一、数据集简介
- 本文用到的数据集是以上海一卡通乘客刷卡数据为背景,利用
Python对数据进行预处理,以Tableau对数据进行可视化。
- 数据集共包含
15772842个样本,每个样本包含7个属性,每个属性之间均已逗号分隔。
| 属性 |
定义 |
| 刷卡人 |
用户标识符 |
| 刷卡日期 |
一卡通刷卡日期 |
| 刷卡时间 |
一卡通刷卡时间 |
| 公共交通信息 |
公交线路、轨道交通线路、出租及轮渡信息 |
| 交通方式 |
公交、地铁、出租、轮渡、P+R停车场 |
| 价格 |
公共交通价格 |
| 是否优惠 |
商业一卡通交易是否有优势 |
二、数据预处理
- 导包pandas
import pandas as pd
- 读取csv文件
raw = pd.read_csv(F:/python/data_analysis/SPTCC-20160701.csv", \
names=['刷卡人', '刷卡日期', '刷卡时间', '公共交通信息','交通方式', '价格', '是否优惠'], \
encoding='GB2312')
print(raw.head())
## 刷卡人 刷卡日期 刷卡时间 公共交通信息 交通方式 价格 是否优惠
## 0 2104309791 2016-07-01 12:04:46 8号线市光路 地铁 0.0 非优惠
## 1 2104309791 2016-07-01 12:54:44 4号线鲁班路 地铁 5.0 非优惠
## 2 3102664781 2016-07-01 18:42:45 11号线枫桥路 地铁 4.0 非优惠
## 3 3102664781 2016-07-01 08:04:23 11号线枫桥路 地铁 0.0 非优惠
## 4 3102664781 2016-07-01 08:37:04 9号线漕河泾开发区 地铁 4.0 非优惠
print(raw.shape)
## (15772842, 7)
- 仅保留交通方式为“地铁”的数据记录
metro = raw.loc[raw['交通方式']=='地铁'].drop(columns=['交通方式', '是否优惠'])
print(metro.shape)
## (10308569, 5)
- 从字段“公共信息交通”中提取“轨道交通线路”以及“地铁站”信息
-
apply()函数用于当函数参数已经于一个元组或字典中时存在,直接地调用函数。apply()的返回值就是func()的返回值;
- 调用函数
split(),将标签字符串进行切割,并根据索引返回标签切割后的值;
metro['轨道交通路线'] = metro['公共交通信息'].apply(lambda x: (x.split('号线')[0]))
metro['地铁站'] = metro['公共交通信息'].apply(lambda x: x.split('号线')[1])
- 调用函数
drop(),删除无需进一步分析的维度字段,其中inplace=True修改作用于原数据集。
metro.drop(columns=['公共交通信息'], inplace=True)
- 读取上海地铁站经纬度信息数据
metro_geo = pd.read_csv('F:/data/metro/SH_metro.csv', encoding='utf-8')
metro_geo['轨道交通线路'] = metro_geo['轨道交通'].apply(lambda x: x.split('号')[0])
metro_group_dedup = metro_geo.drop_duplicates(['轨道交通线路', '地铁站'])
data = pd.merge(metro, metro_geo_dedup, how='left', \
left_on=['轨道交通线路', '地铁站'], right_on=['轨道交通线路', '地铁站'])
print(data.head())
## 刷卡人 刷卡日期 刷卡时间 ... 地铁站序列 经度 纬度
## 0 2104309791 2016-07-01 12:04:46 ... 30.0 121.538527 31.328516
## 1 2104309791 2016-07-01 12:54:44 ... 6.0 121.480988 31.204940
## 2 3102664781 2016-07-01 18:42:45 ... 19.0 121.417540 31.248068
## 3 3102664781 2016-07-01 08:04:23 ... 19.0 121.417540 31.248068
## 4 3102664781 2016-07-01 08:37:04 ... 13.0 121.404164 31.176220
##
## [5 rows x 11 columns]
- 提取刷卡整点小时信息,增大数据颗粒度
