目录:
1.定义使用结构体变量
2.使用结构体数组
3.结构体指针
4.结构体内存对齐(重点)
5.typedef的使用
6.动态内存的分配与释放
7.链表的创立、增删查改插
什么是链表?
静态链表和动态链表
链表的创立
链表的插入元素
链表的删除元素
链表的查找元素
链表的更新元素
链表的添加元素
由于博主水平有限,所以博客中难免会出现错误,如果发现,可以加以指正,博主会在第一时间修改。此外,博客中采用部分C语言中文网上的内容C语言中文网
1.定义和使用结构体变量
1.1结构体类型是做什么的?
思考,我们能不能使用一个变量存储一个学生的学号,姓名,性别,年龄,出生年月等个人的基本信息(也就是一个变量代表一个学生,一个变量能查找一个学生的所有信息),像我们学的int、float等基本数据类型是做不到的,你可能会想到数组,但是数组元素的数据类型是相同的,我们的姓名需要使用字符串来存储,年龄是需要int类型的来存储,所以数组也不行。于是C语言便允许用户建立由不同类型数据组合的组合型数据结构——结构体类型
1.2结构体类型的定义与使用
定义格式:
struct 结构体名{
成员列表
};
注意两个概念:
1.结构体名:用于区别其他结构体类型
2.结构体类型名:struct + 结构体名=结构体类型名
比如我们要定义一个结构体类型用于来存储一个学生的信息:
struct Date{
int month;
int day;
int year;
};
struct student{
int num;
char name[20];
char sex;
int age;
struct Date birthday;
char addr[30];
}
已经定义结构体类型(相当于一个模板),我们有三种定义结构体类型变量(相当于一个学生的实体)的方法:
1.先声明结构体类型,再定义结构体变量
#include<stdio.h>
struct Date{
int month;
int day;
int year;
};
struct student{
int num;
char name[20];
char sex;
int age;
struct Date birthday;
char addr[30];
};
int main()
{
struct student student1;
}
2.在声明类型的同时定义变量
struct 结构体名{
成员列表
}变量名列表;
例子:
struct student{
int num;
char name[20];
char sex;
int age;
struct Date birthday;
char addr[30];
}student1,student2;
3.不直接类型名直接定义结构体类型变量
struct{
成员列表
}变量名列表;
注意:当我们使用这种方法定义结构体类型时,变量只能在变量名列表处定义,不能再定义其他的变量,因为这种方式定义的结构体类型没有结构体名
注意:结构体类型在编译时是不分配空间的,只对变量分配空间
1.3结构体变量的使用
结构体变量的使用:
结构体变量名.成员名能引用结构体变量里面的各个属性
#include<stdio.h>
struct Date{
int month;
int day;
int year;
};
struct student{
int num;
char name[20];
char sex;
int age;
struct Date birthday;
char addr[30];
};
int main()
{
struct student student1;
printf("请输入学生的学号:");
scanf("%d",&student1.num);
printf("请输入学生的姓名:");
scanf("%s",student1.name);
printf("请输入学生的性别(M/W):");
getchar();
scanf("%c",&student1.sex);
printf("请输入学生的年龄:");
scanf("%d",&student1.age);
printf("请输入学生的地址:");
scanf("%s",student1.addr);
printf("请分别输入学生出生年、月、日:");
scanf("%d%d%d",&student1.birthday.year,&student1.birthday.month,&student1.birthday.day);
