分布式离线计算框架MapReduce
MapReduce是一种编程模型。Hadoop MapReduce采用Master/slave 结构。只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序。核心思想是:分而治之。Mapper负责分,把一个复杂的业务,任务分成若干个简单的任务分发到网络上的每个节点并行执行,最后把Map阶段的结果由Reduce进行汇总,输出到HDFS中,大大缩短了数据处理的时间开销。MapReduce就是以这样一种可靠且容错的方式进行大规模集群海量数据进行数据处理,数据挖掘,机器学习等方面的操作。
1. MapReduce的设计理念
- 分布式计算
分布式计算将该应用分解成许多小的部分,分配给多台计算机节点进行处理。这样可以节约整体计算时间,大大提高计算效率。
- 移动计算,而不是移动数据
移动计算是随着移动通信、互联网、数据库、分布式计算等技术的发展而兴起的新技术。移动计算它的作用是将有用、准确、及时的信息提供给任何时间、任何地点的任何客户(这里我们说的是将计算程序应用移动到具有数据的集群计算机节点之上进行计算操作)。
2. MapReduce体系结构
MapReduce整体上依旧是主从架构,map加redu(reduce简写)。 map、split入磁盘,数据对分partition。shuffle、sort、key-value,一个redu(reduce)一 tion(partition)透。一个reduce解析一个partition。
2.1 MapReduce1.x架构
MapReduce1.x架构包含四个组成部分,分别为Client,JobTracker,TaskTracker,Task。其中:
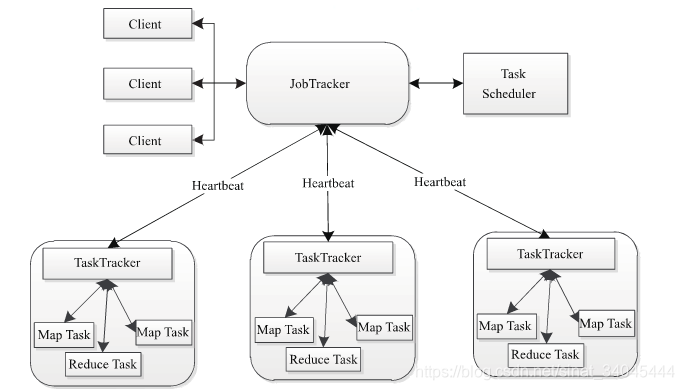
- 用户端通过Client类将应用程序以及配置信息上传到HDFS;
- JobTracker负责资源监控和作业调度;
- TaskTracker会周期性地通过HeartBeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时执行JobTracker发送过来的命令 并执行相应的操作(如启动新任务,杀死任务等);
- Task分为MapTask和Reduce Task两种,均由TaskTracker启动:
- Map Task先将对应的split迭代解析成一个key-value对,依次调用用户定义的map()函数进行处理,最终将临时结果存放到本地磁盘上。其中,临时数据被分成若干个partition,每个partition将被一个Reduce Task处理;
