本文详细记录如何爬取美女图片,并将图片下载保存在本地,同时将图片url进行入库。保存在本地肯定是为了没事能拿出来养养眼啊,那入库就是为了定位图片啊,要懂点技术的话,还能搬运搬运做个小图片网站,不为别的,就是养眼和学习!
本文主要讲思路和方法,源码、数据库、图片文件获取方式见文末!
作者博客(图片效果更明显):https://blog.jiumoz.com/archives/pa-qu-mei-nv-tu-pian-bao-cun-ben-de-yu-ru-mysql-ku
- 先看效果
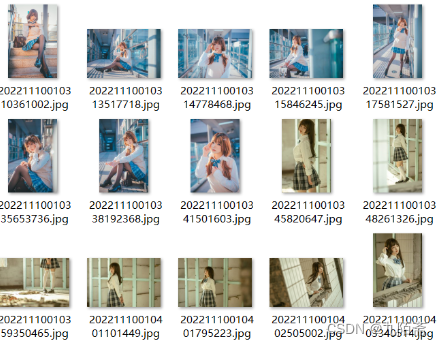
思路部分
解析目标网址
大家看上面的截图肯定就发现了,这网址不寻常(手动狗头),现在这些网站国内都很难活的,网站就不贴出来了。
查看网站情况
查看首页可以基本确定数据加载方式,是分页加载的方式
确定分页加载方式