printf("该学生的学号为:%d\n",student1.num);
printf("该学生的姓名为:%s\n",student1.name);
printf("该学生的性别为:%c\n",student1.sex);
printf("该学生的年龄为:%d\n",student1.age);
printf("该学生的地址为:%s\n",student1.addr);
printf("该学生的出生年月为:%d %d %d",student1.birthday.year,student1.birthday.month,student1.birthday.day);
}
请输入学生的学号:1001
请输入学生的姓名:张三
请输入学生的性别(M/W):M
请输入学生的年龄:18
请输入学生的地址:南阳
请分别输入学生出生年、月、日:2000 10 12
该学生的学号为:1001
该学生的姓名为:张三
该学生的性别为:M
该学生的年龄为:18
该学生的地址为:南阳
该学生的出生年月为:2000 10 12
--------------------------------

2.结构体数组
2.1结构体数组的定义
1.在定义结构体类型的时候定义结构体数组:
struct 结构体名{
成员列表
}数组名[数组长度];
2.使用结构体类型名定义结构体数组
结构体类型名 数组名[数组长度];
2.2结构体数组的初始化
其实和int等类型的数组初始化差不多,举个栗子:
#include<stdio.h>
struct student{
int num;
char name[20];
};
int main()
{
struct student stu[2]={1001,"张三",1002,"李四"};
for(int i=0;i<2;i++)
{
printf("第%d个学生的学号是:%d\n",i+1,stu[i].num);
printf("第%d个学生的姓名是:%s\n",i+1,stu[i].name);
}
}
第1个学生的学号是:1001
第1个学生的姓名是:张三
第2个学生的学号是:1002
第2个学生的姓名是:李四
--------------------------------

3.结构体指针
如果对指针操作不熟悉的话,可以参照这一篇博客:万字长文搞定C语言指针
3.1指向结构体变量的指针
定义结构体指针:结构体类型名+结构体指针
使用结构体指针:(*结构体指针).属性或者结构体指针->属性
例子:
#include<stdio.h>
struct student{
int num;
char name[20];
};
int main()
{
struct student *stu;
struct student s;
printf("请输入学生的学号:");
scanf("%d",&s.num);
printf("请输入学生的姓名:");
scanf("%s",s.name);
stu=&s;
printf("该学生的学号为:%d\n",stu->num);
printf("该学生的姓名为:%s",stu->name);
}
3.2指向结构体数组的指针
例子:
#include<stdio.h>
struct student{
int num;
char name[20];
};
int main()
{
struct student stu[2]={1001,"张三",1002,"李四"};
struct student *p;
int i=1;
for(p=stu;p<stu+2;p++)
{
printf("第%d个学生的学号是:%d\n",i,p->num);
printf("第%d个学生的姓名是:%s\n",i,p->name);
i++;
}
}
3.3结构体指针作为函数参数
结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
#include <stdio.h>
struct stu{
char *name;
int num;
int age;
char group;
float score;
}stus[] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
void average(struct stu *ps, int len);
int main(){
int len = sizeof(stus) / sizeof(struct stu);