- Reduce Task从远程节点上读取Map Task中间结果(称为“Shuffle 阶段”), 按照 key 对 key-value 对进行排序(称为 “Sort 阶段”),依次读取< key, value list >,调用用户自定义的Reduce函数处理,并将最终结果存到HDFS上(称为“Reduce阶段”) 。
2.2 MapReduce2.x架构
MapReduce2.x架构图如下,可以看到JobTracker和TaskTracker已经不复存在了,取而代之的是ResourceManager和NodeManager。不仅架构变了,功能也变了,2.x之后新引入了YARN,在YARN之上我们可以运行不同的计算框架,不再是1.x那样只能运行MapReduce了:
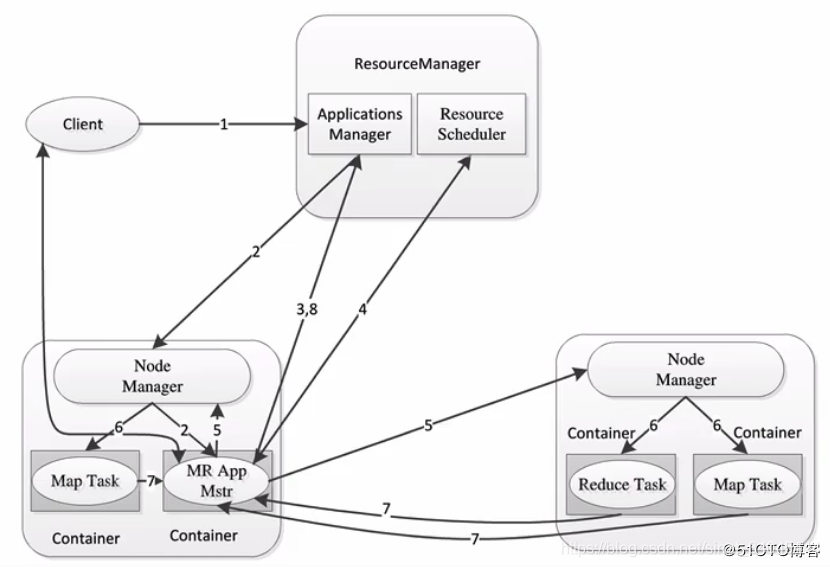
详情请参见前一小节 YARN。
3. MapReduce执行过程
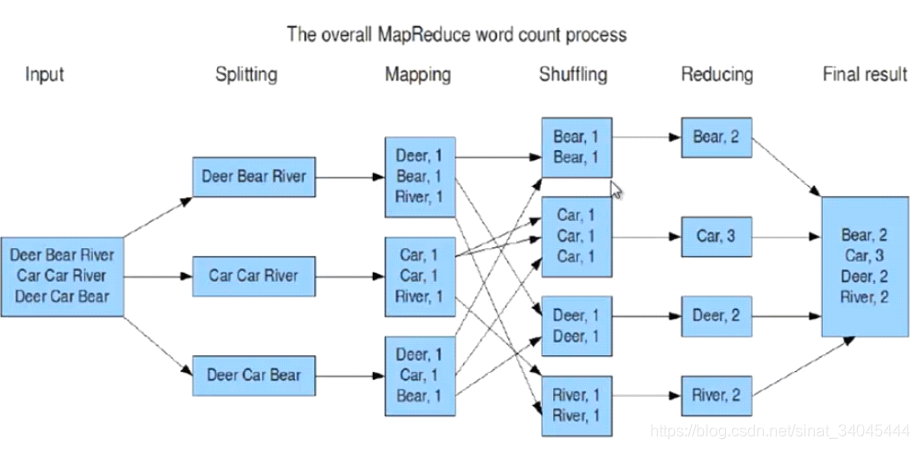
3.1 Mapper阶段
Mapper负责“分”,即把得到的复杂的任务分解为若干个“简单的任务”执行,既:数据或计算规模相对于原任务要大大缩小;就近计算,即会被分配到存放了所需数据的节点进行计算;这些小任务可以并行计算,彼此间几乎没有依赖关系。Mapper阶段的主要流程:
-
第一阶段 getSplits:把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size = Block size,每一个切片由一个MapTask 处理;
Split规则:max.split(100M)、min.split(10M)、block(64M)——max(min.split,min(max.split,block)),一般默认split实际=block大小;
-
第二阶段 TextInputFormat:对切片中的数据按照一定的规则解析成<key,value>对,默认规则是key为每一行的起始位置(即字节),value是本行的文本内容;
-
第三阶段 map():上一阶段的每个键值对都调用一次Mapper类中的map方法,会输出零个或者多个键值对;
-
第四阶段 partition:按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区,分区的数量就是 Reducer 任务运行的数量;
-
第五阶段 sort:对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序;如果有第六阶段,则进入第六阶段;如果没有,直接输出到本地的linux 文件中;
-
第六阶段 Combiner:如果client设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量,combiner简单说就是map端的reduce!
