本文为博主原创文章,未经博主允许不得转载。
本文为专栏《python三维点云从基础到深度学习》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/124017716”。
nuScenes网上介绍资料较多,但是大部分仅仅是对官网的翻译,缺乏各个文件的内在联系介绍。例如,nuScenes激光雷达的数据格式,点云包含哪几种属性。再比如,sample文件夹和sweeps文件夹下的文件关系,以及是如何在相关json文件中体现的。本文将详细介绍nuScenes数据集的各个部分。
1 nuScenes基本信息
nuScenes 数据集是由Motional(前身为 nuTonomy)团队开发的用于自动驾驶的共有大型数据集。数据集来源于波士顿和新加坡采集的1000个驾驶场景,每个场景选取了20秒长的视频,共计大约15 小时的驾驶数据。场景选取时充分考虑多样化的驾驶操作、交通情况和意外情况等,例如不同地点、天气条件、车辆类型、植被、道路标和驾驶规则等。相比于Kitti数据集,nuScenes复杂性更高,场景更加丰富。
nuScenes 数据集于2019年3月正式发布。 完整的数据集包括大约 140 万个图像、39 万个激光雷达点云、140 万个雷达扫描和 4 万个关键帧中的 140 万个对象边界框。nuScenes 是第一个提供来自自动驾驶汽车整个传感器套件的大规模数据集,其传感器包括6 个摄像头、1 个激光雷达、5 个毫米波雷达、GPS和IMU,如下图所示。此外,2020 年 7 月发布的 nuScenes-lidarseg数据集,增加了激光雷达点云的语义分割标注,共14亿个点,涵盖了23 个前景类和 9 个背景类。

图1 传感器分布
2 nuScenes数据集下载
nuScenes官网地址为https://www.nuscenes.org/nuscenes#overview,注册后可免费下载。完整nuScenes数据集包括40,000 个点云和 1000 个场景(850 个用于训练和验证的场景,以及 150 个用于测试的场景),相应数据压缩文件总体大小共347GB左右。如果是进行简单的算法实验,建议下载Mini版数据集。Mini版数据集仅包含10个场景,下载压缩文件为3.88GB。后续nuScenes数据集具体介绍将参考Mini版进行。
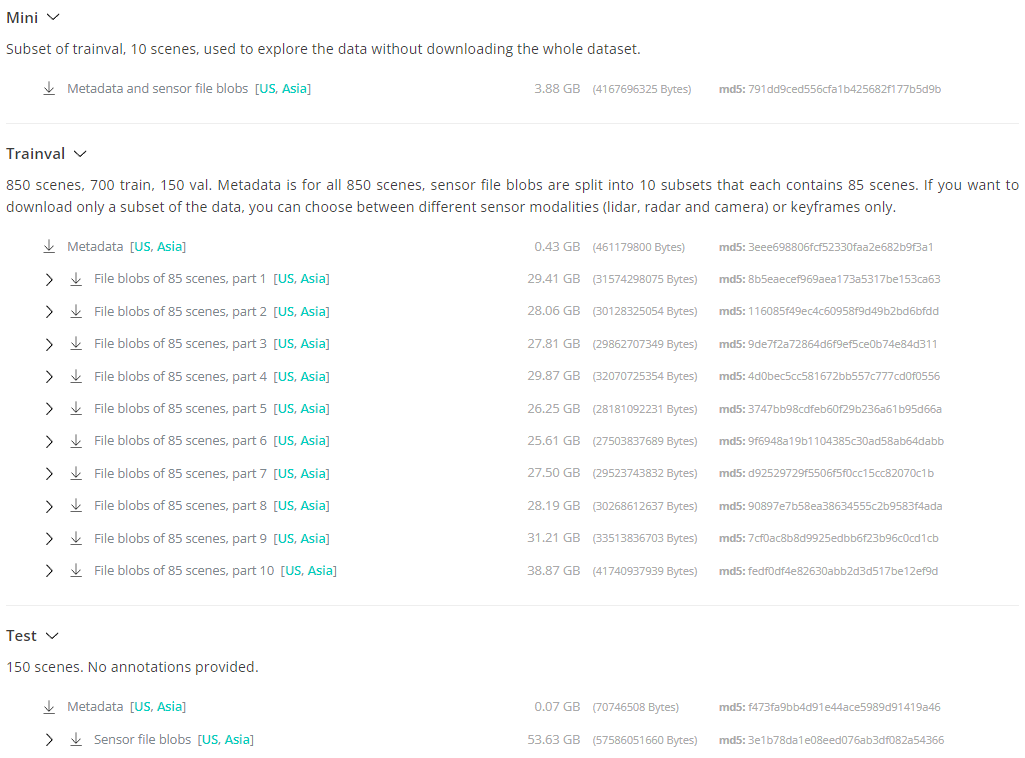