data['刷卡时间_时'] = data['刷卡时间'].apply(lambda x: x[:2] + ':00:00' if int(x[:2]) <= 24 and int(x[:2]) >= 0 else '')
data['进/出站'] = data['价格'].apply(lambda x: '进站' if x == 0 else '出站')
- 调用函数
drop(),删除无需进一步分析的维度字段,其中inplace=True修改作用于原数据集
data.drop(columns=['刷卡时间', '价格'], inplace=True)
print(data.head())
## 刷卡人 刷卡日期 轨道交通线路 ... 纬度 刷卡时间_时 进/出站
## 0 2104309791 2016-07-01 8 ... 31.328516 12:00:00 进站
## 1 2104309791 2016-07-01 4 ... 31.204940 12:00:00 出站
## 2 3102664781 2016-07-01 11 ... 31.248068 18:00:00 出站
## 3 3102664781 2016-07-01 11 ... 31.248068 08:00:00 进站
## 4 3102664781 2016-07-01 9 ... 31.176220 08:00:00 出站
##
## [5 rows x 11 columns]
- 导包numpy
import numpy as np
- 数据多维度汇总
dims = ['刷卡日期','刷卡时间_时','轨道交通','轨道交通线路',
'地铁站','地铁站序列','经度','纬度','进/出站']
//统计进站人数
get_in_cnt = lambda x: x.loc[x=='进站'].count()
get_in_cnt.__name__ = "inCnt"
//统计出站人数
get_out_cnt = lambda x: x.loc[x=='出站'].count()
get_out_cnt.__name__ = "outCnt"
smry = data.groupby(dims).agg({'刷卡人': [np.size, pd.Series.nunique],
'进/出站': [get_in_cnt, get_out_cnt]})
print(smry.head())
## 刷卡人 进/出站
## size nunique inCnt outCnt
## 刷卡日期 刷卡时间_时 轨道交通 轨道交通线路 地铁站 地铁站序列 经度 纬度 进/出站
## 2016-07-01 00:00:00 11号主线 11 嘉定北 31.0 121.244010 31.397409 出站 2 2 0 2
## 11号支线 11 安亭 32.0 121.168602 31.294335 出站 21 21 0 21
## 1号线 1 人民广场 16.0 121.481022 31.238795 出站 5 5 0 5
## 2号线 2 龙阳路 12.0 121.564050 31.209166 出站 30 30 0 30
## 4号线 4 世纪大道 12.0 121.533437 31.234854 出站 55 55 0 55
- 筛选后,输出一个包含多级索引的数据框
smry,通过函数ravel()可以进行降维,并调用reset_index()将数据从索引中释放出来,确保能够正常输出。
smry.columns = ["_".join(x) for x in smry.columns.ravel]
smry.reset_index(inplace=True)
print(smry.head())
## 刷卡日期 刷卡时间_时 ... 进/出站_inCnt 进/出站_outCnt
## 0 2016-07-01 00:00:00 ... 0 2
## 1 2016-07-01 00:00:00 ... 0 21
## 2 2016-07-01 00:00:00 ... 0 5
## 3 2016-07-01 00:00:00 ... 0 30
## 4 2016-07-01 00:00:00 ... 0 55
##
## [5 rows x 13 columns]
- 调用数据框函数
rename()对聚合后的形状重命名