一般就是两种加载方式,一种是直接改变url,就想旧版的微博,就是直接改变url请求新的网页即可,另一种就是ajax,一般涉及到ajax就比较麻烦,可能有token啥的,不过技术而言,都比较简单,请求就完事。
再看本网站,点击加载更多后,浏览器的url并没有改变,说明就是ajax,那么直接F12打开控制台,调到网络栏,清空信息
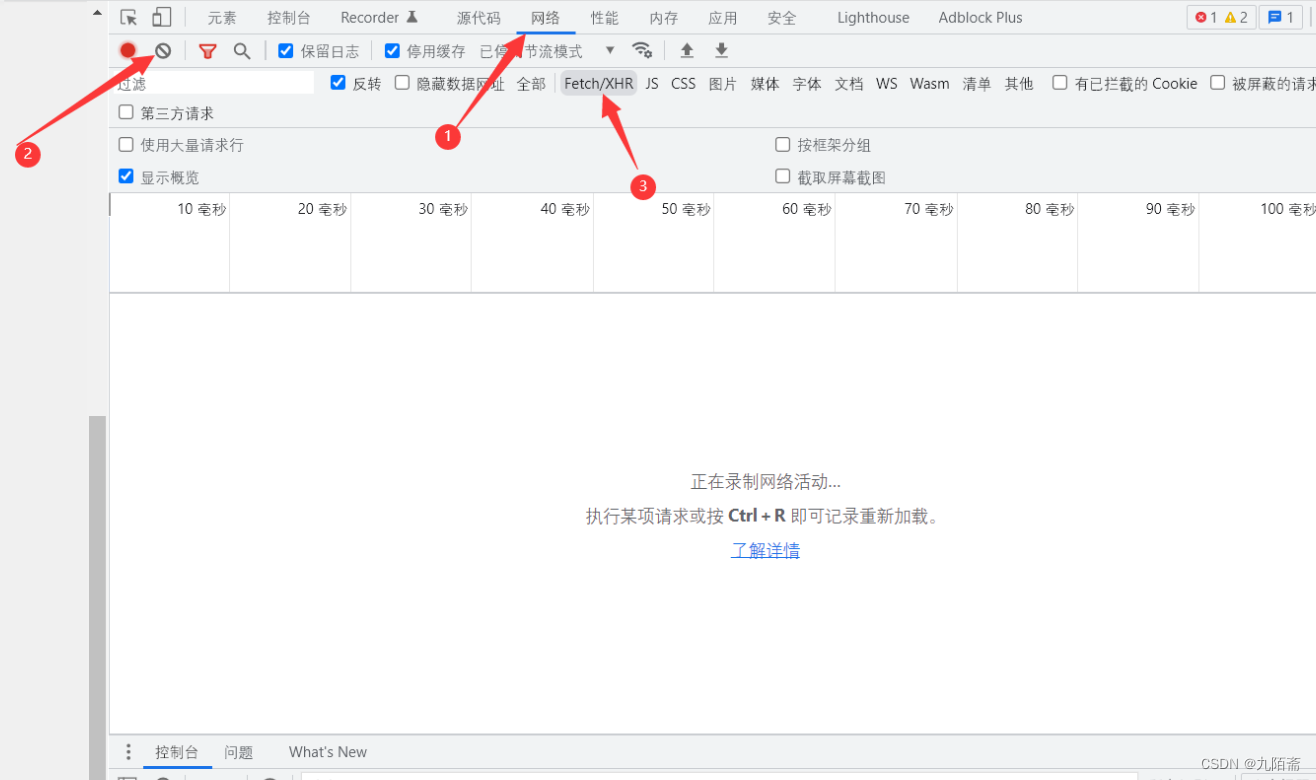
再点击加载更多,我们想要的东西就有了。
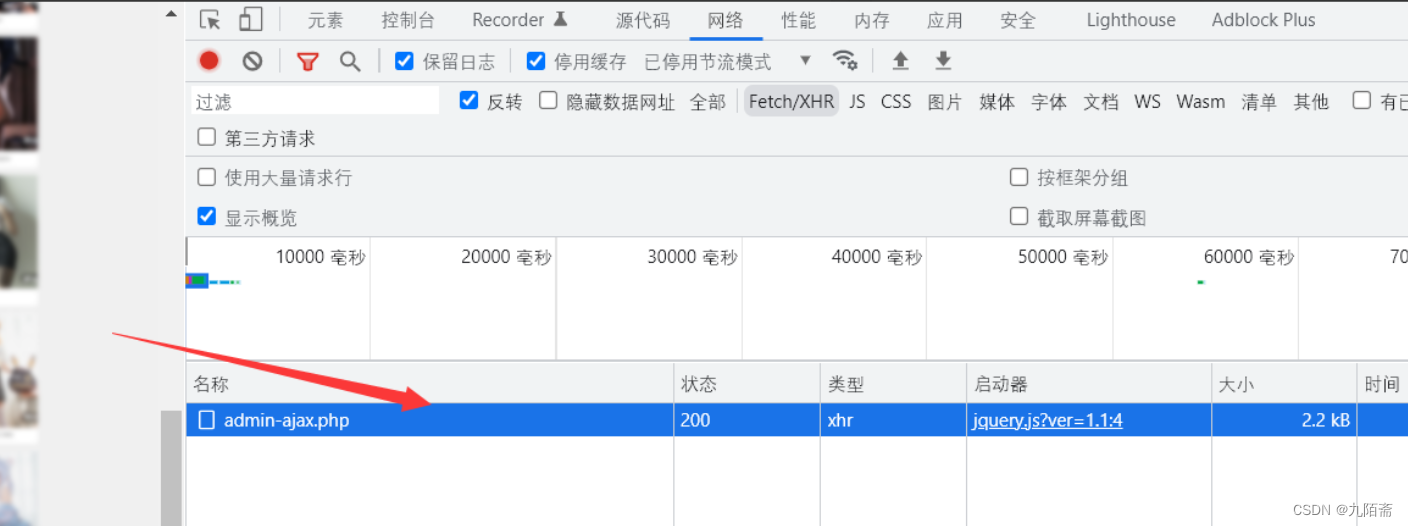
解析分页请求
双击我们抓到的包,查看包的请求网址、请求方法、载荷、响应
-
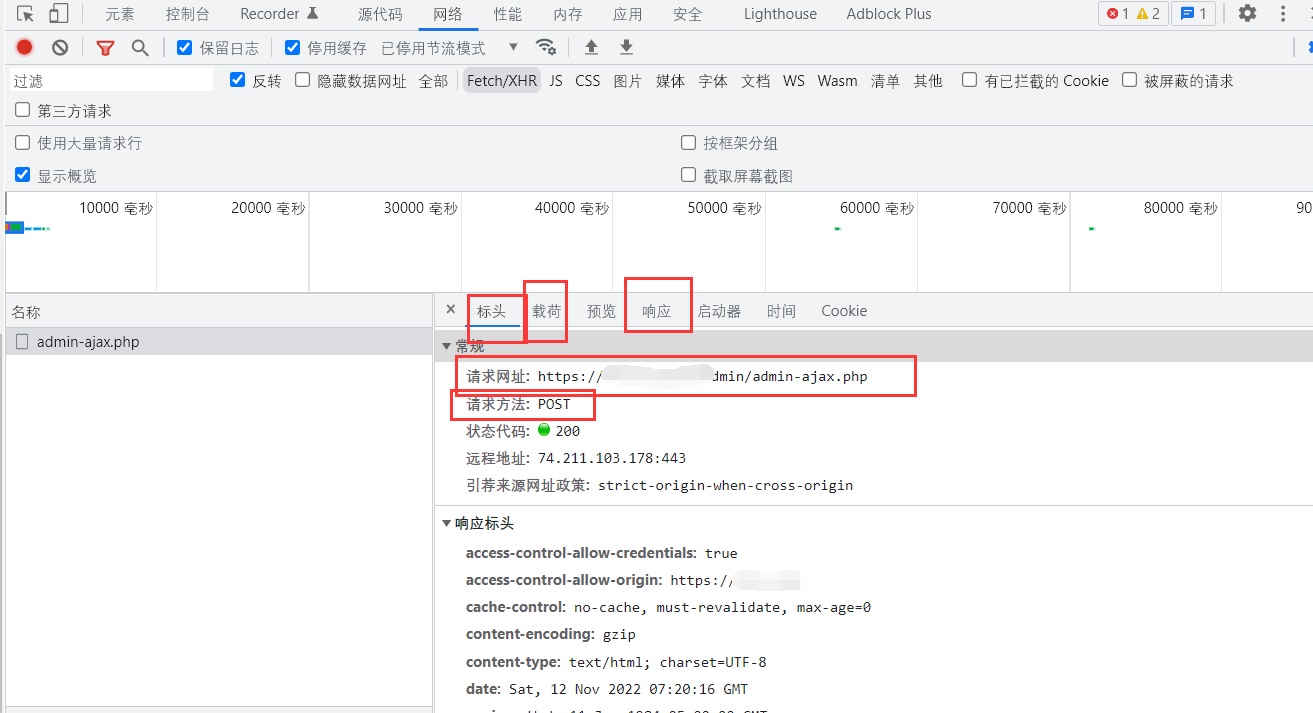
请求网址
即为我们发送请求的地址;
-
请求方法
我们发送请求要用到的方法,很重要,后面写代码就要根据这个来,方法错了请求不到数据;
-
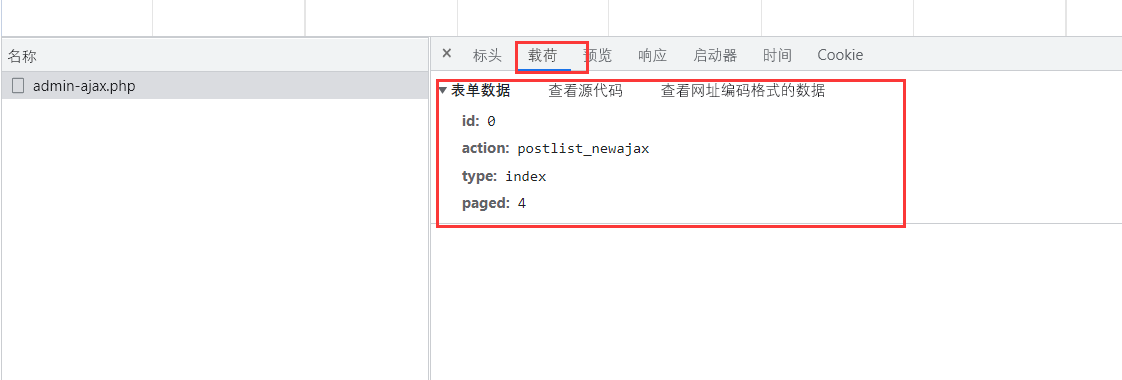