average(stus, len);
return 0;
}
void average(struct stu *ps, int len){
int i, num_140 = 0;
float average, sum = 0;
for(i=0; i<len; i++){
sum += (ps + i) -> score;
if((ps + i)->score < 140) num_140++;
}
printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
}
sum=707.50
average=141.50
num_140=2

4.结构体内存对齐(重点)
我们定义一个结构体变量,查看所占据的内存字节数:
#include<stdio.h>
struct Date{
int month;
int day;
int year;
};
struct student{
int num;
char name[20];
char sex;
int age;
struct Date birthday;
char addr[30];
};
int main()
{
struct student stu1;
printf("%d",sizeof(stu1));
}
我们按照正常的思路,num为int类型占据4个字节,name数组占据20个字节,sex占据1个字节,age占据4个字节,birthday占据12个字节,addr占据30个字节,一共是71个字节,为啥会是76个字节大小呢。这就牵扯到C语言的内存对齐问题。
结构体对齐原则一:
结构体中元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每一个元素放置到内存中时,它都会认为内存是以它自己的大小来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始(以结构体变量首地址为0计算)
#include <iostream>
using namespace std;
struct X
{
char a;
int b;
double c;
};
int main()
{
printf("%d",sizeof(X));
}
比如上面例子(占据16个字节):首先系统会将字符型变量a存入第0个字节(相对地址,指内存开辟的首地址);然后在存放整形变量b时,会以4个字节为单位进行存储,由于第一个四字节模块已有数据,因此它会存入第二个四字节模块,也就是存入到4~8字节;同理,存放双精度实型变量c时,由于其宽度为8,其存放时会以8个字节为单位存储,也就是会找到第一个空的且是8的整数倍的位置开始存储,此例中,此例中,由于头一个8字节模块已被占用,所以将c存入第二个8字节模块。整体存储示意图如图1所示。

原则二:
在经过第一原则分析后,检查计算出的存储单元是否为所有元素中最宽的元素的长度的整数倍,是,则结束;若不是,则补齐为它的整数倍
#include <iostream>
using namespace std;
struct X
{
char a;
double b;
int c;
};
int main()
{
printf("%d",sizeof(X));
}
上面这个例子中:我们分析完后的存储长度为20字节,不是最宽元素长度8的整数倍,因此将它补齐到8的整数倍,也就是24。这样就没问题了。其存储示意图如图2所示。

当成员变量里含有指针、数组或是其它结构体变量
1.包含指针类型的情况。只要记住指针本身所占的存储空间是8个字节就行了,而不必看它是指向什么类型的指针。
2.包含结构体类型时,检查计算出的存储单元是否为所有元素(也包括所含结构体变量的元素)中最宽的元素的长度的整数倍
3.包含数组类型,内存对齐时只看基类型,如果数组基类型宽度最大,那么内存补齐时要是这个基类型的整数倍
此时开头的问题就能迎刃而解了:
#include<stdio.h>
struct Date{
int month;
int day;
int year;
};
struct student{
int num;
char name[20];
char sex;
int age;
struct Date birthday;
char addr[30];
};
int main()
{
struct student stu1;
printf("stu1首地址:%d\n",&stu1);
