建立全局和语义图。 接下来,从各自的地图中提取全局和查询语义图,并为图中的所有节点获取基于[14]的随机游走描述符。 我们将每个查询图的随机游历描述符与全局图的随机游历描述符进行匹配,以找到最佳的对应关系。 最后,将关联的对象密集对齐以估计全局地图中查询的相对6自由度本地化。
A. Semantic Segmentation and Fusion
为了通过对象语义解决全局定位问题,需要一个全局语义图。 在这项工作中,全局地图是在根据稠密SLAM算法构建的,然后添加语义特征。 与[19]中描述的贝叶斯概率框架相似,我们的方法通过应用简单的投票方案简化了融合步骤。 在地图中,从不同角度被视为相同语义类别的点具有正确标记的置信度更高。随后一系列不同关键帧角度观察同一个点将最终收敛并导致这个点的标签具有更高的置信度。 将关键帧图像中的所有语义融合到3D地图中后,我们为每个3D点分配获得最高投票的语义标签。 在最终的语义图中,我们仅保留随着时间的流逝而获得高度一致的语义标记的点。
为了定位新查询输入,我们应用了与先前描述的从一系列输入中创建局部语义地图相同的语义融合技术, 具体来说,每个查询图都是由少量连续帧构成的,比全局图小得多。
B. Graph Extraction
在获得3D语义图(全局或查询图)后,我们将该图转换为其语义图表示形式。 为了在图上添加物体节点,我们首先从语义图中使用欧几里得聚类[37]提取具有相同语义标签的附近点。 省略了“墙”,“地板”和“天花板”类,因为它们没有引入有用的拓扑关系。 在图中。 我们选择一个边界球体来表示每个对象,因为球体具有旋转不变的隐式属性。 球体的大小(表示物体的尺寸)是最远点距群集中心的距离。
物体节点和边用于描述地图的3D语义拓扑。 在邻近距离内的任何两个对象节点之间形成无方向的边。 我们还定义了两个边界球相互交互的节点总是形成边,,无论距离有多远,这隐式地模拟了空间和尺寸关系。
图3示出了语义图的示例。
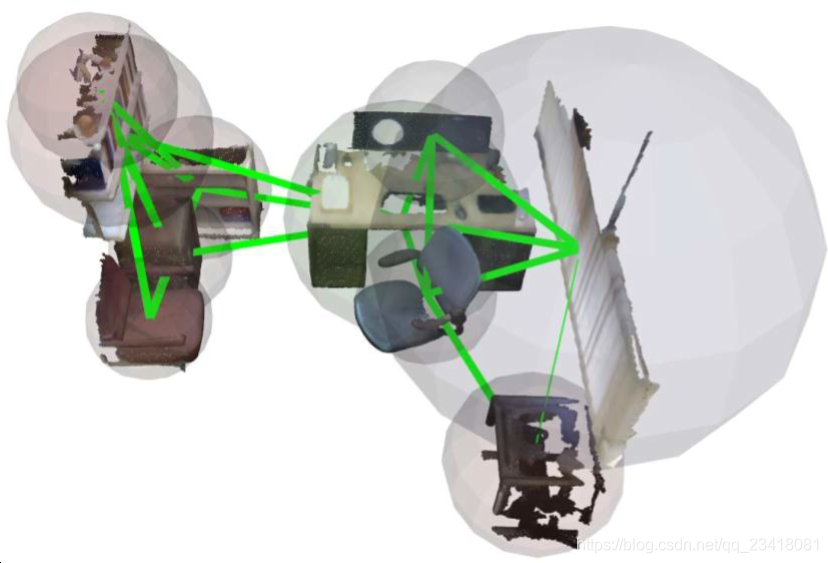
图3:从3D语义图中提取语义图(SceneNN [38]序列25)。 每个球体代表一个对象。 绿线表示3D对象/语义拓扑。
C. Random Walk Descriptors
受[14]中简单图描述符的启发,我们用随机游走描述符描述了语义图中的每个节点。 从根节点开始,每个随机步行者都会探索其连接的相邻节点并按顺序记录访问的标签。每次探索的深度由走动的步长决定,探索的数值由节点的特定描述子的大小决定。这个简单的描述符隐式编码对象及其邻居的拓扑。 图4举例说明了随机游走描述符。 在描述符中,除了访问标签外,我们还跟踪图形中每个标签的对应节点,以验证关联步骤中的空间一致性。
