DDR扫盲—-关于Prefetch(预取)与Burst(突发)的深入讨论
原文转自:DDR扫盲——关于Prefetch与Burst的深入讨论-Felix-电子技术应用-AET-中国科技核心期刊-最丰富的电子设计资源平台 (chinaaet.com)
【嵌牛导读】关于DDR技术预取原理
【嵌牛鼻子】DDR3的预取原理以及容量计算
【嵌牛提问】如何理解DDR读写速率翻倍以及DDR3的8位预取
【嵌牛正文】
引言:
学习DDR有一段时间了,期间看了好多的资料(部分公司的培训资料、几十篇的博文,Micron的Datasheet,JESD79规范等)。但是有一个问题,想了好久(很多资料都没有说明白),至今才算搞明白,所以写一篇文章和大家分享一下。
如题,接下来要讨论的主要是关于Prefetch和Burst相关的内容。
1、Prefetch介绍
首先,简单介绍一下Prefetch技术。所谓prefetch,就是预加载,这是DDR时代提出的技术。在SDR中,并没有这一技术,所以其每一个cell的存储容量等于DQ的宽度(芯片数据IO位宽)。【关于什么是cell(存储单元,可以去看一下,我之前的博文:http://blog.chinaaet.com/justlxy/p/5100051913)】
进入DDR时代之后,就有了prefetch技术,DDR是两位预取(2-bit Prefetch),有的公司则贴切的称之为2-n Prefetch(n代表芯片位宽)。DDR2是四位预取(4-bit Prefetch),DDR3和DDR4都是八位预取(8-bit Prefetch)。而8-bit Prefetch可以使得内核时钟是DDR时钟的四分之一,这也是Prefetch的根本意义所在。
补充说明:芯片位宽的另一种说法是配置模式(Configuration),在DDR3时代,一般有x4,x8,x16。
下面以DDR3为例,下图是个简单 一个简单Read预取示意图,Write可以看做是 个逆向过程。
当DDR3 为x8 Configuration时,一个Cell的容量为8x8bits,即8个字节。换一句话说,在指定bank、row地址和col地址之后,可以往该地址内写入(或读取)8 Bytes。
2、回到一个简单的问题上,如何计算DDR3 SDRAM的容量
以Mircon的某型号DDR3 SDRAM为例:
以图中红色部分的内容作为分析案例(8个bank,x8的Configuration):
计算方式一(错误):
64K*8*1K*8(Row Addressing * Bank Addressing * Column Addressing * x8 Configuration)= 4Gb(512 Megx8)。
大部分材料给出的都是这种错误的计算方法,误导了很多的初学者。这种计算方法咋一看好像是对的。但是,仔细推敲一下,便可以发现,按照计算方式一的逻辑,则认为每一个Cell的容量是1bit*8(x8 Configuration),即8bit。这与我们在第一部分所讨论的结果(一个Cell的容量为64bits,x8 Configuration下)不符。
当然,从某种角度来说,计算方式一也是正确的,因为分离出的Column Address的位数实际上是和prefetch对应的。比如DDR3 8-bit Prefetch对3bits的Column Address,DDR2 4-bit Prefetch对应的是2bits的Column Address。只是如果直接按照计算方式一来计算的话,对于初次接触DDR的人来说,理解起来存在一定的困难,这也是我写这一篇博文的原因。