printf("num首地址:%d\n",&stu1.num);
printf("name首地址:%d\n",stu1.name);
printf("sex首地址:%d\n",&stu1.sex);
printf("age首地址:%d\n",&stu1.age);
printf("birthday首地址:%d\n",&stu1.birthday);
printf("addr首地址:%d\n",stu1.addr);
printf("stu1占据总的字节数是:%d\n",sizeof(stu1));
}
stu1首地址:6684112
num首地址:6684112
name首地址:6684116
sex首地址:6684136
age首地址:6684140
birthday首地址:6684144
addr首地址:6684156
stu1占据总的字节数是:76
--------------------------------

5.typedef的使用
C语言允许为一个数据类型起一个新的别名,就像给人起“绰号”一样。
起别名的目的不是为了提高程序运行效率,而是为了编码方便。例如有一个结构体的名字是 stu,要想定义一个结构体变量就得这样写:
struct stu stu1;
struct 看起来就是多余的,但不写又会报错。如果为 struct stu 起了一个别名 STU,书写起来就简单了:
STU stu1;
这种写法更加简练,意义也非常明确,不管是在标准头文件中还是以后的编程实践中,都会大量使用这种别名。
使用关键字 typedef 可以为类型起一个新的别名。typedef 的用法一般为:
typedef oldName newName;
oldName 是类型原来的名字,newName 是类型新的名字。例如:
typedef int INTEGER;
INTEGER a, b;
a = 1;
b = 2;
INTEGER a, b;等效于int a, b;。
typedef 还可以给数组、指针、结构体等类型定义别名。先来看一个给数组类型定义别名的例子:
typedef char ARRAY20[20];
表示 ARRAY20 是类型char [20]的别名。它是一个长度为 20 的数组类型。接着可以用 ARRAY20 定义数组:
ARRAY20 a1, a2, s1, s2;
它等价于:
char a1[20], a2[20], s1[20], s2[20];
又如,为结构体类型定义别名:
typedef struct stu{
char name[20];
int age;
char sex;
} STU;
STU 是 struct stu 的别名,可以用 STU 定义结构体变量:
STU body1,body2;
它等价于:
struct stu body1, body2;
再如,为指针类型定义别名:
typedef int (*PTR_TO_ARR)[4];
表示 PTR_TO_ARR 是类型int * [4]的别名,它是一个二维数组指针类型。接着可以使用 PTR_TO_ARR 定义二维数组指针:
PTR_TO_ARR p1, p2;
按照类似的写法,还可以为函数指针类型定义别名:
typedef int (*PTR_TO_FUNC)(int, int);
PTR_TO_FUNC pfunc;
对于给函数指针类型定义别名:
我们知道,单独的int (*p)(int,int),p代表定义了一个函数指针(其返回值为int,两个int形参数),
#include<stdio.h>
int max(int a,int b)
{
return a>b?a:b;
}
int main()
{
int (*p)(int,int);
p=max;
int a=(*p)(20,30);
printf("%d",a);
}
如果变成typedef int (*p)(int,int)。p就变成定义函数指针变量的一个类型,就像int一样,int a代表定义一个整形变量,p a,代表定义一个函数指针变量,p a还等同于int (*a)(int,int)
#include<stdio.h>
int max(int a,int b)
{
return a>b?a:b;
}
int main()
{
typedef int (*p)(int,int);
p a;
a=max;
int c=(*a)(20,30);
printf("%d",c);
}