载荷
查看请求的时候给服务器传递了哪些数据,也很重要,取不取得到正确我们想要的数据就完全看这个内容了;
-
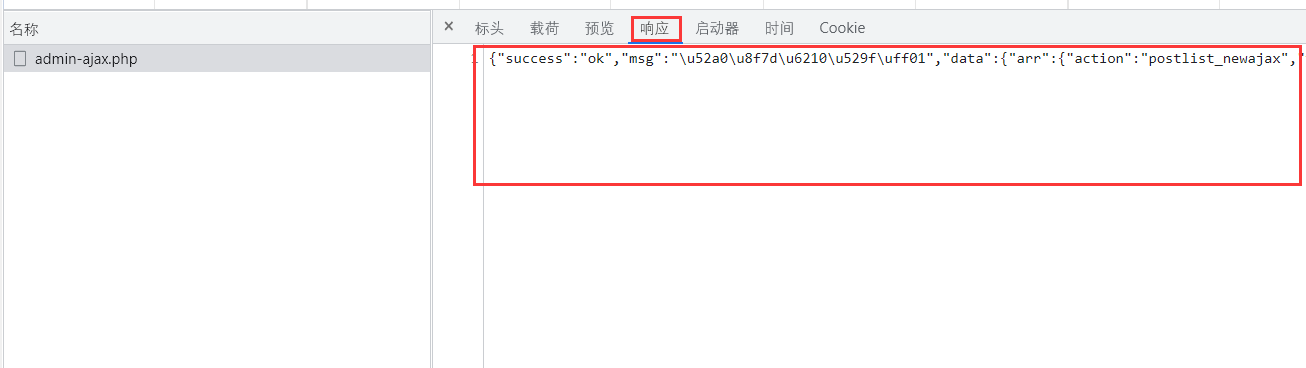
响应
响应的内容就是我们需要的数据,进一步解析就能获得的数据了。
到这里就还没解决一个问题,这个问题就是载荷字段的解析,如上可以发现就是四个字段:id、action、type、paged,其实每个字段都比较好理解,不出意外的话,前三个字段就是死的,主要就是paged字段了,为了验证猜测,再请求一下,查看两个包载荷的不同之处就好了。方法一样,这里就不演示了。事实也证明了我们的猜测,改变paged字段就好。
查看网页结构
继续F12,查看元素,就能发现是一个又一个的li标签了,每个li可以点击进入到对应主题的图片详情界面,得到了这个信息就简单了,就很好获取详情页的url了。