-
第七阶段 Merge:每一个map任务有一个环形Buffer,这个缓冲区的大小是100MB,每当缓冲区到达上限80%的时候,就会启动一个Spill(溢写)进程,它的作用是把内存里的map task的结果写入到磁盘,多个溢写文件会最终合并到一起。
3.2 Reduce阶段
Reduce的任务是对map阶段的结果进行“汇总”并输出。Reducer的数目由mapred-site.xml配置文件里的项目mapred.reduce.tasks决定。缺省值为1,用户可以覆盖之。Reduce阶段的主要流程:
- 第一阶段 Copy:Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的;
- 第二阶段 Merge:这里的merge与map端的merge类似,同属于shuffle阶段;Copy过来的数据会先放入内存缓冲区中,当内存中的数据量到达一定阈值,就启动内存到磁盘的merge;
- 第三阶段 Reducer的输入文件:不断地merge后,最后会生成一个“最终文件”,这个文件可能存在于磁盘上,也可能存在于内存中;
- 第四阶段 reduce():和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。
3.3 Shuffle阶段
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。这是一个在mapper和reducer中间的一个步骤,可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去处理。
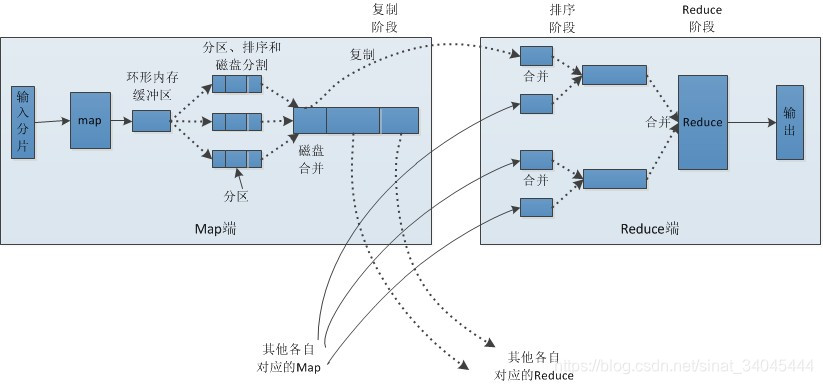
但从上图来看会依然无法理解Shuffle阶段具体实施,所以分析如下:
3.3.1 shuffle解决什么问题
- 完整地从map task端拉取数据到reduce 端;
- 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗;
- 减少磁盘IO对task执行的影响。
Shuffle阶段具体划分:
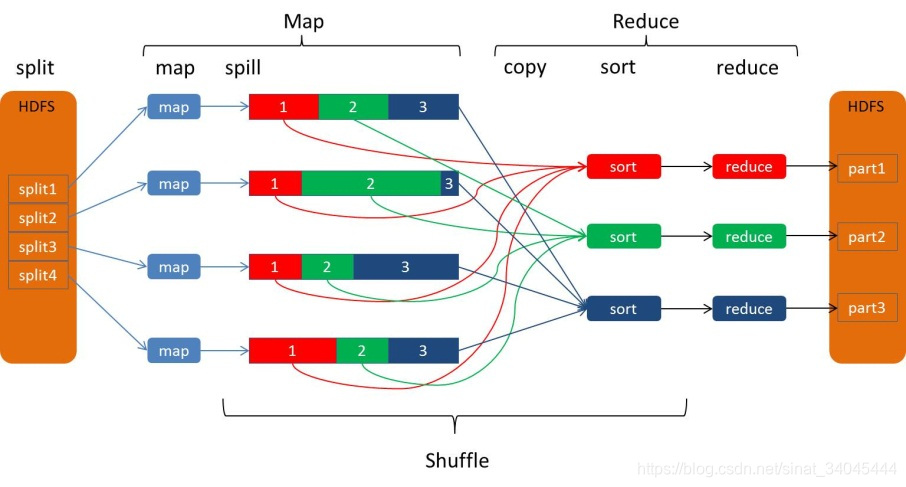
3.3.2 Map Shuffle