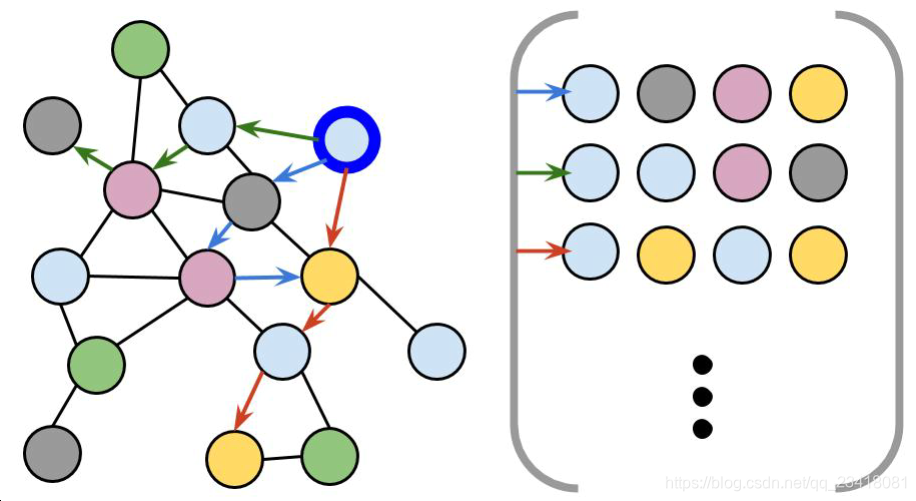
图4:随机游走描述符的二维示意图。
随机步行者从根节点(粗边框)开始探索其周围环境并记录访问节点的语义标签。 该示例演示了长度为4的步行。
D. Object Association
为全局图和查询图构建了随机游走描述符后,我们将根据它们共享的相同随机游走描述符的数量在它们的节点之间执行关联。这意味着将仅将相同语义类的对象关联。 在存在相同语义类别的多个对象的环境中,两个描述符之间的匹配仅建议一个潜在的候选者。 找到匹配项后,我们将追溯相应的节点,并在此步行路线上执行空间一致性验证。如果两个游走路径具有相同的访问标签,但是节点间距离(任意两个节点之间)超过了阈值距离,则不将描述符视为匹配项。最后,对于任何查询节点,都会计算与每个全局节点匹配的描述符的数量。 具有最多共享描述符的前k个全局节点被视为匹配项,并且查询和全局地图中的相应对象被关联。 我们允许不精确的关联,以应对对象可能被过度分割且其所有片段都需要与另一张地图中的单个对象相关联的情况。
E. Localization based on Object-Level Alignment
在将查询对象与全局地图中的对象相关联之后,我们利用对象的几何形状进行姿势估计。这是通过将查询和全局地图中的相关对象点云的集合密集对齐来实现的。
为了执行密集对齐,我们使用快速点特征直方图(FPFH)和样本共识初始对齐方法(SAC-IA)[20]来注册关联的对象点。当满足最小百分比的正确对齐点时,将接受对齐结果和估计的变换。 估计的转换给出了初始对齐方式,以在地图内定位查询对象。最终,通过迭代最近点算法(ICP)[39]完善了这种变换,从而得出了最终的6自由度查询相机姿态估计。
IV. EXPERIMENTAL RESULTS
在本节中,我们将根据公开的RGBD基准评估我们的方法,并使用Kinect v2传感器收集我们的数据集。 我们证明了使用3D语义拓扑和对齐方式的方法即使在剧烈的光照变化下也可以实现强大的全局定位。
A. Dataset
我们实验的第一个数据集是公共SceneNN数据集[38]。 它包括许多不同类型,规模和家具的室内序列。 每个序列都提供全序列RGB帧,深度图,地面真实像素级语义分类和6自由度相机姿势。 语义类的数量和类型在序列之间有所不同。在我们的实验中,我们使用序列21和25分别代表典型的办公室和卧室环境。
为了评估我们的方法而不假定地面语义分割和捕获基准通常不提供的场景更改,我们收集了以客厅,厨房和饭厅(也称为“ LKD”)为特征的数据集。 该数据集包括在不同光照条件下拍摄的几个序列以及场景中家具的重新放置。 白天序列是在强烈的日光下收集的,而夜间序列是在黎明时在明显不同的光照条件下收集的。 当天也收集参考序列。对于我们收集的数据集,我们使用金字塔场景解析网络(PSPNet)获得语义分割[18]。 我们使用现成的预训练模型,而无需进行进一步的再训练或细调。