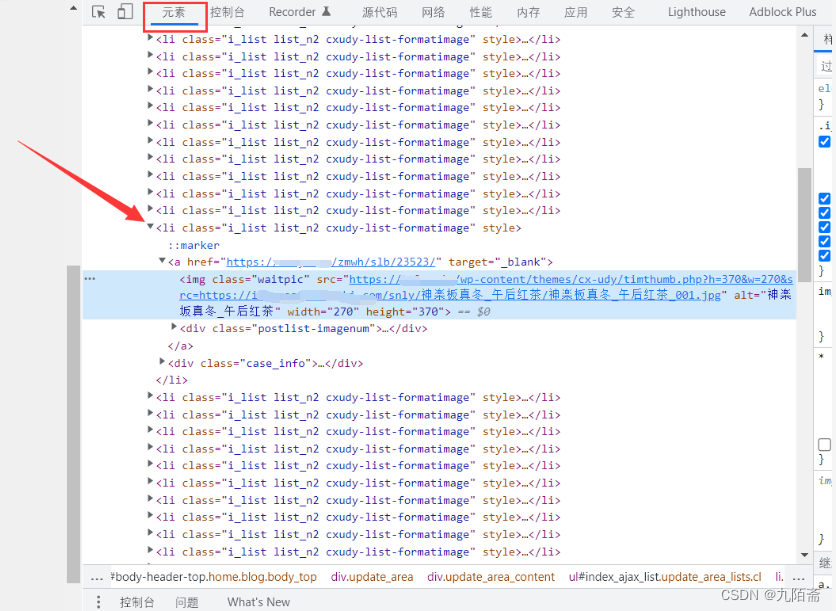
但是页面url没变,不可能通过首页这一个url就能获取到全站的内容,所以还得看看上一步抓的包,如下。
是不是和想象中的不一样,这里是直接请求的网页代码而不是数据,那对于我们来说就更简单了,全文用一种url提取方法就好,将data下的html字段转为html对象就行。

图片详情页
前面说那么多,也都是再讲如何提取每个主题的详情url,具体的图片获取还得是进入详情页啊;
点进来看看,进来一看,发现就是一个一个img标签,那更好了,直接提取图片url就好啊。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-31aPnzBY-1668248824826)(https://kodo.jiumoz.com/imgs/QQ%E6%88%AA%E5%9B%BE20221112154813.png)]](https://img-blog.csdnimg.cn/1b59dc9ece694657b58ede4f064c3b19.png)
