1. HBase 简介
- HBase-Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库;
- 在Hadoop生态圈中,它是其中一部分且利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务,主要用来存储非结构化和半结构化的松散数据(NoSQL非关系型数据库有redis、MongoDB等);
- 而我们的HBase就是这样一个非关系型数据库。
2. HBase数据模型
| Row Key | Time Stamp | CF1 | CF2 | CF3 |
| 11248112 | t6 | | CF2:q2=v2 | CF3:q3=val3 |
| t3 | | | |
| t2 | | CF1:q1=v1 | |
2.1 ROW KEY
- 决定一行数据
- 按照字典顺序排序的。
- Row key最大只能存储64k的字节数据
2.2 Column Family列族 & qualifier列
- HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
- 列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如 course:math, course:english, 新的列可以随后按需、动态加入;权限控制、存储以及调优都是在列族层面进行的;
- HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
2.3 Cell单元格
- 由行和列的坐标交叉决定; 单元格是有版本的;
- 单元格的内容是未解析的字节数组;
- 由{row key, column( = +), version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
2.5 Timestamp时间戳
- 在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面;
- 时间戳的类型是 64位整型;
- 时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
2.5 HLog (WAL log)
- HLog文件就是一个普通的Hadoop SequenceFile,Sequence File的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number;
- HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。存储hbase表的操作记录,KV数据信息。
3. HBase 体系架构
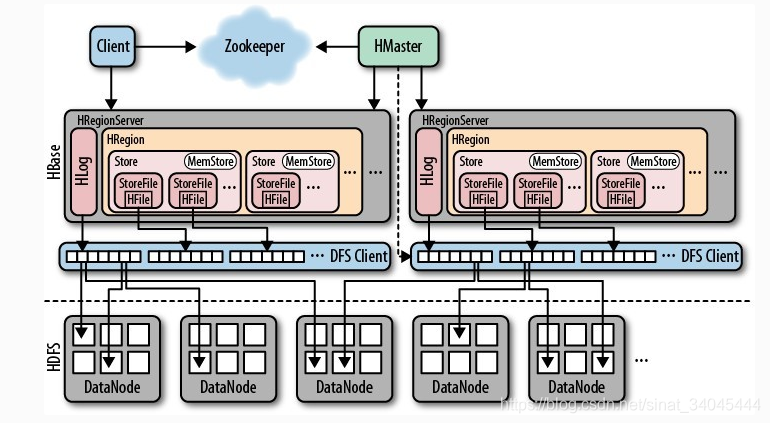
3.1 Client
包含访问HBase的接口并维护cache来加快对HBase的访问。
3.2 Zookeeper
- 保证任何时候,集群中只有一个master;
- 存贮所有Region的寻址入口;
- 实时监控Region server的上线和下线信息,并实时通知Master;
- 存储HBase的schema和table元数据。
3.3 Master
- 为Region server分配region;
- 负责Region server的负载均衡;
- 发现失效的Region server并重新分配其上的region;
- 管理用户对table的增删改操作。
3.4 RegionServer
- Region server维护region,处理对这些region的IO请求;
- Region server负责切分在运行过程中变得过大的region。
3.5 Region
- HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变);
- 当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
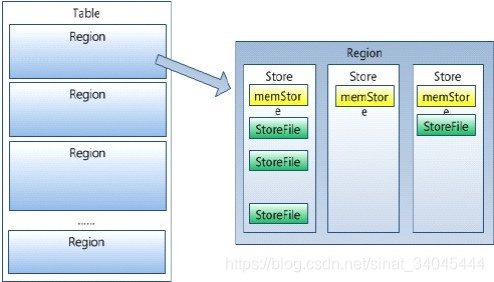
3.6 Memstore 与 storefile
- 一个region由多个store组成,一个store对应一个CF(列族);
- store包括位于内存中的memstore和位于磁盘的storefile。写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile;当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile;
- 当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡;
- 客户端检索数据,先在memstore找,找不到再找storefile;
- HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上;
- HRegion由一个或者多个Store组成,每个store保存一个columns family;
- 每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。
4. HBase 安装部署
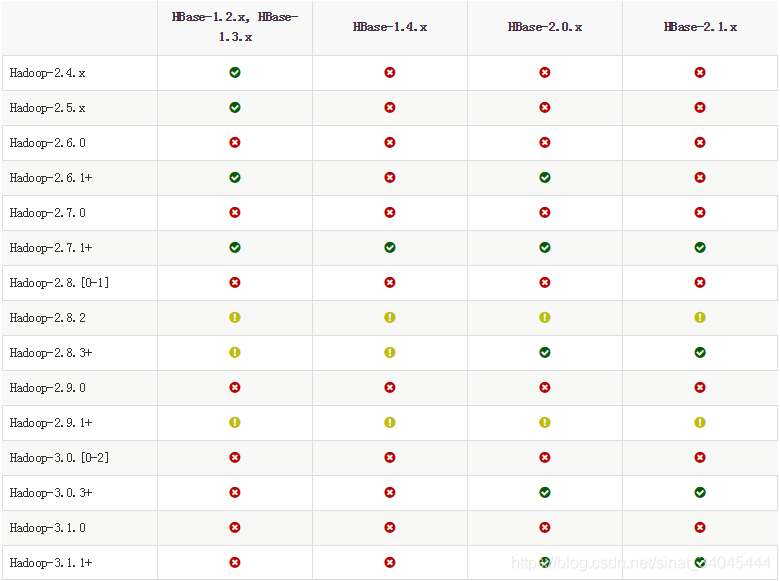
1)、HBase tar包及源码包下载:HBase下载,上传至服务器并解压;
查看Hadoop版本与HBase版本兼容性:
2)、配置 HBase 环境变量
vim ~/.bash_profile
添加:
export HBASE_HOME=/usr/hbase-1.3.3
PATH=$PATH:$HBASE_HOME/bin
重新载入环境变量:
source ~/.bash_profile
3)、修改$HBASE_HOME/conf/hbase-env.sh中配置JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64
export HBASE_MANAGES_ZK=false
注意:不使用HBase的默认zookeeper配置:HBASE_MANAGES_ZK=false。
4)、修改配置$HBASE_HOME/conf/hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://fzp/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
5)、添加配置$HBASE_HOME/conf/regionservers 的主机名
node01
node02
node03
6)、配置$HBASE_HOME/conf/backup-masters添加master备份的主机名
vim $HBASE_HOME/backup-masters
