论文
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
摘要
MVSNet最大的问题是3D UNet,太耗费内存了。RMVSNet另辟蹊径,使用了GRU来进行代价聚合,取得了不错的效果。
方法
RMVSNet的网络结构如下图所示,其与MVSNet的结果主要不同的地方在于cost volumn的代价聚合部分。

1. 代价聚合
代价聚合一直是双目立体匹配和多视立体匹配中的老大难,并不是效果不好,而是太耗费内存。在本篇文章中,则是使用GRU Convolution来聚合代价,其思路非常简单,即在每个深度下都用一个GRU预测对应的cost,并由近到远计算,多个深度之间利用GRU来连接。至于GRU Convolution怎么操作,请看博主之前的文章。
2. 深度概率估计
与MVSNet不同,RMVSNet获取所有深度下的cost volumn后,利用softmax得到在每个深度下的概率;然后再利用交叉熵去算正确的概率与预测概率的差异,计算公式如下:
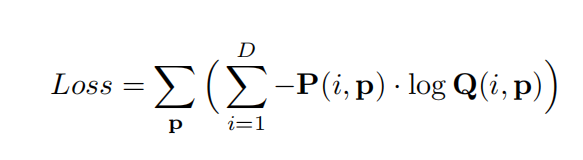
如果还记得之前说过的AcfNet,个人感觉这个loss是有点hard的;因为一方面正确的概率,只有在正确的深度值上的概率是1,其余是0,由于正确的结果只有一个,所以样本其实是不均匀的;另一就是这就导致了深度值只能是一些固定值,会导致结果出现阶梯结果,如下图所示。

3. 深度优化
RMVSNet没有直接用优化网络,反而用了一个传统算法去做梯度下降,具体方法就是传统思路,即在当前视差下计算ZNCC代价。
结果
RMVSNet最大的贡献在于想办法解决了cost volumn的计算量太大的问题,当前结果也不错的。文章看了这么久,终于可以告一段落,准备跑跑代码,做做实验了。

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)