标签:Domain gap;CP without sharing the model information;Intermediate Fusion;3D Object Detection;
论文标题:Bridging the Domain Gap for Multi-Agent Perception
发表会议/期刊:
数据集:V2XSet
问题:大多数现有的基于中间融合的协同感知算法假设所有agent都配备了相同的特征提取网络,但是为所有agent部署相同的模型是不现实的。对于互联自动驾驶,不同公司的网联自动驾驶汽车(CAV)和基础设施产品的检测模型通常是不同的;即使是同一公司的CAV,由于车载软件版本不同,目标检测模型也可能不同。而当模型不同时,传输的特征就会存在明显的domain gap(来自不同领域的特征存在差异性),将导致协同感知的性能急剧下降。
本文考虑了一个更符合实际的协同感知场景,其中合作中的每个agent可能配备了不同的特征提取模型,并分享传输具有 domain gap 的视觉特征,进行协同感知以实现基于LiDAR的3D目标检测任务。本文主要为了解决domain gap的问题,假设agent之间的相对位置是准确的,并且不存在通信延迟。
1 Domain gap 分析
首先,在同一场景下,应用Attention Transfer对两个不同的基于点云的3D目标检测网络(PointPillar和VoxelNet)获得的特征图的domain gap进行了分析,通过将两个网络获得的中间特征图的所有通道的绝对值相加,使其可视化信息更加丰富:

可观察到两个特征图在三个方面具有差异:
1)空间分辨率:不同的网络模型具有不同的体素化参数、LiDAR裁剪范围和下采样层数,所以空间分辨率是不同的;
2)channel数量:不同的网络模型的卷积层设置也不相同,因此,通道数量是不同的。
3)模式:由特征图可以看到,PointPillar和VoxelNet的模式是相反的,对于PointPillar来说,物体位置在特征图上的值相对较低,但对于VoxelNet来说,其值较高。
2 方法:MPDA
为了解决共享中间特征的三个主要差异,提出了Multi-agent Perception Domain Adaption 框架(MPDA),以弥补 domain gap。
MPDA的整体架构:
主要由四部分组成:1)可学习特征调整器,2)Sparse Cross-domain Transformer,3)域分类器,4)Multi-agent特征融合。

-
可学习特征调整器(Learnable Resizer)
1)空间分辨率:如果使用初级的调整算法(如双线性和最近插值),可能会导致严重的错位;因此,采用可学习的方式调整接收到的中间特征的大小。
2)channel数量:通过简单地丢弃 channel来调整 channel维度可能会导致重要信息的丢失;因此,所提出的调整器中还包含一个可学习的信道选择器来减少信息丢失。
特征调整器将与特征融合算法联合优化以提高目标检测性能。
-
Sparse Cross-domain Transformer
为了减少模式差异,提出了Sparse Cross-domain Transformer以有效地提取接收到的特征和自车本地的特征,并通过对抗性地欺骗domain分类器来生成 domain-invariant 的特征表示。
-
Multi-agent融合算法
利用V2X-ViT特征融合网络来融合多个agent的信息。(V2X-ViT不需要其他模型的任何关键信息,如模型类型、参数,它可以保持保密性。)
综上,MPDA中,主要提出了两个组件,即 Learnable Feature Resizer 和 Sparse Cross-domain Transformer。
2.1 Learnable Feature Resizer
将在自车本地计算获得的特征图视为源域特征
F
S
F_S
FS,从其他合作agent 处接收到的特征视为目标域特征
F
T
F_T
FT ,Feature Resizer 的目标是以可学习的方式将源域特征的尺寸大小与目标域特征对齐。Feature Resizer 将与协同检测模型进行联合训练,使其能够智能地学习获得调整特征大小的最佳方法。
Learnable Feature Resizer 结构:
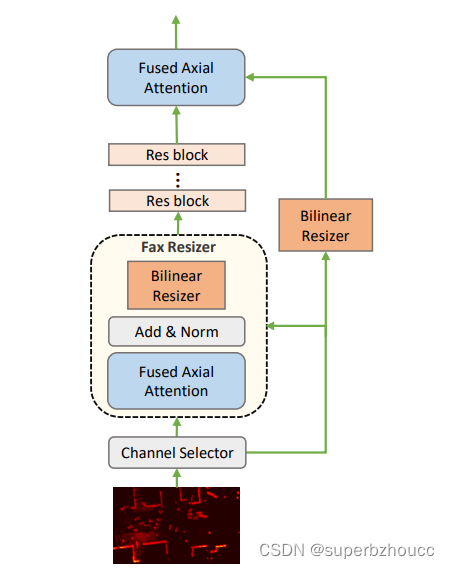
由四个主要部分组成:
1)Channel Aligner:使用一个简单的1×1卷积层来对齐通道维度,其输入通道数为
C
i
n
=
2
C
S
C_{in}=2C_S
Cin=2CS,输出通道数为
C
S
C_S
CS。
a. 当
C
T
>
C
i
n
C_T>C_{in}
CT>Cin时,随机丢弃
C
i
n
−
C
T
C_{in}-C_T
Cin−CT个通道,并应用1×1卷积层,得到一个新的特征。在
F
T
F_T
FT上重复这个过程n次,将得到具有n个通道数为
C
S
C_S
CS的特征,然后计算得到n个特征的平均。通过这种方式,来改善由于信道丢弃而造成的信息损失。
b. 当
C
T
<
C
i
n
C_T<C_{in}
CT<Cin时,用从
F
T
F_T
FT中随机选择的通道进行填充,以满足1×1卷积所需的输入通道数。
