
©作者 | 吉雅太
单位 | 清华大学
研究方向 | 多模态研究
自从 2018 年 BERT 在 NLP 领域声名鹊起,通过预训练在 n 多 NLP 任务中刷榜,成功发掘出了 transformer 的潜力,众多研究者就看到了多模态发展的新的机会——使用大量数据做预训练。
因为从 updn 模型开始,多模态这面普遍把图片提取成区域特征序列做后续处理,这样的话多模态是视觉和文本特征序列,NLP 中是文本特征序列,没什么本质差异,自然可以把预训练搬过来,一系列多模态 transformer 预训练的文章应运而生。
举个栗子:LXMERT、VLBERT、ViLBERT、UNITER、UNIMO、OSCAR、VisualBert、VLP、今年的 ViLT、VinVL、SOHO、SimVLM、METER 等等,以及没有使用预训练也达到很好效果的 MCAN。
按结构主要可以分为单流、双流,单流就是把不同模态特征序列先拼起来,通过 transformer 进行自注意力,双流就是先各个模态特征单独自注意力,再经过 transformer 交叉注意力。模型都是大同小异,或者预训练方法有些小的差别,最主要的趋势是预训练数据越来越大。
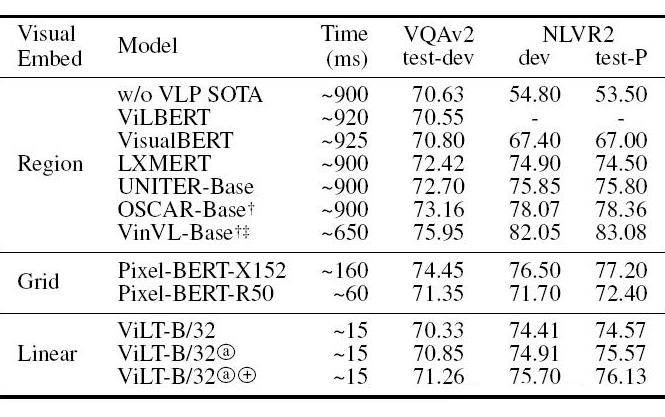
几个模型的预训练数据规模:
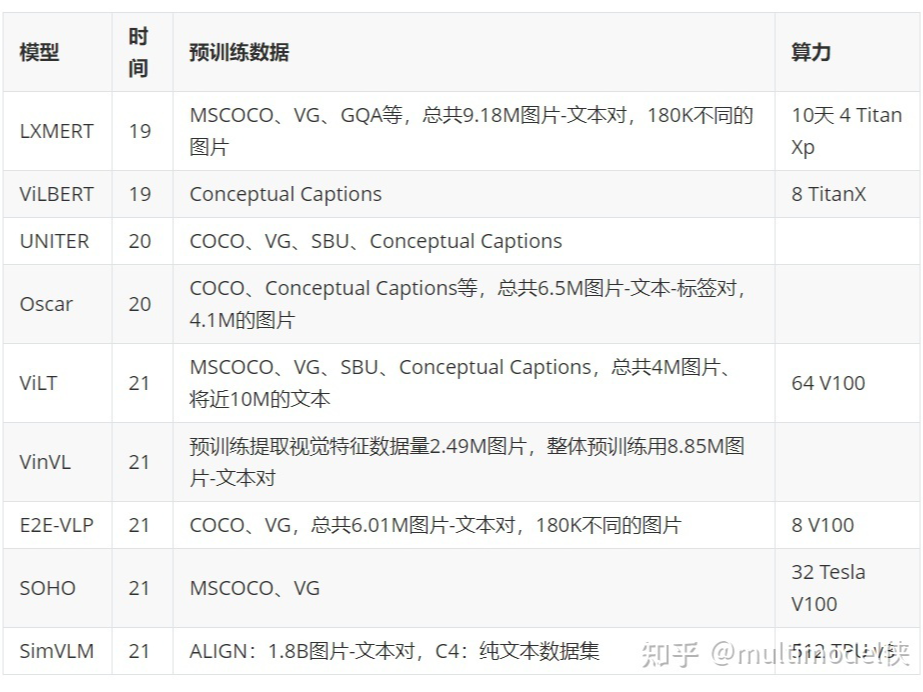