添加:
node03
7)、拷贝Hadoop的下配置文件hdfs-site.xml到当前conf下
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HBASE_HOME/conf
8)、将部署的HBase包发送到集群其它节点
scp -r hbase-1.3.3 node02:`pwd`
scp -r hbase-1.3.3 node03:`pwd`
9)、启动HBase
- 启动Zookeeper集群:
zkServer.sh start; - 启动Hadoop集群:
start-all.sh; - 启动HBase:
start-hbase.sh; jps查看进程:
[root@node01 ~]# jps
1104 QuorumPeerMain
2930 Jps
1507 JournalNode
1238 NameNode
1847 NodeManager
2761 HMaster
1642 DFSZKFailoverController
2877 HRegionServer
1327 DataNode
[root@node02 ~]# jps
1395 JournalNode
1267 NameNode
1941 Jps
1573 NodeManager
1481 DFSZKFailoverController
1898 HRegionServer
1323 DataNode
1214 QuorumPeerMain
[root@node03 ~]# jps
1269 DataNode
1673 HMaster
1738 Jps
1434 NodeManager
1611 HRegionServer
1212 QuorumPeerMain
1325 JournalNode
注:hbase1.x版本以后需要在$HBASE_HOME/hbase-site.xml配置端口:
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
5. HBase shell常用命令
[root@node01 ~]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hbase-1.3.3/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hadoop-2.6.5/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.3.3, ra75a458e0c8f3c60db57f30ec4b06a606c9027b4, Fri Dec 14 16:02:53 PST 2018
hbase(main):001:0>
- 要退出交互shell命令,在任何时候键入 exit 或使用<Ctrl + C>;
- 检查shell功能之前,使用
list 命令用于列出所有可用表;
hbase(main):001:0> list
TABLE
0 row(s) in 0.9510 seconds
=> []
hbase(main):002:0>
-
查询系统上运行的服务器的细节和系统的状态:status;
-
查询HBase系统使用的版本:verson;
-
引导如何使用HBase shell:help、table_help;
-
创建表,语法:create ‘<table name>’,’<column family>’;
下面给出的是一个表名为emp的样本模式。它有两个列族:“personal data”和“professional data”:
hbase(main):001:0> create 'emp', 'personal data', 'professional data'
0 row(s) in 12.8200 seconds
=> Hbase::Table - emp
hbase(main):002:0>
-
禁用表,语法:disable ‘<table name>’;
-
启用表,语法:enable ‘<table name>’;
-
显示表描述,语法:describe 'table name';
-
更改列族单元格的最大数目,如设置为5:
hbase(main):003:0> alter 'emp', NAME => 'personal data', VERSIONS => 5
-
表范围运算符:
设置只读:
hbase>alter 't1', READONLY(option)
删除表范围运算符:
hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'MAX_FILESIZE'
删除列族:
hbase> alter 'able name', 'delete' => 'column family'
-
验证表是否存在,语法:exists 'table_name';
-
删除表,在删除一个表之前必须将其禁用:disable 'table_name',再删除:drop 'table_name';
-
删除匹配“regex”表,如:drop_all 't.*';
-
创建数据,语法:put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’;
-
更新数据,语法:put ‘table name’,’row ’,'Column family:column name',’new value’;
-
读取数据,语法:get ’<table name>’,’row1’;
-
读取制定列,语法:get 'table name', ‘rowid’, {COLUMN => ‘column family:column name ’};
-
删除特定单元格,语法:delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’;
-
删除一行所有单元格,语法:deleteall ‘<table name>’, ‘<row>’;
-
使用 scan 命令可以得到表中的数据:scan ‘<table name>’;
-
计算标的行数:count ‘<table name>’;
-
禁止删除并重新创建一个表:truncate 'table name',若此表已存在则截断并清空该表;
-
grant命令授予特定的权限给一个特定的用户:
hbase> grant <user> <permissions> [<table> [<column family> [<column; qualifier>]]
我们可以从RWXCA组,其中给予零个或多个特权给用户
- R - 代表读取权限
- W - 代表写权限
- X - 代表执行权限
- C - 代表创建权限
- A - 代表管理权限
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)