在Map端的shuffle过程就是对Map的结果进行分区、排序、分割,然后将属于同一个分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。分区有序的含义是Map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排序(默认),大致流程如下:
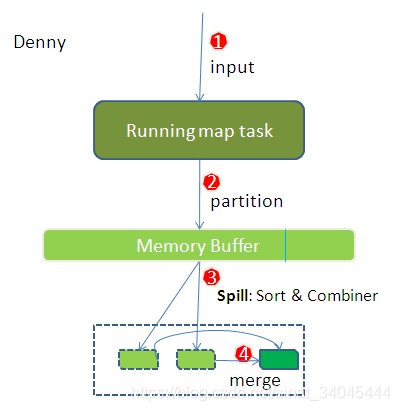
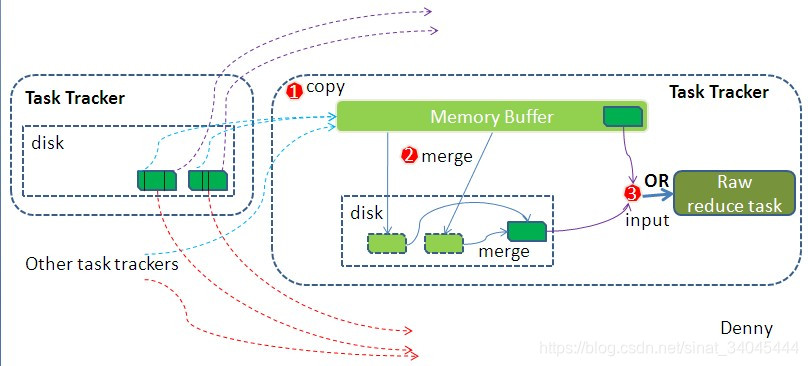
3.3.3 Reduce Shuffle
在Reduce端的shuffle过程是要对Map Shuffle的结果进行领取数据 、归并数据 、数据输入给Reduce任务;Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据,Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce处理,大致流程如下:
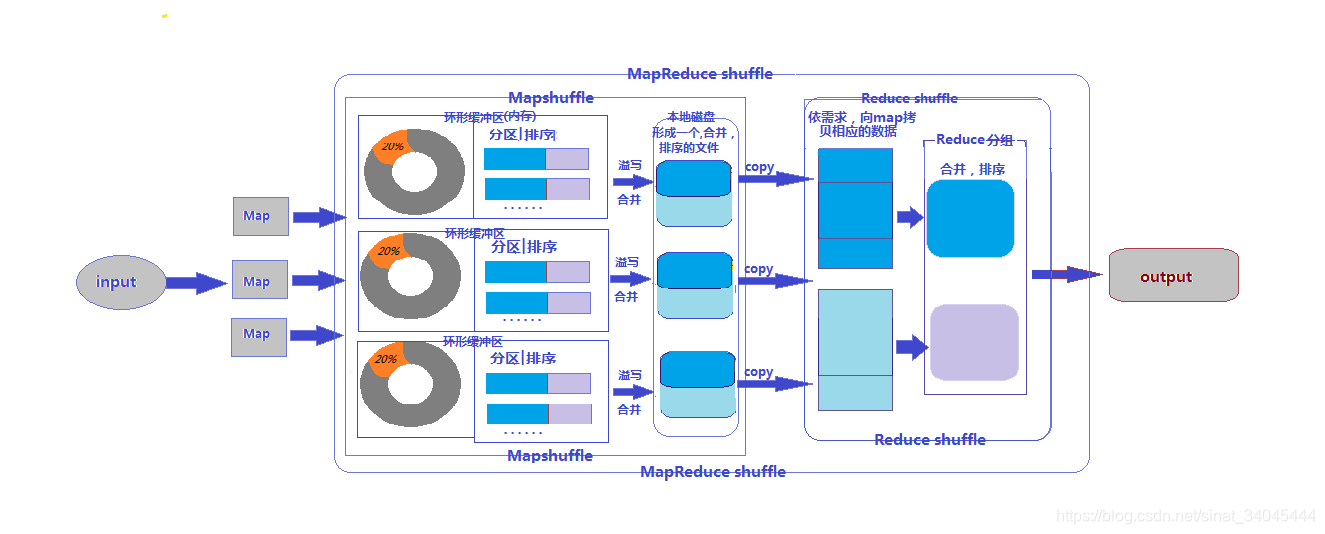
3.3.4 MapReduce详解图
4. MapReduce部署
延续之前hadoop HA高可用的配置,事先停止HA 集群(yarn、dfs、zookeeper),并加入新的配置:
1)、配置 etc/hadoop/mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2)、配置 etc/hadoop/yarn-site.xml文件:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mr_shsxt</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
3)、测试启动
- 启动三个zookeeper:./zkServer.sh start;
- 整体启动hadoop:start-all.sh;
- 分别在node02、node03节点上启动yarn:yarn-daemon.sh start resourcemanager;
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)