下面给出正确的计算方式,并说明原因。
计算方式二(正确):
64K*8*(1K/8)*8*8(Row Addressing * Bank Addressing * (Column Addressing / 8) * x8 Configuration * 8-bit Prefetch)= 4Gb(512 Megx8)。
很多人都会问,为什么要把列地址寻址(Column Addressing)除以8呢?似乎计算方式二看起来更加不合理。接下来,我们先来回顾一下DDR3 SDRAM的结构框图(还是以Mircon的某型号为例):
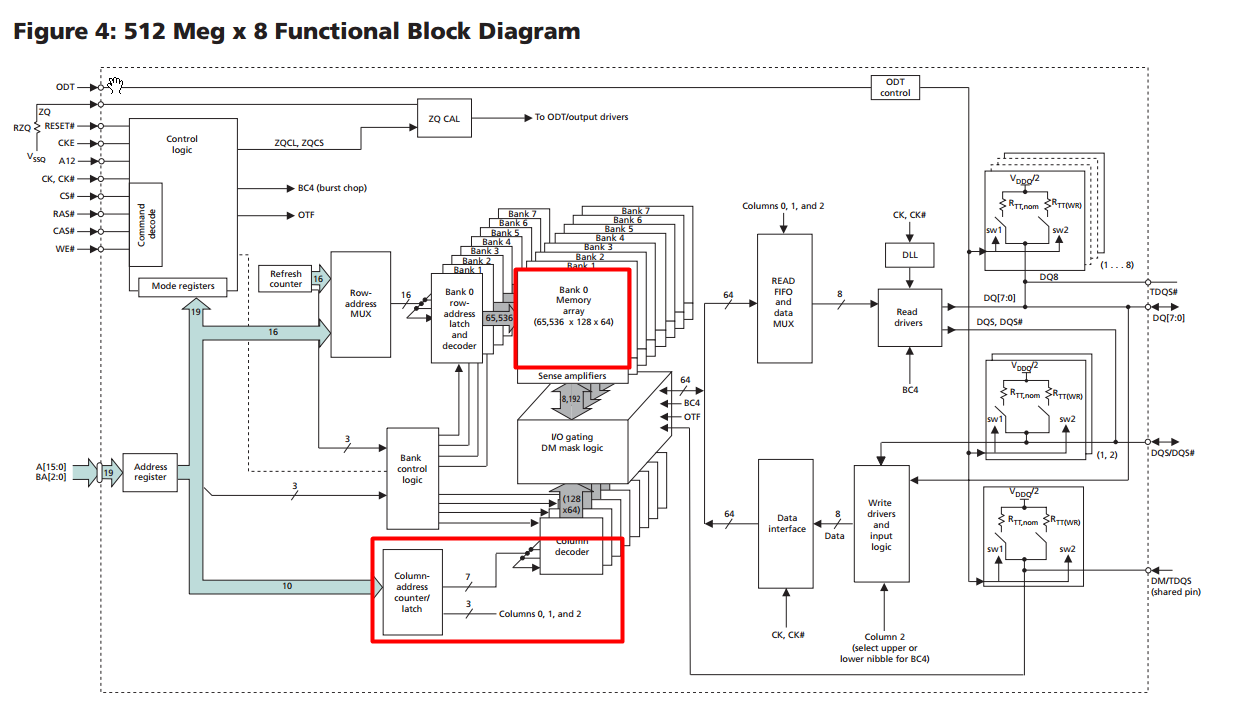
大图可能看的不太清楚,下面来几个特写:
没错!你没有看错!10bit的Column Address的寻址能力只有128!!!刚好差了8倍(这就是我们在计算方式二中将Column Addressing除以8的原因)!
那么问题又来了,为什么Column Address的寻址能力只有128呢?莫急,请继续看下图:
在上图中,可以清晰地发现,10bits的Column Address只有7bits用于列地址译码!列地址0,1,2并没有用!!!
那么,问题又来了!……
列地址0,1,2,这3bits被用于什么功能了?或者是Mircon的设计者脑残,故意浪费了这三个bits?显然不是。
在JESD79-3规范中有如下的这个表格:
可以发现,Column Address的A2,A1,A0三位被用于Burst Order功能,并且A3也被用于Burst Type功能。由于一般情况,我们采用的都是顺序读写模式(即{A2,A1,A0}={0,0,0}),所以此时的A3的取值并无直接影响。
那么,问题又来了!……
Burst又是什么鬼呢?且看第三部分。
3、DDR中的Burst Length
Burst Lengths,简称BL,指突发长度,突发是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输所涉及到存储单元(列)的数量就是突发长度(SDRAM),在DDR SDRAM中指连续传输的周期数。上一部分讲到的Burst Type和Burst Order实际上就是关于Burst Length的读写顺序的配置。
【注:不了解相关名词的可以去看一下,我之前的博文:http://blog.chinaaet.com/justlxy/p/5100051913】
在DDR3 SDRAM时代,内部配置采用了8n prefetch(预取)来实现高速读写.这也导致了DDR3的Burst Length一般都是8。当然也有Bursth ength为4的设置(BC4),是指另外4笔数据是不被传输的或者被认为无效而已。
在DDR2时代,内部配置采用的是4n prefetch,Burst length有4和8两种,对于BL=8的读写操作,会出现两次4n Prefetch的动作。
上图是JESD79-3规范中给出的DDR3 SDRAM的Command Truth Table。可以看到,读取和写入都有三种基本模式(Fixed BL8 or BC4,BC4 on the fly,BL8 on the fly)。这一部分的内容,在我之前的博文中有所提及,此处不再详细介绍。
4、参考资料
4Gb_DDR3_SDRAM.pdf
Samsung DDR3 Datasheet.pdf
JESD79-3A-DDR3规范.pdf
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)