但是!!!竟然要VIP,细心的小伙伴应该和我一样,并没有慌啊,为什么呢,看下文
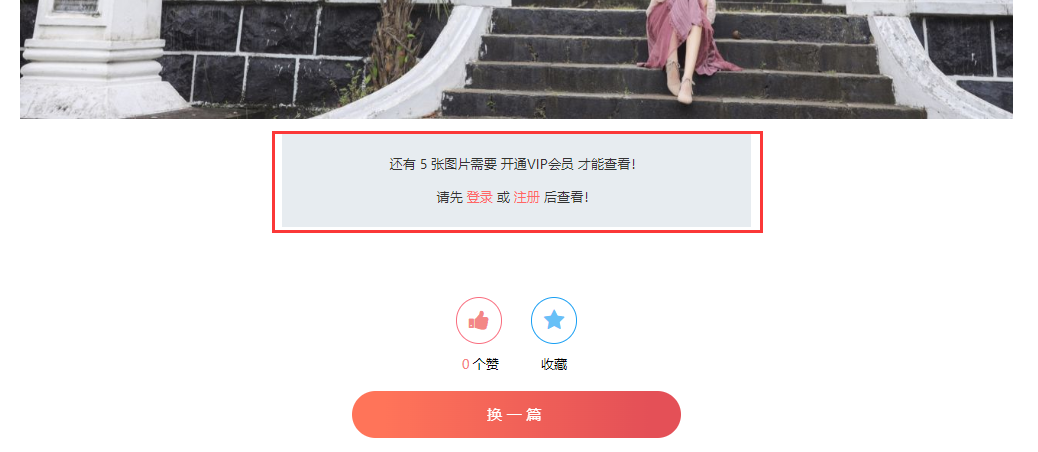
解除VIP限制
确切来说是绕开限制,也就是针对本网站有效,属于是瞎猫碰上死耗子。
回到主题,为什么发现有限制的时候不慌呢,大家在看看图片详情页的网页元素,是不是发现了一些猫腻,所有的图片url,就那一点点地方不一样啊,那我们还爬什么网页,直接构造图片url不就得了。
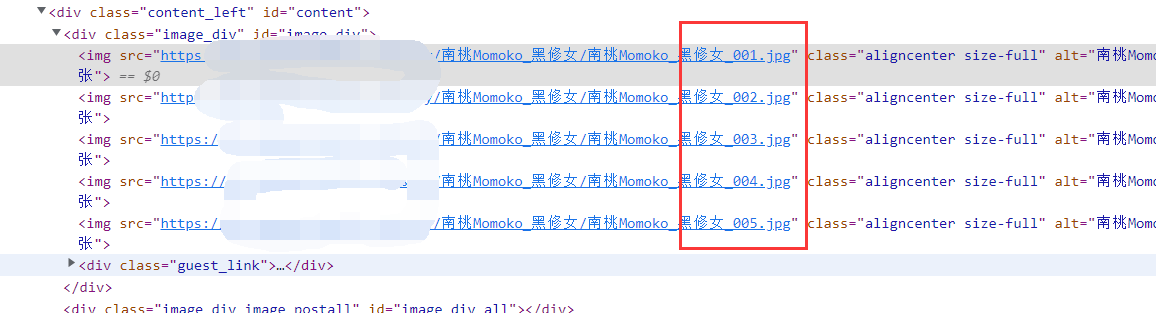
构造图片url
看上面的不同之处,就大致知道每个主题下的图片url规律了,那我们知道第一张图片的url后,构建后面图片的url就好嘛,至于构建到多少,首页和详情页都有,如下,构建这么多就好啦!
