pytorch的一些细节操作
本文以普通的CNN为例
1. 实验用的模型
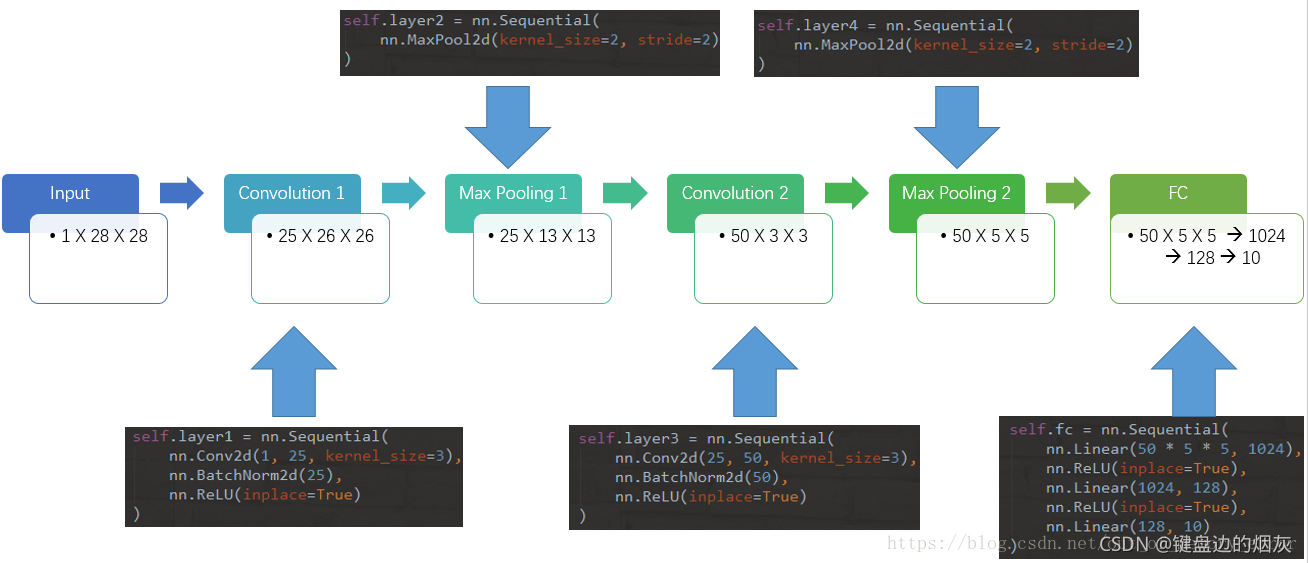
参考博客。
2. 模型代码
原始代码分成两个部分:
第一个是写CNN模型框架的py文件,cnn.py
第二个是主文件,用于下载数据和模型超参数等。work.py
cnn.py文件如下:
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 25, kernel_size=3),
nn.BatchNorm2d(25),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(50 * 5 * 5, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
work文件如下:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import cnn
batch_size = 64
learning_rate = 0.02
num_epoches = 20
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])])
train_dataset = datasets.MNIST(
root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
model = cnn.CNN()
if torch.cuda.is_available():
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
epoch = 0
for data in train_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
这是初始代码,可以直接运行。
3. 保存模型和加载模型
保存文件有两种方式:
第一种是直接保存模型的所有文件。
第二种是保存模型的参数,这种方法是官方推荐的,因为不占内存。(推荐)
3.1 保存和加载整个模型
声明,我们的例子里面用到了一个词,就是model这个单词,其实这个名字是根据我们自己定义的模型的名字来的。比如我们上面work这个文件中有
model = cnn.CNN()
这个model就是我们的模型的名字,我们可以随便定义这个名字
保存模型
torch.save(model, PATH)
例如在我们的这个例子里面:
torch.save(model,'CNN_all.pth')
加载模型
model = torch.load(PATH)
model.eval()
例子
model = torch.load('CNN_all.pth')
声明:后面的这个CNN_all.pth也是可以随意命名的
3.2 保存和加载模型的参数- state_dict
保存模型
torch.save(model.state_dict(),'CNN_Origi.pth')
加载模型
model.load_state_dict(torch.load('CNN_Origi.pth'))
4. 增加部分层和删掉部分层
我们在加载模型的时候,一定要先加载模型结构,在加载参数。
在这里我们以官方推荐的方法为例,因为这样更容易调整模型的结构。
首先声明一下,我们在对模型进行微调的时候,很多同学想删除最后面的部分层,其实这并不是删除,只是我们需要重新写一个层,然后把后面的这个层替换掉。
举个例子,我们现在需要复现某个文章中的实验,

比如这个实验,GAP表示全局平局池化,shuffle表示把全局平均池化的每个1*1的feature map的顺序打乱。
我为了验证他们这个思想的正确性做了两组实验,第一种是直接把右边的PermuteNet直接写出来,然后训练。
第二种思想是先在上面的普通CNN上做预训练,然后替换掉最后的全连接层fc,然后在换成GAP和shuffle。
首先把我们的代码弄上来
这个是直接训练的代码,也就是右边那部分。其中的Shufflechnalles是我自己写的层,本来在pytorch中有nn.Shufflechnalle()这个函数 ,但是这个函数式刚加进来的,所以这个版本的pytorch有bug,没法对nn.Shufflechnalle()层求梯度。
cnn1.py
import torch
from torch import nn
class Shufflechnalles(nn.Module):
'''打乱层的特征映射'''
def __init__(self, **kwargs):
super(Shufflechnalles, self).__init__(**kwargs)
def forward(self, x, groups=2):
bs, chnls, h, w = x.data.size()
chnls_per_group = int(chnls / groups)
x = x.view(bs, groups, chnls_per_group, h, w)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(bs, -1, h, w)
return x
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 25, kernel_size=3),
nn.BatchNorm2d(25),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
Shufflechnalles(),
nn.AdaptiveAvgPool2d((1,1))
)
self.layer5 = nn.Sequential(
nn.Linear(50 * 1 * 1,1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.layer5(x)
return x
大家直接在下面的work1.py里面做训练就可以了
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import cnn1
import torchvision
batch_size = 10
learning_rate = 0.01
num_epoches = 70
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])])
train_dataset = datasets.MNIST(
root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
model = cnn1.CNN()
if torch.cuda.is_available():
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
epoch = 0
for data in train_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
torch.save(model.state_dict(),'CNN_Origi.pth')
torch.save(model,'CNN_all.pth')
