推荐系统评价指标
精确率:
分类正确的正样本数 / 分类器判定为正样本数
召回率:
分类正确的正样本数 / 真正的正样本数
在排序问题中,Top N就是模型判定的正样本,然后计算前N个位置上的准确率Precision@N和前N个位置上的召回率Recall@N。
P-R曲线
横轴是召回率,纵轴是精确率。P-R曲线上一个点代表着,某一阈值下,模型将大于该阈值的结果判为正样本,小于该阈值的为负样本,此时返回结果对应的召回率和精确率。整条曲线是通过将阈值从高到低移动而生成的。
怎么样通过P-R曲线判断分类器性能?
曲线A完全包住曲线B,那么A好。或平衡点(P=R)的取值较大,说明分类器性能好。
F1 score
精准率和召回率的调和平均值:F1=2precisionrecall / (precision+recall)
!!!重要的——ROC曲线
横坐标假阳性率FPR=FP / N,纵坐标真阳性率TPR=TP / P。
混淆矩阵核心:TP、TN、FP、FN(记忆小trick:预测的是后面的字母)
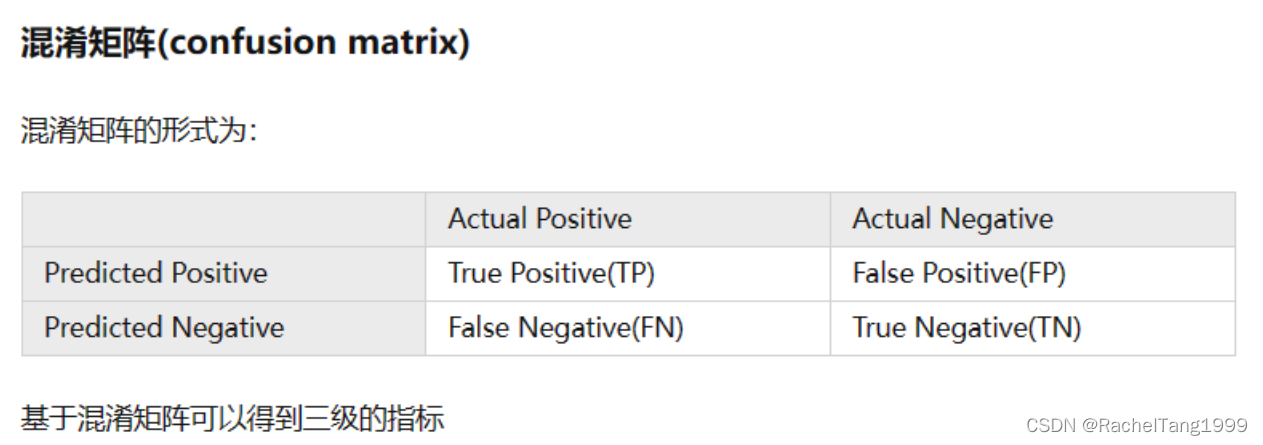
N是真实负样本数,FP是N个负样本中被分类器预测为正样本的个数;P是真实正样本数,TP是P个正样本中被分类器预测为正样本的个数。
如何绘制ROC曲线?
”截断点“由高到低,每个截断点都会对应一个FPR和TPR。在二值分类问题当中,”截断点“指的就是区分正负预测结果的阈值。依次调整截断点,直到画出全部的关键点。
另一种直观绘图方法:
横轴间隔1/N,纵轴间隔1/P;根据模型输出的预测概率对样本进行排序(从高到低);依次遍历样本,遇到一个正样本就沿纵轴绘制一个间隔的曲线,遇到一个负样本就沿横轴绘制。直到遍历完全部样本,曲线最终停留在(1,1)。
ROC曲线相比P-R曲线有什么特点?
当正负样本分布发生变化时,ROC曲线的形状能基本保持不变。这个特点让ROC曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能。当想要看到的是模型在特定数据集上的表现,P-R曲线能更直观地反映性能。
如何计算AUC?
AUC是ROC曲线下的面积大小,一般在x=y的上面,取值范围0.5~1。AUC越大,说明模型越可能把真正的正样本排在前面,分类性能越好。AUC对正负样本比例不敏感,说明:ROC曲线横轴FPR只关注负样本,与正样本无关;纵轴TPR只关注正样本,与负样本无关。横纵轴都不受正负样本比例影响,积分当然也不受其影响。
重要!!!手撕AUC
参考的是这位大佬:
https://www.jianshu.com/p/f9f8e29abbe0
从计算概率的角度理解AUC,随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
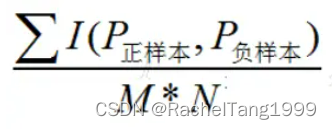
在有M个正样本,N个负样本的数据集里:
一共有MxN对样本(一对样本即,一个正样本与一个负样本),先统计这MxN对样本里,正样本的预测概率大于负样本的预测概率的个数。
举例如下
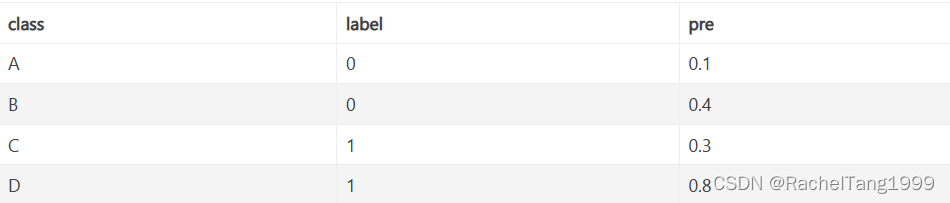
假设有4条样本。2个正样本,2个负样本,那么MxN=4。
即总共有4个样本对。分别是:
(C,A), (C,B), (D,A), (D,B)
在(C,B)样本对中,正样本C预测的概率小于负样本B预测的概率(也就是C的得分比B低),记为0
在(D,B)样本对中,正样本D预测的概率大于负样本B预测的概率(也就是D的得分比B高),记为1
所以最后的AUC结果即为:
(C,A), (C,B), (D,A), (D,B) =1+0+1+1
总样本对为MxN=4
所以结果为:(1+0+1+1)/4=0.75
如果样本对中正负样本的得分一样,I值取0.5。
import numpy as np
from sklearn.metrics import roc_auc_score
def calcAUC(labels, probs):
N = 0
P = 0
neg_prob = []
pos_prob = []
for _, i in enumerate(labels):
if i == 1:
P += 1
pos_prob.append(probs[_])
else:
N += 1
neg_prob.append(probs[_])
number = 0
for pos in pos_prob:
for neg in neg_prob:
if pos > neg:
number += 1
elif pos == neg:
number += 0.5
return number / (N * P)
y = np.array([1, 0, 0, 0, 1, 0, 1, 0])
pred = np.array([0.9, 0.8, 0.3, 0.1, 0.4, 0.9, 0.66, 0.7])
print('auc=', calcAUC(y, pred))
print('roc_auc=', roc_auc_score(y, pred))
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)