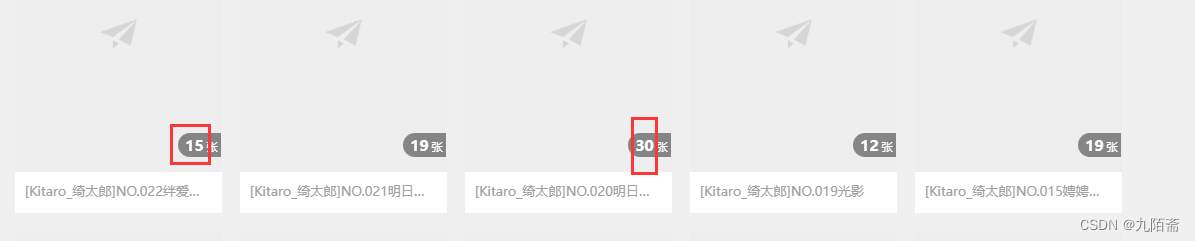
思路很简单,但是构建肯定没那么简单,要确定数字变化的位置、数字的位数、提取数字部分、进行计算、拼接字符串…多看一下网站,会发现这些图片url并不是最后那个数据不一样,并不规则。
但是也不难,就是麻烦点,那就是获取两个url,进行url对比,先提取两个字符串的数字部分形成一个数组,然后对比两个数组中不同的部分,如果不同,获取其下标,根据下标获取到url中那个数字字符串,根据数字字符串进行url分割,再计算和拼接,说的有点泛泛,具体的看代码,此方法还有bug,大家可以再研究一下。
img_id_list1 = re.findall(r"\d+\d*",url1)
img_id_list2 = re.findall(r"\d+\d*", url2)
index = 0
for i in range(len(img_id_list1)):
if(img_id_list1[i] != img_id_list2[i]):
index = i
break
img_id = img_id_list1[index] #图片末尾标识
img_url_pre = url1.split(img_id)[0] # 提取分割后的前半部分
img_url_end = url1.split(img_id)[1] # 提取分割后的后半部分
for i in tqdm(range(img_num)):
img_id_int = int(img_id) # 提取的数字字符串转为int型
img_id_len = len(img_id) # 提取的数字字符串长度
img_id_main_int = img_id_int + i # 数字+1
img_id_main_int_len = len(str(img_id_main_int)) # 加1后长度
img_id_use = '0'*(img_id_len-img_id_main_int_len) + str(img_id_main_int) # 补0
imgurl = img_url_pre+img_id_use+img_url_end # 得到图片url
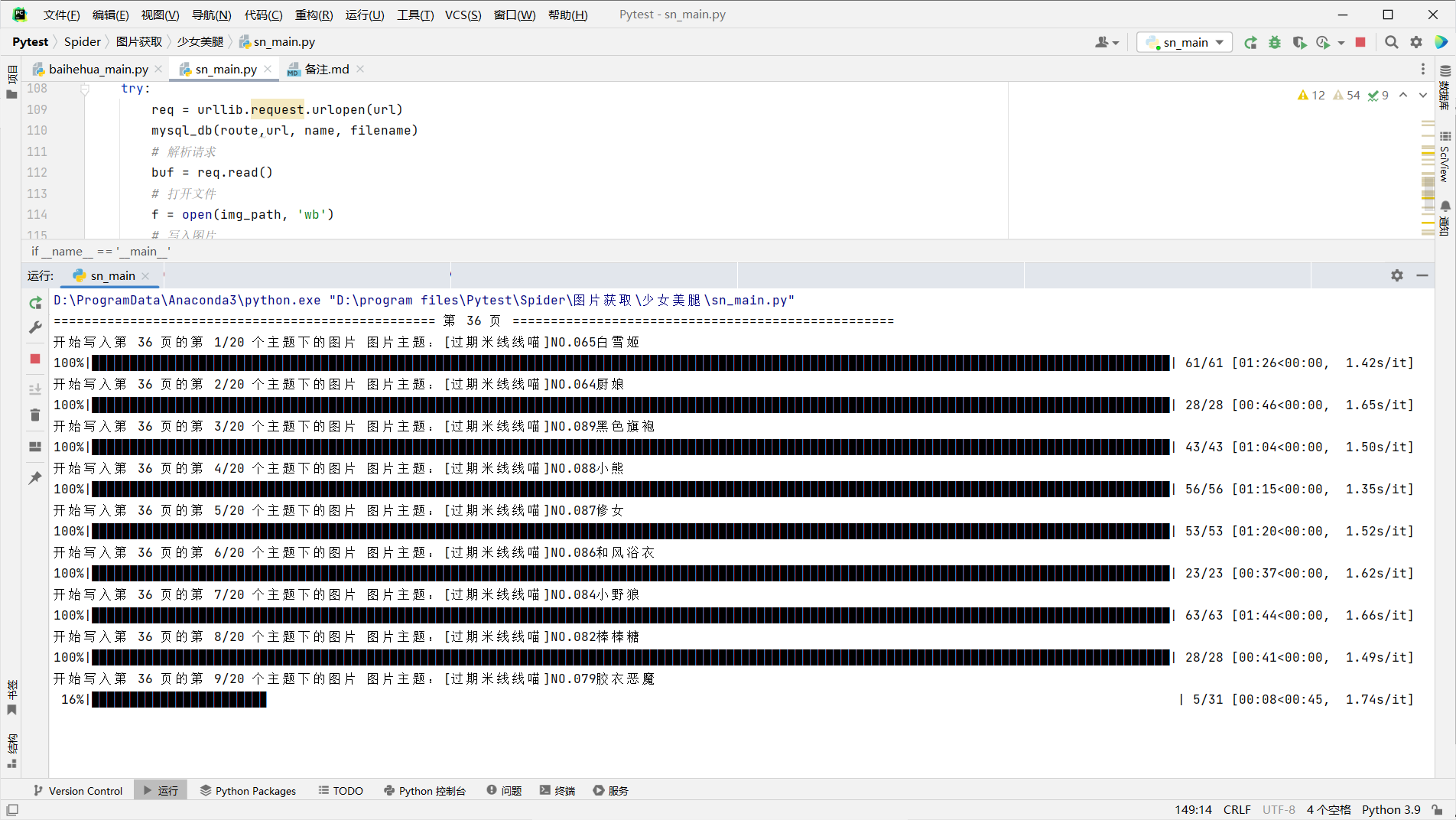
代码部分
请求主题url与基本信息
很简单,利用request包发送请求,利用JSON包解析得到的数据,再利用lxml模块进行url获取就好啦!部分代码如下,不能直接用哦,断断续续的:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
def img_get(page):
start_url = 'https://XXXXXX/admin-ajax.php'