smry.rename(columns={'刷卡人_size': '客流量', '刷卡人_nunique': '客流量(计数不同)',
'进/出站_inCnt': '进站客流量', '进/出站_outCnt':'出站客流量'},
inplace=True)
print(smry.head())
## 刷卡日期 刷卡时间_时 轨道交通 轨道交通线路 ... 客流量 客流量(计数不同) 进站客流量 出站客流量
## 0 2016-07-01 00:00:00 11号主线 11 ... 2 2 0 2
## 1 2016-07-01 00:00:00 11号支线 11 ... 21 21 0 21
## 2 2016-07-01 00:00:00 1号线 1 ... 5 5 0 5
## 3 2016-07-01 00:00:00 2号线 2 ... 30 30 0 30
## 4 2016-07-01 00:00:00 4号线 4 ... 55 55 0 55
##
## [5 rows x 13 columns]
- 信息扩展
- 为了提高数据可视化效果,我们将地铁站经纬度信息进行扩展,将其与时间信息进行交叉连接,构成一条轨道交通图所必须的空数据集;假空数据集与上述聚合后的一卡通卡数据进行,使其在地图上可见的中轨道交通线路能够一直存在,而不会导致轨道交通的残缺。
distinct_time = pd.DataFrame({'刷卡时间_时':smry['刷卡时间_时'].unique(),
'cross_join': 1})
metro_geo['cross_join'] = 1
metro_map = pd.merge(metro_geo, distinct_time, on='cross_join').drop('cross_join', axis=1)
result = pd.concat([smry, metro_map], sort=True)
print(result.head())
## 出站客流量 刷卡日期 刷卡时间_时 地铁站 ... 轨道交通 轨道交通线路 进/出站 进站客流量
## 0 2.0 2016-07-01 00:00:00 嘉定北 ... 11号主线 11 出站 0.0
## 1 21.0 2016-07-01 00:00:00 安亭 ... 11号支线 11 出站 0.0
## 2 5.0 2016-07-01 00:00:00 人民广场 ... 1号线 1 出站 0.0
## 3 30.0 2016-07-01 00:00:00 龙阳路 ... 2号线 2 出站 0.0
## 4 55.0 2016-07-01 00:00:00 世纪大道 ... 4号线 4 出站 0.0
##
## [5 rows x 14 columns]
- 调用
fillna()函数对拼接后缺失的数据进行补齐,参数inplace=True表示修改作用于原数据集
na_values = {'出站客流量': 0, '刷卡日期': '1901-01-01', '城市': '上海市',
'刷卡时间_时': '00:00:00', '客流量': 0, '客流量(计数不同)': 0,
'进站客流量': 0, '进/出站': ''}
result.fillna(value=na_values, inplace=True)
print(result.head())
## 出站客流量 刷卡日期 刷卡时间_时 地铁站 ... 轨道交通 轨道交通线路 进/出站 进站客流量
## 0 2.0 2016-07-01 00:00:00 嘉定北 ... 11号主线 11 出站 0.0
## 1 21.0 2016-07-01 00:00:00 安亭 ... 11号支线 11 出站 0.0
## 2 5.0 2016-07-01 00:00:00 人民广场 ... 1号线 1 出站 0.0
## 3 30.0 2016-07-01 00:00:00 龙阳路 ... 2号线 2 出站 0.0
## 4 55.0 2016-07-01 00:00:00 世纪大道 ... 4号线 4 出站 0.0
##
## [5 rows x 14 columns]
result.to_csv('F:/data/metro/output.csv', index=0, encoding='utf-8_sig', sep='|')
三、数据可视化
使用Tableau对数据进行可视化处理
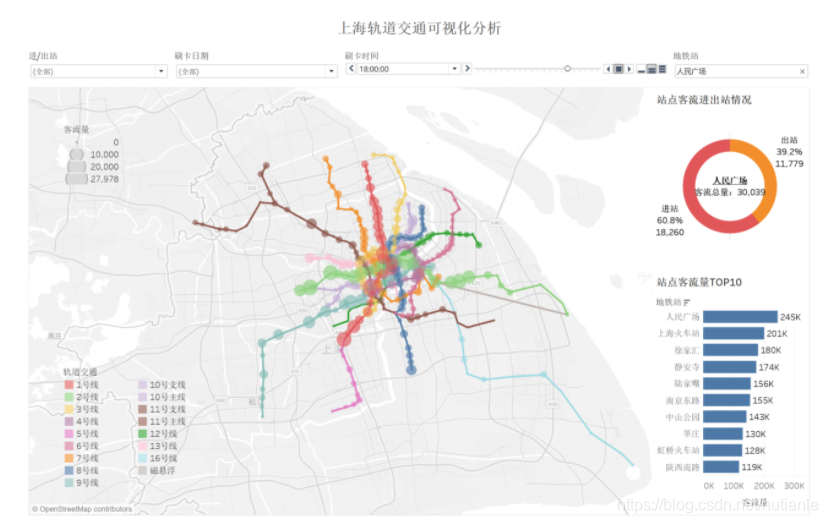
通过该仪表板,可以清楚地了解到上海轨道交通各站点客流量情况;单击滑动条右侧的小三角还可进行每小时客流情况的动态演示。