B. Experimental Setup
为了在现实的本地化场景中评估我们的方法,我们首先构建全局语义图,在不同时间收集的每个语义查询都将从该语义图用于查询姿势估计。 在SceneNN中,每个序列都有很少的循环来演示重新访问的次数。 因此,我们通过注册每20个RGB帧来构建全局语义图,并将其语义分段投影到相对于全局图参考的3D空间中。 我们从相同的顺序生成查询,同时避免全局映射中已使用的任何帧。 生成的每个查询的帧数明显较少,而任意两个帧之间的间隔较小。 值得一提的是,SceneNN最初为场景中的每个对象提供了实例级别的分割(即唯一的对象ID)。 我们的方法只需要对象级别的分类。 因此,我们不会利用此先验知识。
对于收集的LKD数据集,我们首先使用参考序列上的RGB-D SLAM RTABMap [9]构造绘制全局地图。 我们应用PSPNet和第III-A节中描述的语义融合技术来获取全局语义图。 在没有使用groundtruth姿势来评估查询的本地化性能的情况下,我们在查询序列上使用RTABMap生成关键帧和groundtruth 6自由度姿势。 因此,为了形成查询图,我们从这些关键帧进行注册并执行语义融合。
C. Segmentation Performance
我们的PSPNet模型已在ADE20K数据集[40]上进行了预训练,该数据集包括150个室内和室外课程。 为了防止过度分割,我们通过将相似类型的类分组将原来的150个类重新映射为40个类。 合并的类别包括主要的室内家具(例如,沙发,橱柜和书桌等)。
我们定性评估融合后语义图的标签一致性。 特别是,我们检查了照明变化对语义映射的影响以及所提出的投票方法的执行情况。 图5显示了我们收集的序列中的几个查询语义图。 与相应的RGB图像相比,融合后的语义图在场景中的主要对象(例如茶几,沙发和厨房中的两个大橱柜)上表现出明显更高的一致性。 这种一致的标记还使对象能够保留其密集的几何形状。真实的segmentations可用,因此不需要在SceneNN上进行语义融合。
D. Localization Performance
这部分内容比较粗略
我们通过将查询姿态估计与真实进行比较,以位置和方向来评估全球定位性能。 每个查询图均由9帧构成。 根据查询的中心帧评估定位性能。我们应用从真实姿势(由SceneNN或RTABMap提供)、实时数据(从外部里程计获得)的相对变换,来向查询图中注册多个帧。
??,这里是什么意思 ,有些不明白,这里是构建查询图么?那么怎么还有真实值和外部里程计的变换?
