本文转载自知乎@mywt,已获得作者授权。
文章链接:https://arxiv.org/abs/2211.14710
代码链接:
- (3DPPE on petrv1/v2) https://github.com/drilistbox/3DPPE
- (3DPPE on streampetr) https://github.com/FiveLu/stream3dppe

图1. 相机射线编码和3D点编码的示意
这里给大家分享一个我们刚中ICCV23的环视3D检测论文,3DPPE: 3D Point Positional Encoding for Multi-Camera 3D Object Detection Transformers。方法比较简洁,针对环视3D目标检测问题,基于优秀的PETR框架(说实话,petr以及streampetr是真好),分析了现有3D目标检测中位置编码的诸多区别,提出了一种新的3D点编码(图1.b),解决了之前射线编码(图1.a)缺乏细粒位置先验的问题,统一了图像特征和query的位置表征,在环视3D检测上实现了卓越性能。在最先进的petr v1/v2以及streampetr上都得到了提升,我们罗列了在经典的v2-99主干+800x320的分辨率下的效果(这个配置里的主干网在深度数据集上预训练过、并且小分辨率对训练的要求降低从而更亲民,适合做消融实验对比性能),具体提升效果如下。

图2. 在petrv1上

图3. 在petrv2上

图4. 在streampetr上
1. 方法简介
第一次看到PETR的时候,感叹作者的认知面的广泛,可以把类似于NERF中的思路迁移过来做3D检测,通过给每个单目2D图像特征赋予一个独立的含有3D信息的位置编码(如图1.a),实现在3D空间中交互索引2D图像特征。但是PETR中含有3D信息的位置编码的机理是什么,含有的3D信息又是啥,一开始还不是很确定,于是我们设计了一系列的实验,来探索3D目标检测中图像特征不同位置编码的影响。
1.1 位置编码的初步探索
这一小节我们想分析camera-ray PE、Lidar-ray PE、Oracle 3D Point PE的联系与区别,他们的简单示意如下图所示。

图5. 环视3D检测中常用的位置编码的卡通示意
(1) camera-ray编码
由于PETR中图像编码的构建用到了内外参,隐约的感觉到像是表征了雷达坐标系下,从相机光心到成像平面上不同像素点的射线信息。于是我们设计了如下的实验来证明PETR的位置编码就是相机射线编码。首先我们将PETR中图像位置编码的构建要素分解成3部分:1.深度bin的个数 �� ;2. 深度离散化的方式 �� ;3. 深度表示范围 �� 。具体实验结果如下表所示,可以看表1中的第2-4行,修改深度离散化的方式,检测效果变化不是很大,说明深度离散化方式对性能影响不大;再看表1中的第4-6行,修改深度感知范围,检测效果变化很小,说明深度感知范围对性能影响不大;在看表1中的最后2行,修改深度bin的个数,检测效果变化很小,说明深度bin的个数对性能影响不大。综上,我们可以感觉到,当这些深度点在相机射线(从光心->成像平面上的像素点)上滑动时,即便采样方式、采样点以及深度感知范围变化,模型的检测效果几乎不变。所以只要能图像位置编码能表针出相机射线信息,那么模型性能和原始的PETR相比几乎不变。因此,PETR的位置编码就是camera-ray编码(相机射线编码),并且我们还发现了最简练的3D camera-ray编码,只要2个在相机射线上的点,就可以表征出对应于PETR中等价的3D位置编码。

表1. 深度bin的个数、深度离散化的方式、深度表示范围对性能的影响
上面分析了camera-ray编码最低编码点数为2,如果点数降为1呢?这是个很有意思的事情,点数降为1时,能决定编码信息的因素就只剩下这个点的深度值怎么取,其实有2种取法:
- 不正确的深度值(我们将其称为LiDAR-ray);
- 准确的深度值(我们将其称为Oracle 3D Point);
(2) LiDAR-ray
为啥叫LiDAR-ray等这一小节分析结束后就知道了。我们将用数学建模以及实验证明了这一点。但为了方便理解,我们首先做两个铺垫知识准备:
1. 先定义LiDAR-ray,每个像素点对应的位置编码由1个点构建,且该点对应的深度值与物体实际深度无关。(其实我们猜测还有一个点是lidar坐标系的原点,但是由于是默认值,并且在构建位置编码时没有显式的用到,网络应该是学习到了雷达坐标系的原点(0,0,0))

图6. 相机射线编码和雷达射线编码的几何关系
2. 再先铺垫一个简单数学几何信息。如图6所示,我们构建了相机射线编码和雷达射线编码的几何关系。相应的,我们用余弦距离的差异来定义camera-ray和lidar-ray的差异:

公式1. camera-ray和lidar-ray的差异
可以看出,只要d越大,也就是雷达坐标系下的3D点离相机或者雷达越远,那相机射线编码和雷达射线编码就是等价的。
好了,基础知识构建结束。我们现在开始做实验,如表2所示,我们将深度值d依次取为0.2m/1m/15m/30m/60m,我们发现,d为0.2m或者1m时性能相比表1中的结果掉点较多;但是当d为15m/30m/60m时,检测性能与表1中的结果持平。

表2. LiDAR-ray下d值变化对性能的影响
从上面的实验现象,可以总结出:深度值d较小时性能较差、深度值较大时LiDAR-ray与Camera-ray性能持平。而且这个现象也与上面公式1的结论一致。所以大家知道为啥加Lidar-ray了吧,因为这个实验现象与我们前面数学建模的从雷达出发的射线的结论一致。并且与“camera-ray的性能不受深度值影响”的现象不同,Lidar-ray中的深度值d较小时性能较差、深度值较大时LiDAR-ray与Camera-ray性能持平。
(3) Oracle 3D Point
和lidar-ray不同,Oracle 3D Point中的深度是通过把点云投射到成像平面上得到的,这样图像特征的每个点都可以得到精确的位置编码信息(由于点云的稀释性,许多像素点其实是没有得到投射后的深度信息的,这些像素点的特征就没有参与训练以及inference)。从表3可以看出,相比于之前的编码方式,这会NDS以及mAP得到了巨大的提升(6.7% NDS, 10.9% mAP, and 18.7% mATE)。由此可以说明,相比较于camera-ray以及lidar-ray中不精确的3D位置先验,拥有准确3D位置先验的位置编码才是3D检测性能提升的关键。

表3. 不同位置编码对检测性能能力的影响
但是camera-based感知方案中,没有准确的深度信息,因此我们用了个简单的方法,通过单目深度估计来得到深度信息,具体可以参考下一节。
1.2 模型结构
我们所提方法的框架图如下图所示,由主干网、3D点生成器、3D点编码模块以及decoder构成。主干网以及decoder和之前的petr一样。我们着重说明下3D点生成器以及3D点编码模块这两部分。

图7. 框架图
1. 3D点生成器
3D点生成器包含深度预测头以及2D到3D的坐标转换模块。
深度预测头模型结构如下图所示,输入图像特征和相机参数,输出的深度值 ����� 为直接回归深度 �� +期望深度 �� 的加权和。

图8. 深度检测头
对应的深度值 �����为:
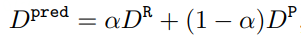
其中 � 是可学习的混合系数。在构建训练用的深度GT的时候,我们直接将点云投射到成像平面上,并得到一个对应的mask来指示哪些像素有深度GT、哪些没有,loss监督的时候只有有点云投射到的地方才有贡献。深度监督loss由smooth l1以及distribution focal loss(检测中用于修正bbox的loss,迁移至深度监督上发现效果也很好)构成:

2D到3D的坐标转换模块:得到深度估计后,利用相机内外参,可以将2.5D信息转换为3D信息。然后利用感知范围对齐归一化。

2. 3D点编码模块
这里和PETR里用的一样的正余弦编码:

区别在于之前PETR是沿着相机射线方法的64个点,我们现在是1个点。

图9. 相机射线编码和3D点编码的比较
并且在3D点编码的范式下,图像特征的位置编码和锚点的位置编码得到了统一,大家可以共享同一个编码器。
2 实验结果
2.1 和sota方法的比对
我们的方法在nus的验证集以及测试集上都取得了不错的结果。

表4. 在nus的验证集上

表5. 在nus的测试集上
2.2 深度估计质量对性能的影响
实验表明smooth-l1和dfl一起用效果最好。

表6. 深度估计损失函数对检测性能的影响
2.2 和其他3D position-aware Feature性能的对比
其实3D position-aware Feature是指可能含有3D位置信息的特征,而其中的位置编码可以分为Ray-aware以及Point-aware。其中Ray-aware又可分为camera-ray(PETR中的位置编码)以及Feature-guided(PETRv2中的位置编码),Point-aware可以分为topk-aware(按深度估计概率取置信度最高的k个bin)、Depth Feature-guided(PETRv2的位置编码中引入深度监督)、Depth-guided 3D point(我们提出的3D点编码)。上述5个编码的对比效果如下表所示:

表7. 不同3D position-aware Feature的性能对比
2.3 统一图像特征以及锚点的位置编码表征的好处
由于锚点也是3D点编码,实现形式上和我们提出的用于图像特征的3D点编码一致,都来自3D坐标空间,又都要隐射到高维编码空间进行交互。所以直观感觉是如果这个映射过程是一致的,那边编码表征空间同样一致,这样会更有利于query和图像特征的交互。于是我们对比了3D点编码器是否共享带来的性能差异,实验表明共享3D点编码器效果是最好的。

表8. 3D点编码生成器是否共享的性能差异
2.4 位置编码相似度分析
好的位置编码应该有更强的聚焦,也就是距离越近相似度越高,如果能语义越近相似度越高那更好。我们可视化了不同像素点之间位置编码的相似性,通过在前景、图像边缘以及背景上采点,可以看出,我们的3D点编码的相似度更好,更聚焦。

图10. 前景区域采点示意

图11. 跨图像目标采点示意

图12. 背景区域采点示意
3. 还有哪些坑可以去填
3.1 如何获得更好的3D位置信息
- 单目深度估计 -> 时序多帧+环视多目的Stereo depth
- 一定要有显式的深度估计或者监督吗?我们这个方法应该是第1个在PETR系列上引入深度估计的工作。但是要得到3D位置先验,到不一定要有显式的深度估计或者监督。抛开显示的深度估计或者抛开显示的深度监督,利用occ预训练或者nerf重建,来隐式的学习深度信息或者根号的几何结构信息。
- 利用知识蒸馏得到更好的深度估计。这个在我们论文中的未来改进中有所提及。

表6. Reusing the ground-truth depth for knowledge distillation.
3.2 扩展到Occ预测上
射线编码本身和Nerf就很相似,然后3D点编码的深度位置先验,一下子就找到了物体可能出现的位置,与nerf重建的思路很相似。
3.3 新的位置编码的探索
其实到目前为止,基于transformer范式的3D目标检测的编码范式探索的很少,即便是我们所提的3D点编码,其实也就等价于detr-based的2D检测器中的最原始的位置编码从图像像素层面升级到3D坐标层面。detr-based的2D检测器中许多位置编码设计的理念都可以结合3D任务的特性进行启发性的改进或创新。
3.4 内外参的泛化
现有绝大多数环视3D检测模型,内外参编码的话,模型都需要重训。除了特斯拉aiday提出的虚拟相机相关技术以及百度apollo ai day推出的内外参解耦,可以一定程度解决上面内外参变化模型就需要重训的问题。我们论文中提及的lidar-ray似乎也可以解决上述问题,不过这仅仅是灵光一现,还需要实验验证。
3.5 Nus上刷榜
现在不考虑未来帧,以vit-large为主干的streampetr的性能应该是最好的,但是这里的vit-large的模型结构应该做了微调,所以需要投入一定的时间去做这里的复现,感兴趣的小伙伴可以去尝试一下。
4. 写在最后:我们还在招聘实习生
公司简介:后摩智能,刚刚推出国内首款量产存算一体智驾芯片,最高物理算力256TOPS,典型功耗35W。
职位描述:
- 参与自动驾驶感知任务(不限于单目、环视、bev下的3D障碍物感知、3D车道线感知、局部建图、轨迹预测等)在端上芯片的适配,包括各个任务链条下的"数据建设-模型轻量化设计-量化及部署"全流程,目标是在无人小车上光滑实现相关感知模块功能。
- 参与chatgpt大模型以及多模态感知任务在垂直业务场景(工业异常检测、数据自动标注等)下的落地开发(优先南京)。
- 参与其他AI业务场景下的业务落地开发。
- 在完成业务工作的基础上,适时探索前沿技术并发表论文。
职位要求:
- 了解自驾场景需求,有相关2D/3D感知任务的基本认知。
- 了解常用多模态开放场景检测方法。
- 熟悉python/pytorch/C++等常用计算机语言,熟悉mmlab。
- (加分项)有相关项目经验,有cuda算子开发及加速优化经历,有完整的端上模型部署经历者优先。
- (加分项)有计算机视觉相关的顶会论文经验者优先。
- 工作地点:上海、南京、北京,211研究生以上学历,每周可实习4天以上。
薪资待遇:250元/天+餐补30元/天,9点后可打车报销
投递方式: 邮箱: changyong.shu89@gmail.com, 或者加我微信: drilistbox
希望有兴趣的同学一起参与进来,在这里你将从算法和工程两个维度上扩展个人的技能栈,发光发热。