同样的对于typedef char (*PTR_TO_ARR)[30];
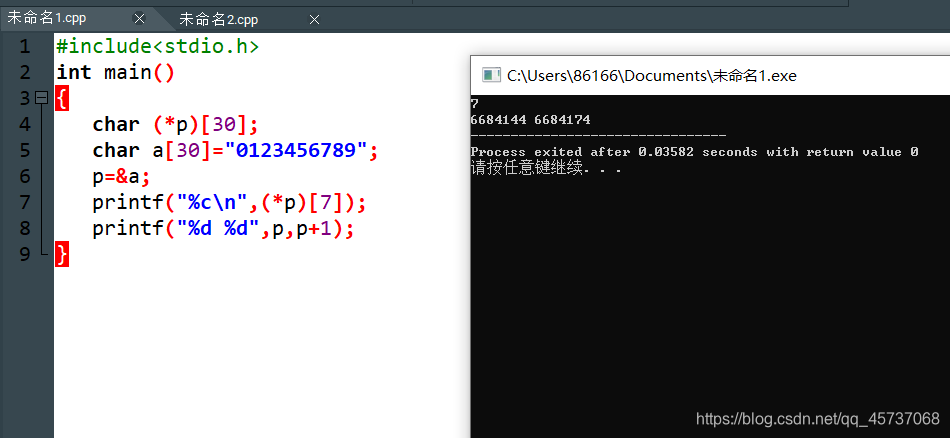
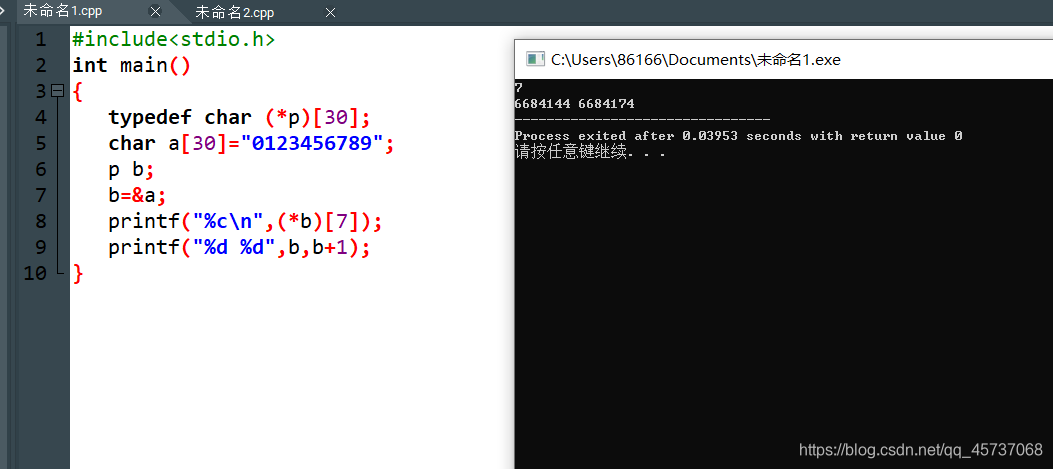
#include <stdio.h>
typedef char (*PTR_TO_ARR)[30];
typedef int (*PTR_TO_FUNC)(int, int);
int max(int a, int b){
return a>b ? a : b;
}
char str[3][30] = {
"http://c.biancheng.net",
"C语言中文网",
"C-Language"
};
int main(){
PTR_TO_ARR parr = str;
PTR_TO_FUNC pfunc = max;
int i;
printf("max: %d\n", (*pfunc)(10, 20));
for(i=0; i<3; i++){
printf("str[%d]: %s\n", i, *(parr+i));
}
return 0;
}
typedef 和 #define 的区别
typedef 在表现上有时候类似于 #define,但它和宏替换之间存在一个关键性的区别。正确思考这个问题的方法就是把 typedef 看成一种彻底的“封装”类型,声明之后不能再往里面增加别的东西。#define是在预编译时进行简单的字符串替换,而typedef是在编译阶段完成的
- 可以使用其他类型说明符对宏类型名进行扩展,但对 typedef 所定义的类型名却不能这样做。因为使用typedef相当于定义一个新的类型如下所示:
#define INTERGE int
unsigned INTERGE n;
typedef int INTERGE;
unsigned INTERGE n;
- 在连续定义几个变量的时候,typedef 能够保证定义的所有变量均为同一类型,而 #define 则无法保证。例如:
#define PTR_INT int *
PTR_INT p1, p2;
经过宏替换以后,第二行变为:
int *p1, p2;
这使得 p1、p2 成为不同的类型:p1 是指向 int 类型的指针,p2 是 int 类型。
相反,在下面的代码中:
typedef int * PTR_INT
PTR_INT p1, p2;
p1、p2 类型相同,它们都是指向 int 类型的指针。

6.动态内存分配与释放
C语言内存简介
| 内存区域 | 内容 |
|---|
| 栈区 | 存放函数的参数值、局部变量等,由编译器自动分配和释放,通常在函数执行完后就释放了,其操作方式类似于数据结构中的栈 |
| 堆区 | 就是通过new、malloc、realloc分配的内存块,编译器不会负责它们的释放工作,需要用程序区释放。分配方式类似于数据结构中的链表。“内存泄漏”通常说的就是堆区。 |
| 静态区 | 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后,由系统释放。 |
| 常量区 | 常量存储在这里,不允许修改。 |
| 代码区 | 顾名思义,存放代码 |
1.void *malloc(unsigned int size):作用是在动态存储区中分配一个长度为size的连续空间,unsigned代表没有符号位的整形数据(非负整数),返回所分配内存区域第一个字节的地址.分配失败返回NULL指针
2.void *calloc(unsigned n,unsigned size):作用是在动态内存空间中分配n个长度为size的连续空间,分配失败返回NULL指针
3.void free(void *p):释放指针变量p所指向的动态空间
4.void *realloc(void *p,unsigned int size):对已经通过malloc函数calloc函数获得了动态空间,想改变其大小,用此函数重新分配
注意:void*类型的指针表示指向空类型或者不指向确定的类型的数据
以上函数得使用#include<stdlib.h>
使用举例:
#include<stdio.h>
#include<stdlib.h>
int main()
{
int i=0;
int *p=(int*)malloc(4);
*p=3;
printf("%d\n",*p);
free(p);
}
7.链表的创立、增删查改插
7.1什么是链表?