图2 nuScenes数据集下载
3 nuScenes文件说明
Mini nuScenes下载后得到名称为“v1.0-mini.tgz”的压缩包,主要包含maps、samples、sweeps和v1.0-mini等4个文件夹。下面分别进行简要介绍。
- maps:数据采集的地图路线,是一个二值图,道路所在路线对应的像素值为255,其它像素值为0。
- samples:数据样本,分别包括6 个摄像头、1 个激光雷达、5 个毫米波雷达所采集的数据,每个传感器采集404个样本。数据来源于10个场景,且每个场景共采集了约连续20秒数据。samples中的数据是在这些连续数据样本中,以2Hz频率进行采样,即每秒2张图片。摄像头采集数据集保存为jpg图像格式,激光雷达和毫米波雷达采集数据保存为pcd点云格式。各个传感器的数据文件总数为12x404=4848。其中,激光雷达的点云属性包括空间坐标x、y、z、反射强度和雷达垂直方向扫描序号(32线雷达的取值范围为0~31)。
- sweeps:samples中的数据是经过2Hz采样得到的数据。sweeps中存储的则是连续扫描得到约20秒传感器数据,存储结构和格式完全与samples文件夹一致。由于数据是连续扫描得到的,其可以用来合成视频,模拟实际连续检测的效果。各个传感器的数据文件总数为26358。
- V1.0-mini:该文件夹中主要包含了数据详细说明,例如传感器标定参数、目标类别、标注信息等,共包含13个json文件下面将分别进行详细介绍。
3.1 attribute.json
文件记录了汽车、自行车(摩托车)和行人不同的状态属性,参数分别是token、name、description,共8组数据。token表示状态属性的唯一标识符。name表示状态属性类型名称,共8种情形。汽车状态属性包括行驶、停止和停车3种情况。停止是指暂时停车,驾驶员仍然在车上且随时有继续行驶的迹象。停车是指车辆长时间禁止,没有迹象继续行驶。自行车(摩托车)主要包括有无驾驶员在车上两种状态。行人则涉及坐着(躺着)、站着和移动三种状态。description表示各种属性状态的解释和描述。
{
"t0ken": "cb5118da1ab342aa947717dc53544259",
"name": "vehicle.moving",
"description": "Vehicle is moving."