由于LiDAR点云特征通常是稀疏的,应用大核卷积来获得全局信息可能会将无意义的信息扩散到重要区域。而 FAX(Fused Axial)attention 模块 采用了局部窗口和网格注意力来有效地捕捉全局和局部的相互作用,它可以通过动态注意力机制来丢弃空体素,以消除其潜在的负面影响。
2)Fax Resizer:在bilinear resizing之前,应用FAX(Fused Axial)attention 模块来获取更好的特征表示。然后,采用一个双线性调整器(bilinear resizer),将特征图大小重塑为与源特征图相同的空间维度。(与简单的双线性插值相比,这里的 FAX Resizer 在bilinear resizing之前调整了输入特征,以避免在调整过程中出现错位和失真问题。)
3)Skip Connection:在Skip Connection中也采用了 bilinear feature resizing方法,使学习更容易。
4)残差块(Res-Block):在调整特征图的大小后,将通过多个标准的残差块以进一步细化特征图。
2.2 Sparse Cross-domain Transformer
经过大小调整后的目标域特征
F
T
′
F'_T
FT′,需要将其模式转换为Domain Classifier不可区分的模式,以获得 domain-invariant 特征。因此,需要捕获
F
T
′
F'_T
FT′和
F
S
F_S
FS之间的关联性。为此,提出了Sparse Cross-domain Transformer。
Sparse Cross-domain Transformer架构:
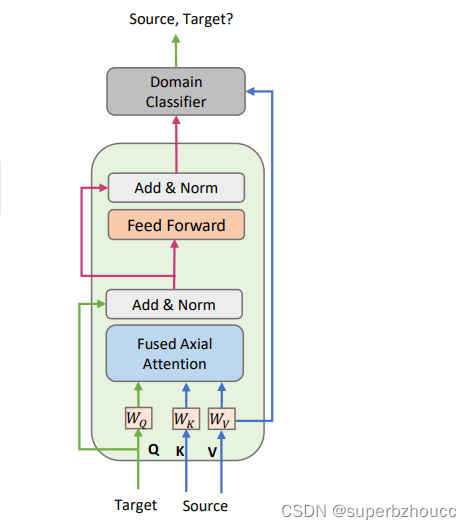
1)在
F
T
′
F'_T
FT′和
F
S
F_S
FS上应用3个不同的卷积层,分别获得query, key, 和 value。
2)来自目标域的query和来自源域的key/value 将被输入FAX Attention 块,以捕捉目标域和源域特征之间的空间交互。
3)经过一个标准的前馈神经网络,以进一步细化交互的特征。
之后,将获得的目标域特征
F
T
′
′
F''_T
FT′′和
F
S
F_S
FS进行配对组合在一起,并将其发送给Domain Classifier和Multi-agent融合模块。
2.3 Domain Classifier
采用 H-divergence 来衡量
F
T
′
′
F''_T
FT′′和
F
S
F_S
FS之间的差异。假设
X
X
X表示为可能来自源域或目标域的特征图,
h
:
X
→
0
,
1
h : X → {0, 1}
h:X→0,1表示域分类器。
在训练过程中,Domain Classifier将试图把源域样本
X
S
X_S
XS预测为0,把目标域样本
X
T
X_T
XT预测为1。假设
H
H
H是Domain Classifier的假设空间,
G
G
G是Learnable Resizer 和Sparse Cross-domain Transformer的组合,那么
G
G
G的优化目标为:
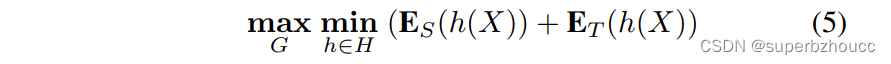
其中,
E
S
(
h
(
X
)
)
E_S(h(X))
ES(h(X))和
E
T
(
h
(
X
)
)
E_T(h(X))
ET(h(X))分别是源域和目标域的分类误差,
X
X
X由
G
G
G产生。 这种优化可以通过梯度反向层(GRL)以对抗性训练的方式实现。
2.4 Multi-agent融合
所提出的MPDA框架可以与大多数Multi-agent融合算法整合。本文选择V2X-ViT作为Multi-agent融合算法。为了达到最佳性能,除了学习愚弄Domain Classifier,
G
G
G还以直接优化检测性能为目标:
其中,M表示为Multi-agent融合算法。
E
D
(
V
)
E_D(V )
ED(V)是3D目标检测误差,
V
V
V是融合特征。
2.5 损失函数
对于3D目标检测,使用smooth L1 loss 进行边界框回归,使用 focal loss进行分类。 对于Domain Classifier,利用交叉熵损失来学习 domain-invariant 特征。最终的损失是检测和 domain adaptation损失的组合:
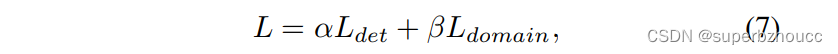
其中,α和β是[0, 1]范围内的平衡系数。
3 总结
- 在协同感知中进行domain gap识别(空间分辨率、通道数量、模式),为解决这3个主要的特征差异问题,提出了一个Multi-agent Perception Domain Adaption(MPDA)框架,可在多个维度上对特征进行调整。
- 提出了一个Learnable Feature Resizer,以自适应的方式更好地调整来自其他agent的空间和通道特征。
- 提出了一个Sparse Cross-domain Transformer,可以有效地统一来自不同agent的特征模式。
- 所提出的MPDA框架可以很容易地与其他多代理融合算法相结合,并且不需要其他agent的模型机密信息。