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
4.1 修改部分层
现在我们想在前面提到的cnn.py训练好的模型上做改动,也就是冻结layer4之前的层,然后增加GAP和shuffle两个部分。
同时删除最后的fc层。
我们首先上代码
from collections import OrderedDict
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import CNN_shu
import torchvision
class Shufflechnalles(nn.Module):
'''打乱层的特征映射'''
def __init__(self, **kwargs):
super(Shufflechnalles, self).__init__(**kwargs)
def forward(self, x, groups=2):
bs, chnls, h, w = x.data.size()
chnls_per_group = int(chnls / groups)
x = x.view(bs, groups, chnls_per_group, h, w)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(bs, -1, h, w)
return x
batch_size = 10
learning_rate = 0.01
num_epoches = 70
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])])
train_dataset = datasets.MNIST(
root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
CNN_shuffmodel = cnn.CNN()
CNN_shuffmodel.load_state_dict(torch.load('CNN_Origi.pth'))
CNN_shuffmodel.layer4.add_module('add_shuffle',Shufflechnalles())
CNN_shuffmodel.layer4.add_module('add_AGP',nn.AdaptiveAvgPool2d((1,1)))
classifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(50 * 1 * 1, 10))]))
CNN_shuffmodel.fc = classifier
print(CNN_shuffmodel)
if torch.cuda.is_available():
CNN_shuffmodel = CNN_shuffmodel.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(CNN_shuffmodel.parameters(), lr=learning_rate)
epoch = 0
for data in train_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = CNN_shuffmodel(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
CNN_shuffmodel.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = CNN_shuffmodel(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
我们首先看一下原始CNN的结构

CNN_shuffmodel.load_state_dict(torch.load('CNN_Origi.pth'))
CNN_shuffmodel.layer4.add_module('add_shuffle',Shufflechnalles())
CNN_shuffmodel.layer4.add_module('add_AGP',nn.AdaptiveAvgPool2d((1,1)))
classifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(50 * 1 * 1, 10))]))
CNN_shuffmodel.fc = classifier
print(CNN_shuffmodel)
首先,第一个就是关于下载模型的,我们可以用load的方式下载模型,也可以自己把这个模型的结构文件下载下来直接通过import的方式调用。
然后是加载模型参数
加载模型参数这一块我需要提一下,我以前以为加载模型参数是在修改好模型结构之后再加载的。然后我发现一直报错。后来我把加载模型参数调整到修改模型参数之前,然后就没有报错,正常训练了。
原始的CNN结构

再看看修改好的模型机构

5. 关于添加模型层
对比上面两个模型结构图
我们看layer4这个
原始的layer4只有一个maxpooling层。然后后面就接一些全连接层和softmax分类。
我们在想把gap和shuffle天加到llayer4,然后把fc层替换成一个线性分类层。
首先是添加,分为在模型内添加和在模型后面添加,这个部分可以参考这个教学视屏。从第15分钟以后开始看,就知道到如何添加模型了。
这个是在模型的layer4中添加模块,你看我门指定了layer4这个层
CNN_shuffmodel.layer4.add_module('add_shuffle',Shufflechnalles())
CNN_shuffmodel.layer4.add_module('add_AGP',nn.AdaptiveAvgPool2d((1,1)))
我们可以直接在模型最后添加一个新的层
#在最后一层层增加一个shuffle层和一个全局平局池化
CNN_shuffmodeladd_module('add_shuffle',Shufflechnalles())
CNN_shuffmodel.add_module('add_AGP',nn.AdaptiveAvgPool2d((1,1)))
直接这样就行了。
6. 关于替换部分层
classifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(50 * 1 * 1, 10))]))
CNN_shuffmodel.fc = classifier
7. 关于删除部分层
其实删除模型层就是替换模型部分层,我们只需要写一个空层替换局可以了,
如下:
classifier = nn.Sequential()
CNN_shuffmodel.fc = classifier
删除层就是这么简单。
8. 关于冻结部分层
我们现在只想训练最后的fc1层,然后就有了下面的
for name, value in model_conv.named_parameters():
if (name != 'fc.weight') and (name != 'fc.bias'):
value.requires_grad = True
optimizer = optim.Adam(filter(lambda p: p.requires_grad, CNN_shuffmodel.parameters()), lr=learning_rate)