另外,我们采用[14]建议的4的步行长度,以防止在查询图中的相同几个节点之间跳跃更深的步行,同时继续在更大的全局图中探索新的节点。 最后,我们使用欧几里得距离作为性能指标。
这里省略了部分图的内容,可以查看原文
图7描述了当SAC-IA路线的内部阈值固定为75%时,所有测试数据集的精度分布。 通常,由于大多数错误偏向较低范围,因此SceneNN数据集中的定位结果优越。 具体来说,大多数平移和方向误差分别小于0.25米和10度。 图6显示了已成功定位到SceneNN的全局地图中的查询示例。 表I显示了所有数据集的平均定位精度。可以看出,所有数据集的平均平移和方向误差为8.54 cm和7.74度。 特别地,所提出的算法在包括昼夜之间剧烈的照明变化的LDK-Day-Night序列上实现了良好的全局定位性能。
我们将进一步研究在LKD数据集上利用语义进行位置识别和全局本地化的好处。 我们的方法与其他两种方法进行了比较:FAB-MAP和NetVLAD [41]。 许多现有的SLAM框架都采用了基于BoW的前者,并将其用作基准算法。 后者依赖于CNN深层特征,这些深层特征是通过在不同观看和照明条件下描绘相同地点的图像训练的。 我们运行了在Pitts30k数据集[43]上训练的NetVLAD [42]的TensorFlow实现。即使我们收集的序列包含室内场景,
精确调用曲线如图8所示。所有方法在LKD-Day-Day序列上均表现出色,其中不存在明显的外观,其中NetVLAD在性能上优于其他方法。 但是,如果在昼夜情况下进行位置识别,即将夜间查询与白天全局地图匹配,则由于外观和照明的重大变化,FAB-MAP和NetVLAD的性能都会急剧下降(请参见 图5)。 尽管NetVLAD经过培训可以抵抗室外环境中的强烈外观变化,但是该模型的通用性不足以在照明和场景类型同时急剧变化时做出正确的预测。 相比之下,我们提出的语义方法仍然保持鲁棒性,并且达到与Day-Day情况相似的性能,这证明高级语义信息对于鲁棒的位置识别可能是有益的。
E. Discussion on Challenging Scenarios
基于外观的方法在应对场景发生急剧变化的现实世界场景时面临困难。
相反,我们的实验结果表明,即使在具有挑战性的感知条件下,封装了高级场景拓扑的语义表示也可以充当可靠的界标。 此外,我们的方法还可以很好地应对以下挑战:
1)不完整的视图:查询观察仅捕获环境的部分区域。 另外,语义分割也有一定程度的错误标记。 以上两个因素均导致查询段不完整,通常与存储在全局地图数据库中的完整视图冲突。 然而,我们的方法使用高级图捕获语义拓扑,该图隐式忽略了查询和全局对象关联期间丢失的细节。 此外,我们选择同时密集对齐多个关联对象,这鼓励了SAC-IA查找正确的转换,以正确对齐多个不完整对象及其完整对应关系。
2)动态场景:在动态环境中,每个查询都可以显示全局地图的某种程度的变化。
包含或排除任何新的或现有的元素都会改变基本功能,从而为基于外观的方法带来困难。 使用高级语义,我们的方法可以轻松忽略动态对象,而仅考虑静态对象以进行可靠的本地化。 例如,通常保留大型家具,例如沙发,而诸如椅子之类的其他家具则经常被搬迁。 图9中同时存在不完整查询观察和动态场景这两种情况,我们的方法成功地处理了这两种情况。
V. CONCLUSIONS
结论我们提出了一种新颖的全局定位方法,该方法利用密集语义,3D拓扑和语义级别对齐来估计6自由度相机的姿态。 我们在公众和收集的数据集上评估了我们的方法,其中光照变化很大。 我们的方法展示了在严重影响外观的剧烈变化下的高精度和鲁棒性。 此外,我们指出了该方法的优势和潜力,可以应对更多实际挑战。 虽然仅在室内场景中进行了试验,但经过适度的修改后,我们的方法可以扩展到室外应用。 我们相信,我们的方法将进一步解决与人类对世界的感知和反应方式更加一致的长期定位问题。
致谢这项工作得到了EPSRC机器人技术和人工智能ORCA集线器的部分支持(授权号EP / R026173 / 1)
记录
这个内容的实质相当于使用物体为节点的图结构进行一个初定位,然后使用这个初定位应用ICP来获得精确的定位。所以可以看作是一个初定位方法。使用图结构提取 了环境信息。这个初定位方法可以处理环境光照或者外观变化剧烈、遮挡 的情况。
这里是需要使用RGB-D数据来制作的点云全局地图,需要事先采集数据进行预处理。
图结构的提取也是从具有语义信息的点云中聚类得到的。
同时RGB-D也限制了室外的使用场景,原文说可以经过修改可以扩展到室外,但是应该需要新的传感器吧,比如激光雷达?
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)