data = {
'id': 0,
'action': 'postlist_newajax',
'type': 'index',
'paged': page
}
import json
try:
response = requests.post(start_url, headers=headers, data=data)
# 序列化成json字符串
json = json.loads(response.text)
if (json['success'] == 'ok'):
# 请求到的html
# print (json['data']['html'])
html = etree.HTML(json['data']['html'], parser=etree.HTMLParser(encoding='utf-8'))
# a标签
a_rr = html.xpath('//a[@target="_blank"]')
a_re = '<a href="(.*?)"'
# 多少张图片
img_num = html.xpath('//div[@class="postlist-imagenum"]/span')
# 标题
img_file_title = html.xpath('//div[@class="case_info"]/a')
获取图片url
同样的办法,不过要先获取到前两张图片url,方法如上,xpath获取就行。代码如下,也不能直接用哦:
response = urllib.request.urlopen(a_href[0]).read().decode("utf-8", "ignore")
img_data = etree.HTML(response) # 转换格式,构造解析对象
img_src1 = img_data.xpath('//*[@id="image_div"]/img[1]/@src') # 进行匹配,提取出来的内容不是列表
if (str(type(img_src1)) == "<class 'list'>"):
pass
else:
img_src1 = [i for i in img_src1]
img_src2 = img_data.xpath('//*[@id="image_div"]/img[2]/@src') # 进行匹配,提取出来的内容不是列表
if (str(type(img_src2)) == "<class 'list'>"):
pass
else:
img_src2 = [i for i in img_src2]
# print("此页第一张图片链接:",img_src1[0])
# print("此页第二张图片链接:", img_src2[0])
保存到本地