}
3.2 caibrated_sensor.json
文件记录了各个传感器的校准数据,参数分别是token、sensor_token、translation、rotation、camera_intrinsic,共120组数据。token表示不同场景下传感器的唯一标识符,与场景或车辆相关。sensor_token表示传感器类别唯一标识符,与sensor.json的token一致。由于场景数量为10且传感器类别数量为12,因此校准文件中共计录120组数据。translation、rotation和camera_intrinsic分别表示平移坐标(x、y、z)、旋转坐标(四元数,w、x、y、z)和相机内外参数,具体含义和使用方式可参考本专栏之前博文的Kitti校准数据部分。
{
"t0ken": "f4d2a6c281f34a7eb8bb033d82321f79",
"sensor_token": "47fcd48f71d75e0da5c8c1704a9bfe0a",
"translation": [
3.412,
0.0,
0.5
],
"rotation": [
0.9999984769132877,
0.0,
0.0,
0.0017453283658983088
],
"camera_intrinsic": []
}
3.3 category.json
文件记录了目标的所有类别,参数分别是token、name、description,共计23种类别。token表示类别的唯一标识符,例如行人(成年人)的唯一标识为“1fa93b757fc74fb197cdd60001ad8abf”。name表示类别名称,如human.pedestrian.wheelchair。description表示类别的解释说明,例如坐轮椅的人的说明为“Wheelchairs. If a person is in the wheelchair, include in the annotation.”。
{
"t0ken": "1fa93b757fc74fb197cdd60001ad8abf",
"name": "human.pedestrian.adult",
"description": "Adult subcategory."
}
3.4 ego_pose.json
文件记录了某个特定时间下车辆的姿态,参数分别是token、translation、rotation、timestamp,共31206组数据,正好是samples和sweeps文件夹下数据之和。token表示唯一标识符。translation和rotation分别表示三维平移坐标和旋转四元数。timestamp表示Unix时间戳。
{
"t0ken": "5ace90b379af485b9dcb1584b01e7212",
"timestamp": 1532402927814384,
"rotation": [
0.5731787718287827,
-0.0015811634307974854,
0.013859363182046986,
-0.8193116095230444
],
"translation": [
410.77878632230204,
1179.4673290964536,
0.0
]
}
3.5 instance.json
文件记录了存在的实例及其出现的具体时间段,参数分别是token、category_token、nbr_annotations、first_annotation_token、last_annotation_token,共911组数据,即911个实例。token表示唯一标识符。nbr_annotations表示标注数量。first_annotation_token和last_annotation_token分别表示实例首次记录和最后记录的token,根据这个token可以从sample.json文件中确定实例出现的完整时间段。
{
"t0ken": "6dd2cbf4c24b4caeb625035869bca7b5",
"category_token": "1fa93b757fc74fb197cdd60001ad8abf",
"nbr_annotations": 39,
"first_annotation_token": "ef63a697930c4b20a6b9791f423351da",
"last_annotation_token": "8bb63134d48840aaa2993f490855ff0d"
}
3.6 log.json
文件记录了车辆采集数据时的日志,参数分别是token、logfile、vehicle、date_captured、location,共8组数据。token表示唯一标识符。logfile表示数据采集时的日志文件名称。vehicle表示采集车辆名称,包含n015和n008两种类型。date_captured表示数据采集日期。location表示数据采集路线地点,共4个地点路线,分别是singapore-onenorth、boston-seaport、singapore-queenstown、singapore-hollandvillage。
{
"t0ken": "7e25a2c8ea1f41c5b0da1e69ecfa71a2",
"logfile": "n015-2018-07-24-11-22-45+0800",
"vehicle": "n015",
"date_captured": "2018-07-24",
"location": "singapore-onenorth"
}
3.7 map.json
文件记录了车辆采集数据时的二进制语义地图,是对maps文件夹的补充说明,参数分别是category、token、filename、log_tokens,共4组数据,分别对应上述4个地点。category表示图片类型,主要说明图片为语义地图。token表示唯一标识符。filename与上述maps文件夹下的地图名称对应。log_tokens表示对应地图上进行数据采集时的日志记录列表,log.json中的token便在这个列表当中。