当一个班级有50个人,那么我们需要定义数组长度为50的结构体数组来存储这些学生的信息,如果新来了几个学生,那么我们则需要再重新定义一个更大的数组,比如60个大小(你不能申请一个足够大的数组,这样做太浪费内存空间)。这时候就可以用我们的链表存储。
链表是一种动态的进行存储分配的一种结构
看下面一段代码:
struct student{
int num;
char name[20];
struct student *next;
}
上面一段代码中,结构体类型是struct student,存储着学生的基本信息,里边还有一个struct student *next成员变量,他是一个指向struct student类型数据的指针,也就是说,他的存储结构可以如下所示:
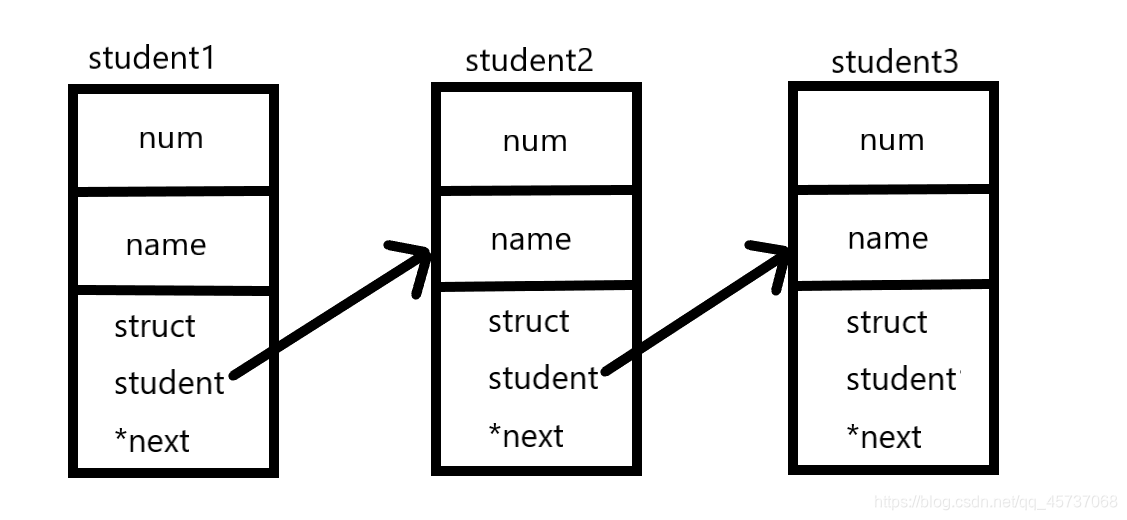
这种能够把数据之间进行连接的数据结构称为链表,链表中的每一个元素称为结点,每个结点中存放指针的空间称为指针域,存放其他信息的空间称为数据域。
一般的链表有头指针,头结点,尾结点指向NULL,如下:
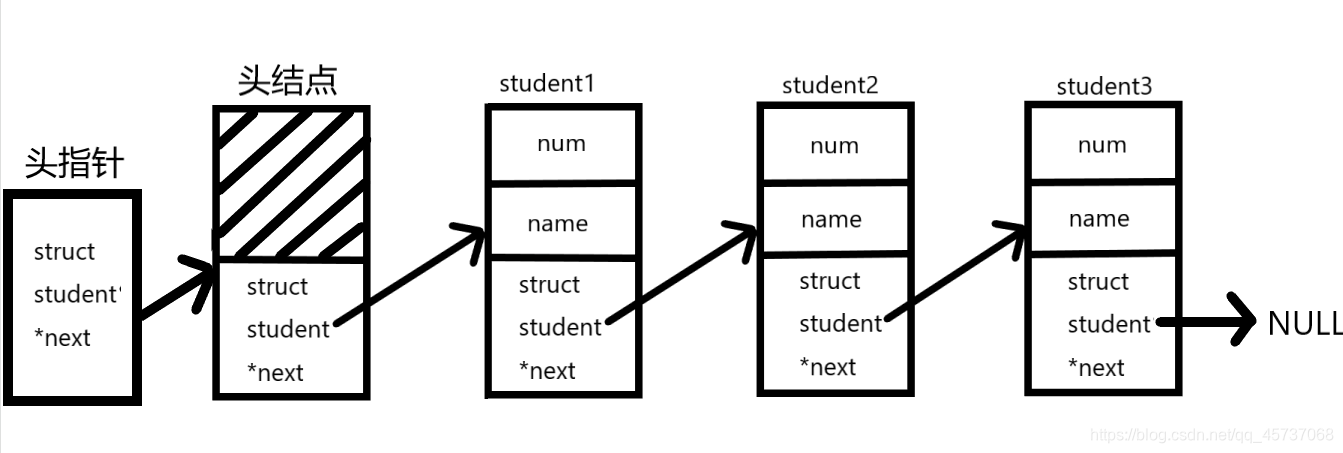
我们可以把链表想象成一个火车,头结点相当于火车头,火车头负责连接第一节车厢,火车头里边不放乘客只是与第一个存放乘客的车厢建立联系(相当于数据域不赋值,指针域指向第一个结点)
头结点:头结点不是链表必须的部分,有了头结点,在对第一个结点前插入或者删除第一个结点就和其余结点统一了
头指针:头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针。头指针是链表的必要元素
实例:
#include<stdio.h>
struct student{
int num;
char name[20];
struct student *next;
};
int main()
{
struct student stu2={1002,"李四",NULL};
struct student stu1={1001,"张三",&stu2};
struct student stu0;
stu0.next=&stu1;
struct student *head=&stu0;
struct student *p=head->next;
int i=1;
while(p!=NULL)
{
printf("第%d个学生的学号为:%d",i,p->num);
printf("第%d个学生的姓名为:%s\n",i,p->name);
i++;
p=p->next;
}
}
第1个学生的学号为:1001第1个学生的姓名为:张三
第2个学生的学号为:1002第2个学生的姓名为:李四
--------------------------------
上面程序对应下图:
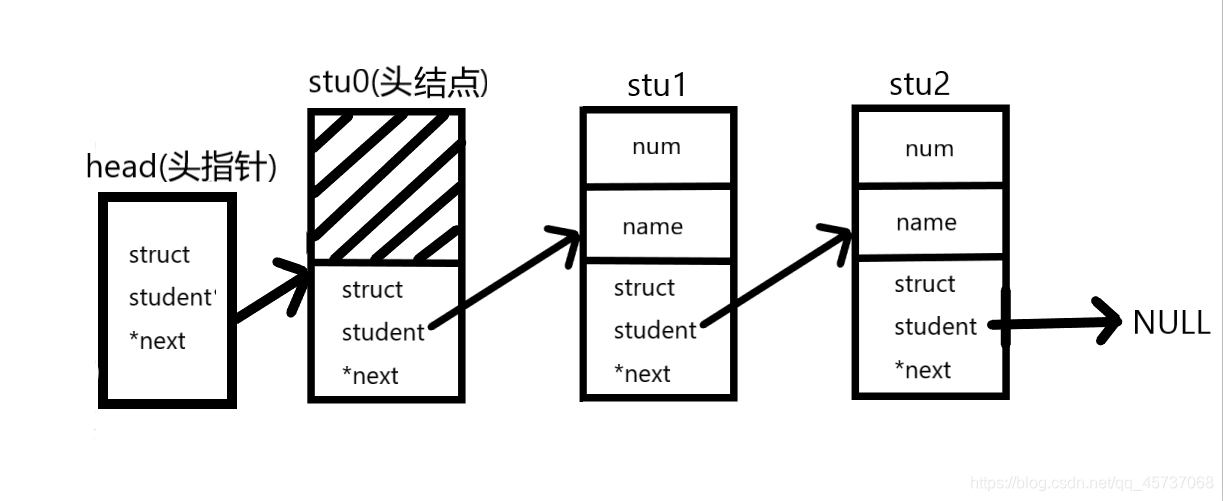
7.2静态链表,动态链表
所有结点都是在程序中定义的,不是我们自己申请的内存(由系统自动分配内存空间),用完后系统自动释放,这种链表称为静态链表。如7.1的例子就是如此,所谓动态链表就是我们手动开辟内存存放结点,需要回收时我们手动释放的链表
7.3链表的创建
代码实现:
typedef struct Link{
int elem;
struct Link *next;
}link;
link * initLink(){
link * p=(link*)malloc(sizeof(link));
link * temp=p;
for (int i=1; i<5; i++) {
link *a=(link*)malloc(sizeof(link));
a->elem=i;
a->next=NULL;
temp->next=a;
temp=temp->next;
}
return p;
}
从实现代码中可以看到,该链表是一个具有头节点的链表。由于头节点本身不用于存储数据,因此在实现对链表中数据的"增删查改"时要引起注意。

7.4链表的插入元素
根据添加位置不同,可分为以下 3 种情况:
- 插入到链表的头部(头节点之后),作为首元节点;
- 插入到链表中间的某个位置;
- 插入到链表的最末端,作为链表中最后一个数据元素;
虽然新元素的插入位置不固定,但是链表插入元素的思想是固定的,只需做以下两步操作,即可将新元素插入到指定的位置:
- 将新结点的 next 指针指向插入位置后的结点;
- 将插入位置前结点的 next 指针指向插入结点;
例如,我们在链表 {1,2,3,4} 的基础上分别实现在头部、中间部位、尾部插入新元素 5,其实现过程如图 :

从图中可以看出,虽然新元素的插入位置不同,但实现插入操作的方法是一致的,都是先执行步骤 1 ,再执行步骤 2。
注意:链表插入元素的操作必须是先步骤 1,再步骤 2;反之,若先执行步骤 2,除非再添加一个指针,作为插入位置后续链表的头指针,否则会导致插入位置后的这部分链表丢失,无法再实现步骤 1。
代码实现:
link * insertElem(link * p, int elem, int add) {
link * temp = p;
for (int i = 1; i < add; i++) {
temp = temp->next;
if (temp == NULL) {
printf("插入位置无效\n");
return p;
}
}
link * c = (link*)malloc(sizeof(link));
c->elem = elem;
c->next = temp->next;
temp->next = c;
return p;
}
回想这一句话:
头结点:头结点不是链表必须的部分,有了头结点,在对第一个结点前插入或者删除第一个结点就和其余结点统一了
由于有了头结点,所以插入的时候,在第一个结点前插入就和所有结点进行了统一。否则????(你懂的)
7.5链表的删除元素
从链表中删除指定数据元素时,实则就是将存有该数据元素的节点从链表中摘除,但作为一名合格的程序员,要对存储空间负责,对不再利用的存储空间要及时释放。因此,从链表中删除数据元素需要进行以下 2 步操作:
- 将结点从链表中摘下来;
- 手动释放掉结点,回收被结点占用的存储空间;
其中,从链表上摘除某节点的实现非常简单,只需找到该节点的直接前驱节点 temp,执行一行程序:
temp->next=temp->next->next;
例如,从存有 {1,2,3,4} 的链表中删除元素 3,则此代码的执行效果如图 2 所示:

