原文转载于: http://www.cnblogs.com/bluepoint2009/archive/2012/09/18/precision-recall-f_measures.html
在信息检索和自然语言处理中经常会使用这些参数,下面简单介绍如下:
准确率与召回率(Precision & Recall)
我们先看下面这张图来加深对概念的理解,然后再具体分析。其中,用P代表Precision,R代表Recall
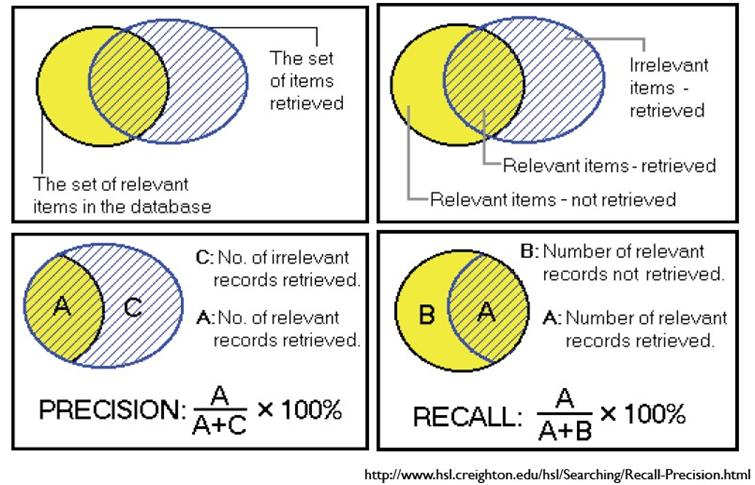
一般来说,Precision 就是检索出来的条目中(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张表介绍了True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
| | Relevant | NonRelevant |
| Retrieved | true positives (tp) | false positives(fp) |
| Not Retrieved | false negatives(fn) | true negatives (tn) |
那么,
")
")
我们当然希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。
因此在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
note by watkins:
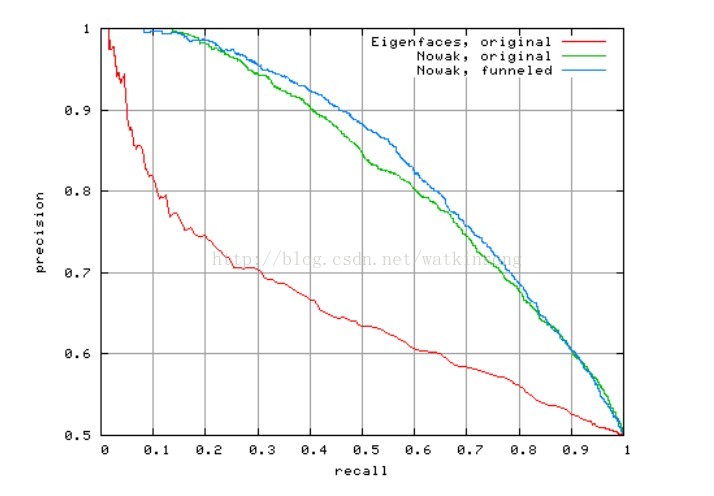
下面我截取了一个P-R曲线做个展示,转载原文中没有。
F1-Measure
前面已经讲了,P和R指标有的时候是矛盾的,那么有没有办法综合考虑他们呢?我想方法肯定是有很多的,最常见的方法应该就是F-Measure了,有些地方也叫做F-Score,其实都是一样的。
F-Measure是Precision和Recall加权调和平均:
<span
P*R} {a^2(P+R)} \hfill (3)")
当参数a=1时,就是最常见的F1了:
<span
")
很容易理解,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。
我的进一步补充:
在判断检索结果好坏时,查全率(Recall ratio)与查准率(Precision ratio)是两个最常用的指标。它们表示系统的“过滤能力”,即让相关文献“通过”,“阻止”无关文献。
查全率与查准率的定义如下:R(查全率)=(检出的相关文献数量/检索系统中相关文献总量)x100%,,P(查准率)=(检出的相关文献数量/检出的文献总量)x100% ——《文献检索与利用》—花芳
例如:在一次检索中,共检出文献100篇,经过专家判定,其中与提问相关的文献为60篇,其余的40篇为误检文献,那么按照上述公式,本次检索的查准率P就等于(60/100)×100%即60%。假如检索系统中还有90篇相关文献,由于各种原因而未被检出(漏检),那么按照上述公式,本次检索的查全率就等于(60/60+90)×100%即40%。
可见,利用上述公式,对每一次信息检索,都可计算出其查准率和查全率,对检索效率作出定量化的评价。
但是,如果进一步分析,就会发现查准率的计算没有问题,而查全率的计算存在明显的问题。那就是怎样知道漏检文献的数量。
对于小型的试验系统,在进行检索效率评价时,只要把系统中所有的文献都浏览一遍,就能准确地获得漏检文献的数量。然而,在实际运行的检索系统中,由于系统文献总量通常数以百万计,在评价检索效率时,根本不可能把浏览系统中所有的文献,因此,也就无法知道漏检文献数量。
所以,在实际的检索评价中,对于漏检文献数量,一般采用近似的估计值。获得漏检文献数量估计值的方法有两种:其一,利用其他的同类检索系统,进行相同的检索,然后通过对命中结果的分析和比较,推断哪些文献被漏检;其二,利用原有的检索系统,放大检索范围进行查找,然后对命中结果进行分析,看是否有原先未被检出的相关文献,从而得到漏检文献的近似值。
.查准率与查全率之间的关系
利用查准率和查全率指标,可以对每一次检索进行检索效率的评价,为检索的改进调整提供依据。利用这两个量化指标,也可以对信息检索系统的性能水平进行评价。
要评价信息检索系统的性能水平,就必须在一个检索系统中进行多次检索。每进行一次检索,都计算其查准率和查全率,并以此作为坐标值,在平面坐标图上标示出来。通过大量的检索,就可以得到检索系统的性能曲线。
———《文献检索与利用》陈老师
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)