{
"category": "semantic_prior",
"t0ken": "37819e65e09e5547b8a3ceaefba56bb2",
"filename": "maps/37819e65e09e5547b8a3ceaefba56bb2.png",
"log_tokens": [
"853a9f9fe7e84bb8b24bff8ebf23f287",
"e55205b1f2894b49957905d7ddfdb96d",
]
}
3.8 sample.json
文件记录了从10个20s场景数据中以2Hz频率(间隔0.5s)采样后的数据,参数分别是token、timestamp、prev、next、scene_token,共404组数据,与samples文件夹下各个传感器所采集的数量一致。token表示唯一标识符。timestamp表示Unix时间戳。prev表示上一次采集的token,第一次采集时由于没有上一次数据而取为空值。next表示下一次采集的token,最后一次采集时由于没有下一次数据而取为空值。scene_token表示场景的唯一标识符,与scene.json中的token一致。
{
"t0ken": "ca9a282c9e77460f8360f564131a8af5",
"timestamp": 1532402927647951,
"prev": "",
"next": "39586f9d59004284a7114a68825e8eec",
"scene_token": "cc8c0bf57f984915a77078b10eb33198"
}
3.9 sample_annotation.json
文件记录了404个样本中的标注数据,参数分别是token、sample_token、instance_token、visibility_token、attribute_tokens、translation、size、rotation、prev、next、num_lidar_pts、num_radar_pts,共18538组数据。每一组标注数据表示一个目标。如果一个样本包含多个目标,那么每个目标分别用一组标注数据表示。token表示标注数据的唯一标识符。sample_token表示采样样本的唯一标识符,与sample.json的token一致。instance_token表示实例的标识符,与instance.json的token一致。visibility_token表示目标的可见程度标识符,与visibility.json的token一致。attribute_tokens表示目标的状态属性标识符列表,与attribute.json的token一致,注意一个目标可能有多种属性,所以用列表进行表示。translation表示目标中心的三维空间坐标。size表示目标的三维尺寸。rotation表示目标的旋转角度,用四元数表示。prev表示上一次采集的token,第一次采集时由于没有上一次数据而取为空值。next表示下一次采集的token,最后一次采集时由于没有下一次数据而取为空值。num_lidar_pts表示目标范围内激光雷达的点数量。num_radar_pts表示目标范围内毫米波雷达的点数量。
{
"t0ken": "70aecbe9b64f4722ab3c230391a3beb8",
"sample_token": "cd21dbfc3bd749c7b10a5c42562e0c42",
"instance_token": "6dd2cbf4c24b4caeb625035869bca7b5",
"visibility_token": "4",
"attribute_tokens": [
"4d8821270b4a47e3a8a300cbec48188e"
],
"translation": [
373.214,
1130.48,
1.25
],
"size": [
0.621,
0.669,
1.642
],
"rotation": [
0.9831098797903927,
0.0,
0.0,
-0.18301629506281616
],
"prev": "a1721876c0944cdd92ebc3c75d55d693",
"next": "1e8e35d365a441a18dd5503a0ee1c208",
"num_lidar_pts": 5,
"num_radar_pts": 0
}
3.10 sample_data.json
文件记录了全部传感器数据,参数分别是token、sample_token、ego_pose_token、calibrated_sensor_token、timestamp、fileformat、is_key_frame、height、width、filename、prev、next,包含了samples和sweeps文件夹下所有数据,共31206组数据。token表示唯一标识符。sample_token表示样本唯一标识符,关键字的标识符与sample.json中的token一致。ego_pose_token表示车辆姿态标识符,与ego_pose.json的token一致。calibrated_sensor_token表示传感器数据对应的校准参数,与2)calibrated_sensor.json的token一致。timestamp表示Unix时间戳。fileformat表示文件格式,点云文件为pcd,图像文件为jpg。is_key_frame表示关键帧,经2Hz采样得到的sample样本为关键帧数据。height和width表示图像的宽和高,对于点云文件来说取值为空。filename表示数据存储路径,即samples和sweeps文件夹下的存储路径。prev表示上一次采集的token,第一次采集时由于没有上一次数据而取为空值。next表示下一次采集的token,最后一次采集时由于没有下一次数据而取为空值。