代码实现:
link * delElem(link * p, int add) {
link * temp = p;
for (int i = 1; i < add; i++) {
temp = temp->next;
if (temp->next == NULL) {
printf("没有该结点\n");
return p;
}
}
link * del = temp->next;
temp->next = temp->next->next;
free(del);
return p;
}
我们可以看到,从链表上摘下的节点 del 最终通过 free 函数进行了手动释放。
同样的因为有了头结点,才会有对所有结点的删除实现统一
7.6链表的查找元素
在链表中查找指定数据元素,最常用的方法是:从表头依次遍历表中节点,用被查找元素与各节点数据域中存储的数据元素进行比对,直至比对成功或遍历至链表最末端的 NULL(比对失败的标志)。
int selectElem(link * p,int elem){
link * t=p;
int i=1;
while (t->next) {
t=t->next;
if (t->elem==elem) {
return i;
}
i++;
}
return -1;
}
注意,遍历有头节点的链表时,需避免头节点对测试数据的影响,因此在遍历链表时,建立使用上面代码中的遍历方法,直接越过头节点对链表进行有效遍历。
7.7链表更新元素
更新链表中的元素,只需通过遍历找到存储此元素的节点,对节点中的数据域做更改操作即可。
link *amendElem(link * p,int add,int newElem){
link * temp=p;
temp=temp->next;
for (int i=1; i<add; i++) {
temp=temp->next;
}
temp->elem=newElem;
return p;
}
7.8链表的添加元素
头插法:
link *(link * p){
link * temp=p;
int count;
printf("请输入要插入的元素数:\n");
scanf("%d",&count);
for(int i=0;i<count;i++){
link *a=(link*)malloc(sizeof(link));
a->elem=i;
a->next=temp->next;
temp->next=a;
}
return p;
}
尾插法:
link *(link * p){
link * temp=p;
int count;
printf("请输入要插入的元素数:\n");
scanf("%d",&count);
while(temp->next!=NULL){
temp=temp->next;
}
for(int i=0;i<count;i++){
link *a=(link*)malloc(sizeof(link));
a->elem=i;
temp->next=a;
a->next=NULL;
temp=a;
}
return p;
}

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)