方法很简单,代码如下(本示例代码是单独的保存图片代码):
# -*- coding: utf-8 -*-
# @Time: 2022/11/3 15:08
# @Author: MinChess
# @File: save_pic.py
# @Software:
import os
import datetime
import urllib.request
# 创建目录,并返回该目录
def make_dir(path):
# 去除左右两边的空格
path = path.strip()
# 判断该文件是否存在,不存在才创建,存在则跳过
if not os.path.exists(path):
os.makedirs(path)
return path
# 图片保存地址
save_img_path = 'D:\program files\Pytest\Spider\图片获取\pic\\'
path = make_dir(save_img_path)
# 命名图片
filename = path + datetime.datetime.now().strftime('%Y%m%d%H%M%S%f') + '.jpg'
# 打开文件
f = open(filename, 'wb')
# 请求图片
req = urllib.request.urlopen('https://kodo.jiumoz.com/halo/Group-screen.png')
# 解析请求
buf = req.read()
# 写入图片
f.write(buf)
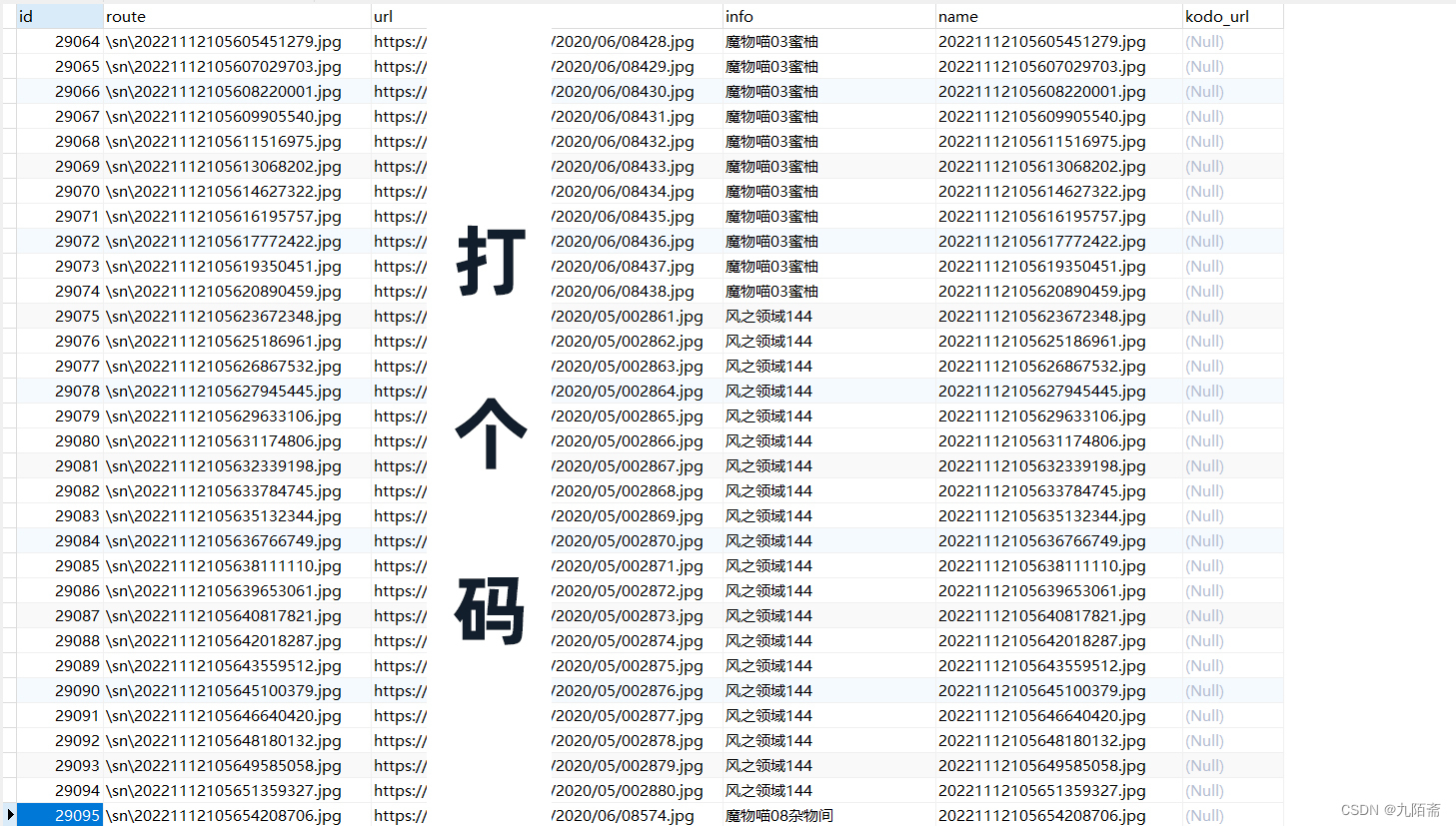
写入数据库
也很简单,建好库,连接后根据字段写好语句就行,主要用到的包是pymysql,代码如下:
def mysql_db(route,url,info,name):
conn = pymysql.connect(
host="127.0.0.1",
database="picture",
user="xxxx",
password="xxxx"
)
try:
with conn.cursor() as cursor:
sql = "insert into sn (route,url,info,name) values ('"+route+"','"+url+"','"+info+"','"+name+"')"
cursor.execute(sql)
conn.commit()
except Exception as e:
conn.rollback()
print("数据库操作异常:\n", e)
finally:
conn.close()
源码、数据库、爬取的图片
感谢观看!