{
"t0ken": "5ace90b379af485b9dcb1584b01e7212",
"sample_token": "39586f9d59004284a7114a68825e8eec",
"ego_pose_token": "5ace90b379af485b9dcb1584b01e7212",
"calibrated_sensor_token": "f4d2a6c281f34a7eb8bb033d82321f79",
"timestamp": 1532402927814384,
"fileformat": "pcd",
"is_key_frame": false,
"height": 0,
"width": 0,
"filename": "sweeps/RADAR_FRONT/n015-2018-07-24-11-22-45+0800__RADAR_FRONT__1532402927814384.pcd",
"prev": "f0b8593e08594a3eb1152c138b312813",
"next": "978db2bcdf584b799c13594a348576d2"
}
3.11 scene.json
文件记录了数据采集的10个场景,参数分别是token、log_token、nbr_samples、first_sample_token、last_sample_token、name、description,共10组数据。token表示唯一标识符。log_token表示数据采集时的日志标识符,与log.json中的token一致。nbr_samples表示各个场景采集的样本数量,总数为404。first_sample_token和last_sample_token分别表示实例首次采样和最后采样的token,根据这个token可以从sample.json文件中确定采样的完整时间段。name表示场景名称,采用“scene-数字”的格式,如scene-0061。description表示场景描述,即数据采集时的交通环境,例如白天、黑夜、路口、行人有无等。
{
"t0ken": "cc8c0bf57f984915a77078b10eb33198",
"log_token": "7e25a2c8ea1f41c5b0da1e69ecfa71a2",
"nbr_samples": 39,
"first_sample_token": "ca9a282c9e77460f8360f564131a8af5",
"last_sample_token": "ed5fc18c31904f96a8f0dbb99ff069c0",
"name": "scene-0061",
"description": "Parked truck, construction, intersection, turn left, following a van"
}
3.12 sensor.json
文件记录了传感器的基本描述,参数分别是token、channel、modality,共12组数据,即12个传感器(即6 个摄像头、1 个激光雷达、5 个毫米波雷达)基本信息。token表示各个传感器的唯一标识符。channel表示传感器位置,主要区分不同位置的同一类型传感器。modality表示传感器类型,例如相机、激光雷达、毫米波雷达。
{
"t0ken": "725903f5b62f56118f4094b46a4470d8",
"channel": "CAM_FRONT",
"modality": "camera"
}
3.13 visibility.json
文件记录了目标的可见程度划分规则,参数分别是token、level、description,共4组数据。目标的可见程度按照0~40%、40%~60%、60%~80%、80%~100%的比例划分为4个等级。token表示唯一标识符,取值为1~4。level表示目标可见程度等级,包括v0-40、v40-60、v60-80、v80-100。description表示等级划分规则的具体说明。
{
"description": "visibility of whole object is between 0 and 40%",
"t0ken": "1",
"level": "v0-40"
}
4 nuScenes工具包
Nuscenes数据集提供数据处理工具包(nuscenes-devkit),包括数据读写、处理和可视化,采用pip直接安装即可,即“pip install nuscenes-devkit”。NuScenes数据读取代码如下所示。
from nuscenes.nuscenes import NuScenes
nus = NuScenes(version='v1.0-mini', dataroot=r'D:\v1.0-mini', verbose=True)
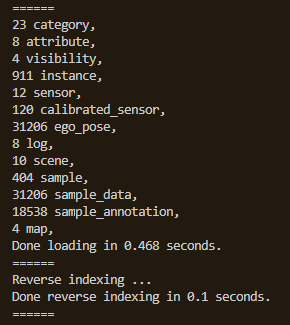
读取后nus数据集包含了上述13个json文件的全部内容,并且会打印出各个文件中存储的记录总数,如下图所示。nus.xxx分别对应json文件中的内容,这里xxx表示json文件名(不含.json后缀),如nus.sample_data。
本文为博主原创文章,未经博主允许不得转载。
本文为专栏《python三维点云从基础到深度学习》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/124017716”。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)