DBSCAN是一种非常著名的基于密度的聚类算法。其英文全称是 Density-Based Spatial Clustering of Applications with Noise,意即:一种基于密度,对噪声鲁棒的空间聚类算法。直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
DBSCAN算法具有以下特点:
- 基于密度,对远离密度核心的噪声点鲁棒
- 无需知道聚类簇的数量
- 可以发现任意形状的聚类簇
1. 基本概念
1.1. 核心思想
核心思想是基于密度。直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。

1.2. 算法参数
邻域半径R和最少点数目MinPoints。这两个算法参数实际可以刻画什么叫密集:当邻域半径R内的点的个数大于最少点数目MinPoints时,就是密集。

1.3. 3种点的类别
核心点,边界点和噪声点。邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。

1.4. 4种点的关系
密度直达,密度可达,密度相连,非密度相连。
如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度可达,那么Q到P不一定密度可达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。

2. 算法步骤
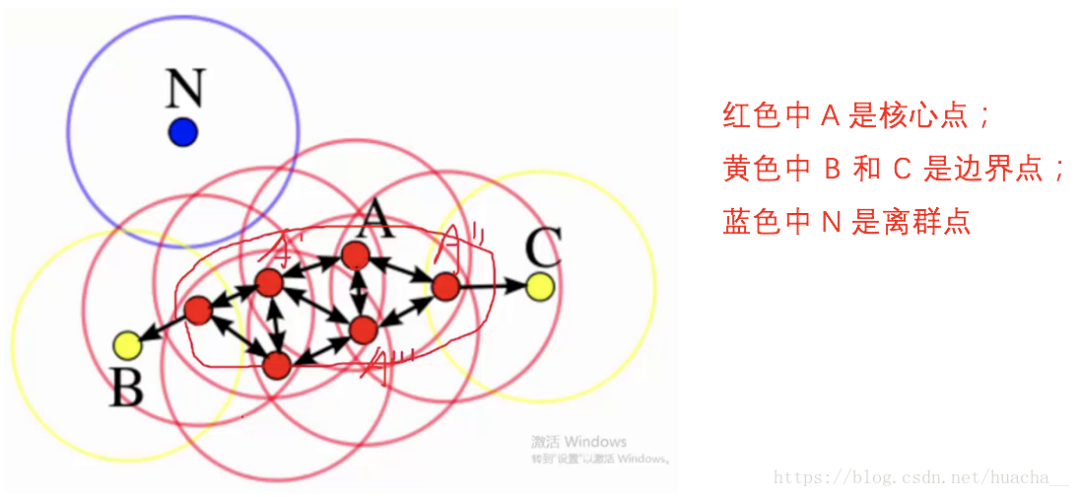
上面这些点是分布在样本空间的众多样本,现在我们的目标是把这些在样本空间中距离相近的聚成一类。
我们发现A点附近的点密度较大,红色的圆圈根据一定的规则在这里滚啊滚,最终收纳了A附近的5个点,标记为红色也就是定为同一个簇。
其它没有被收纳的根据一样的规则成簇。
形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。
等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)。
基于密度这点有什么好处呢?
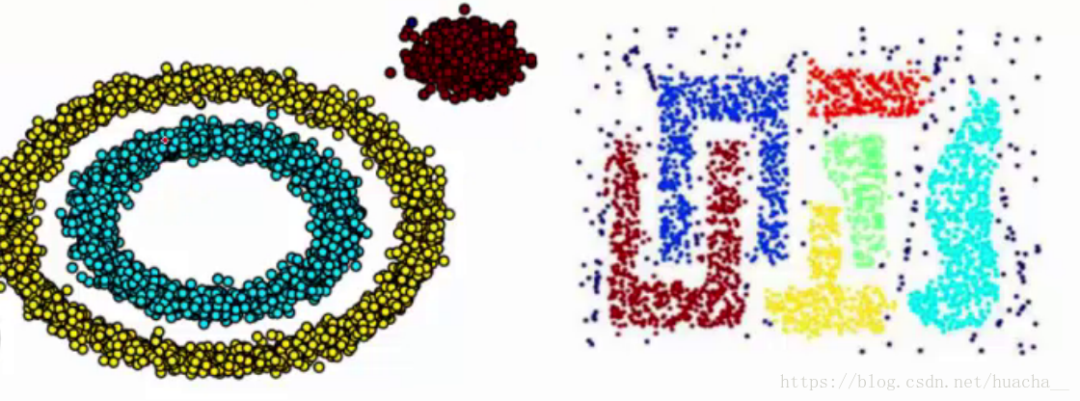
我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面两张图,环形和不规则形,这个时候,那些传统的聚类算法显然就悲剧了。
于是就思考,样本密度大的成一类呗,这就是DBSCAN聚类算法。
2.1. 寻找核心点形成临时聚类簇
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
2.2. 合并临时聚类簇得到聚类簇
对于每一个临时聚类簇,检查其中的点是否为核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。
3. DBSCAN算法迭代可视化展示
国外有一个特别有意思的网站,它可以把我们DBSCAN的迭代过程动态图画出来。

网址:Visualizing DBSCAN Clustering

设置好参数,点击GO! 就开始聚类了!
还有其他的聚类实例:
聚类1

聚类2
4. 常用评估方法:轮廓系数
这里提一下聚类算法中最常用的评估方法——轮廓系数(Silhouette Coefficient):

-
计算样本i到同簇其它样本到平均距离ai,ai越小,说明样本i越应该被聚类到该簇(将ai称为样本i到簇内不相似度);
-
计算样本i到其它某簇Cj的所有样本的平均距离bij,称为样本i与簇Cj的不相似度。定义为样本i的簇间不相似度:bi=min(bi1,bi2,...,bik2);
说明:
-
si接近1,则说明样本i聚类合理;
-
si接近-1,则说明样本i更应该分类到另外的簇;
-
若si近似为0,则说明样本i在两个簇的边界上;
5. sklearn调用范例
5.1. 生成样本点
# matplotlib inline
# config InlineBackend.figure_format = 'svg'
import numpy as np
import pandas as pd
from sklearn import datasets
X,_ = datasets.make_moons(500,noise = 0.1,random_state=1)
df = pd.DataFrame(X,columns = ['feature1','feature2'])
df.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon');

5.2. 调用dbscan方法完成聚类
# matplotlib inline
# config InlineBackend.figure_format = 'svg'
from sklearn.cluster import dbscan
# eps为邻域半径,min_samples为最少点数目
core_samples,cluster_ids = dbscan(X, eps = 0.2, min_samples=20)
# cluster_ids中-1表示对应的点为噪声点
df = pd.DataFrame(np.c_[X,cluster_ids],columns = ['feature1','feature2','cluster_id'])
df['cluster_id'] = df['cluster_id'].astype('i2')
df.plot.scatter('feature1','feature2', s = 100,
c = list(df['cluster_id']),cmap = 'rainbow',colorbar = False,
alpha = 0.6,title = 'sklearn DBSCAN cluster result');

参考文献
20分钟学会DBSCAN - 知乎
【他山之石】DBSCAN密度聚类算法(理论+图解+python代码)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)