从上面看,我们指定只训练 最后一层的权值和偏置
所以代码的意思是,如果名字不是fc.weight和fc.bias就不训练。
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
filter()函数将requires_grad = True的参数传入优化器进行反向传播,requires_grad = False的则被过滤掉。
说实话,上面这种方法我用的时候报错了,至今还没解决,于是我想出来了一个新的方法
也就是追层修改
for para in CNN_shuffmodel.layer1.parameters():
para.requires_grad = False
for para in CNN_shuffmodel.layer2.parameters():
para.requires_grad = False
for para in CNN_shuffmodel.layer3.parameters():
para.requires_grad = False
for para in CNN_shuffmodel.layer4.parameters():
para.requires_grad = False
optimizer = optim.Adam(filter(lambda p: p.requires_grad, CNN_shuffmodel.parameters()), lr=learning_rate)
这个方法在我的实验中没有报错
9. 关于add_module()模块的用法
这个模块算法pytorch的一个比较进阶的用法了,用法是主要是调用backbone时候会用到。
add_module()可以快速地替换特定结构可以不用修改过多的代码。
add_module的功能为Module添加一个子module,对应名字为name。使用方式如下:
add_module(name, module)
其中name为子模块的名字,使用这个名字可以访问特定的子module。module为我们自定义的子module。
一般情况下子module都是在A.init(self)中定义的,比如A中一个卷积子模块self.conv1 = torch.nn.Conv2d(…)。此时,这个卷积模块在A的名字其实是’conv1’。
对比之下,add_module()函数就可以在A.init(self)以外定义A的子模块。如定义同样的卷积子模块,可以通过A.add_module(‘conv1’, torch.nn.Conv2d(…))。
例如:
9.1 一般用法
import torch
class Net3(torch.nn.Module):
def __init__(self):
super(Net3, self).__init__()
self.conv=torch.nn.Sequential()
self.conv.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))
self.conv.add_module("relu1",torch.nn.ReLU())
self.conv.add_module("pool1",torch.nn.MaxPool2d(2))
self.dense = torch.nn.Sequential()
self.dense.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))
self.dense.add_module("relu2",torch.nn.ReLU())
self.dense.add_module("dense2",torch.nn.Linear(128, 10))
def forward(self, x):
conv_out = self.conv1(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense(res)
return out
model3 = Net3()
print(model3)
输出结果
Net3(
(conv): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense): Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
)
9.2 更高级的用法
class Policy(nn.Module):
def __init__(self, input_size, output_size, hidden_sizes=(),nonlinearity=F.relu, init_std=0.1, min_std=1e-6):
super(Policy, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.hidden_sizes = hidden_sizes
self.nonlinearity = nonlinearity
self.min_log_std = math.log(min_std)
self.num_layers = len(hidden_sizes) + 1
self.is_disc_action = False
layer_sizes = (input_size,) + hidden_sizes
for i in range(1, self.num_layers):
self.add_module('layer{0}'.format(i),
nn.Linear(layer_sizes[i - 1], layer_sizes[i]))
self.mu = nn.Linear(layer_sizes[-1], output_size)
self.sigma = nn.Parameter(torch.Tensor(output_size))
self.sigma.data.fill_(math.log(init_std))
self.apply(_weight_init)
def forward(self, input, params=None):
if params is None:
params = OrderedDict(self.named_parameters())
output = input
for i in range(1, self.num_layers):
output = F.linear(output,
weight=params['layer{0}.weight'.format(i)],
bias=params['layer{0}.bias'.format(i)])
output = self.nonlinearity(output)
mu = F.linear(output, weight=params['mu.weight'],
bias=params['mu.bias'])
scale = torch.exp(torch.clamp(params['sigma'], min=self.min_log_std))
return Normal(loc=mu, scale=scale)
主要是自动命名每一层的名字
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)