LXMERT
论文标题:
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
论文地址:
https://arxiv.org/abs/1908.07490
视觉特征使用 faster rcnn 提取区域化特征,文本提取 word-level 特征。预训练使用了五个:Language Task: Masked Cross-Modality LM;Vision Task: RoI-Feature Regression;Vision Task: Detected-Label Classification;Cross-Modality Matching;Image Question Answering (QA)。
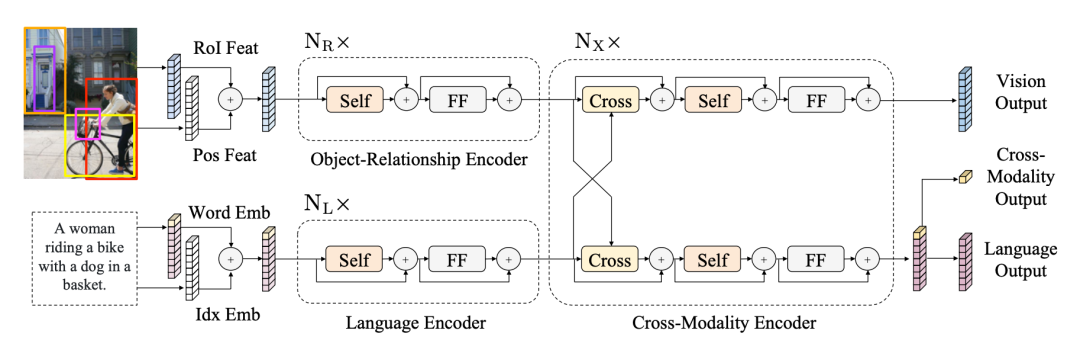
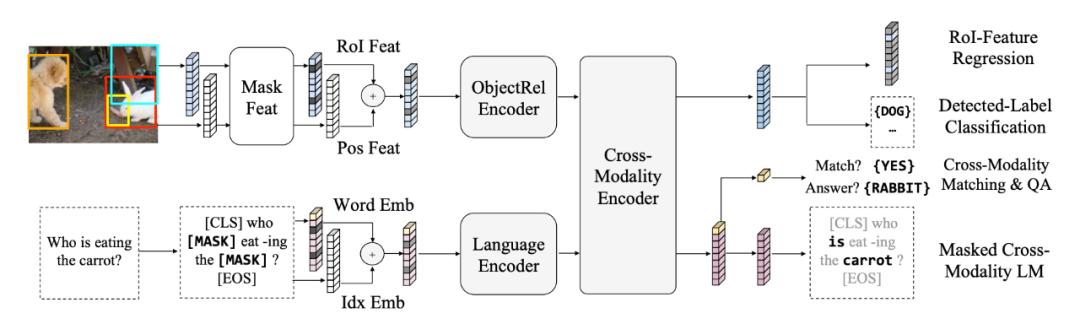

ViLBERT
论文标题:
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
论文地址:
https://arxiv.org/abs/1908.02265
结构基本和 LXMERT 一样,差别有以下几点:预训练时 vilbert 对 masked region 的预测是一个 object label 的概率分布,让它去接近区域特征提取器、即目标检测模型对该区域的预测 label 分布,损失为两个分布的 KL 散度;预测答案时输出头不同,vilbert 用 [IMG]、[CLS] 表征向量相乘后接分类器。

UNITER
论文标题:
UNITER: UNiversal Image-TExt Representation Learning
论文地址:
https://arxiv.org/abs/1909.11740
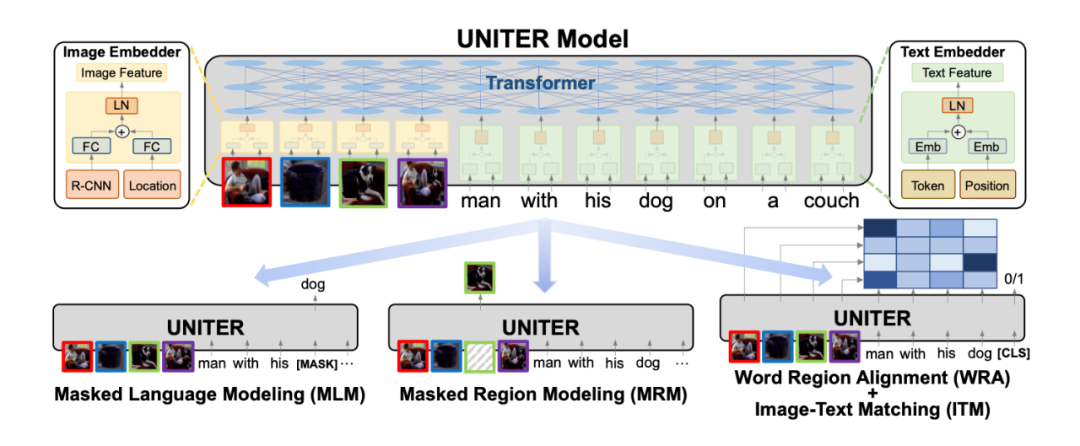
结构和其他的一样,预训练任务采用了四个:MLM;MRM,把某区域特征换为全 0,然后去恢复它,mlm 和 mrm 不同时进行,mrm 分为三类,一个是回归特征向量,一个是分类任务,GT 是目标检测预测的 label,再一个是最小化预测的分类分数向量和目标检测预测的分数向量之间的 KL 散度;ITM,图文匹配;
WRA,为了提供视觉区域和文本单词更细粒度的对齐,通过使用 Optimal Transport,有效地计算从图片特征转换到文本特征的最小代价,这里没太看懂,大概就是 OT 可以学出一个矩阵 T,表示第 i 个区域、第 j 个文本是否是对应的,损失就是 ,这里的 c 是余弦距离。预训练策略是对每个 batch 随机采样一个任务来训练。

Oscar
论文标题:
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
论文地址:
https://arxiv.org/abs/2004.06165
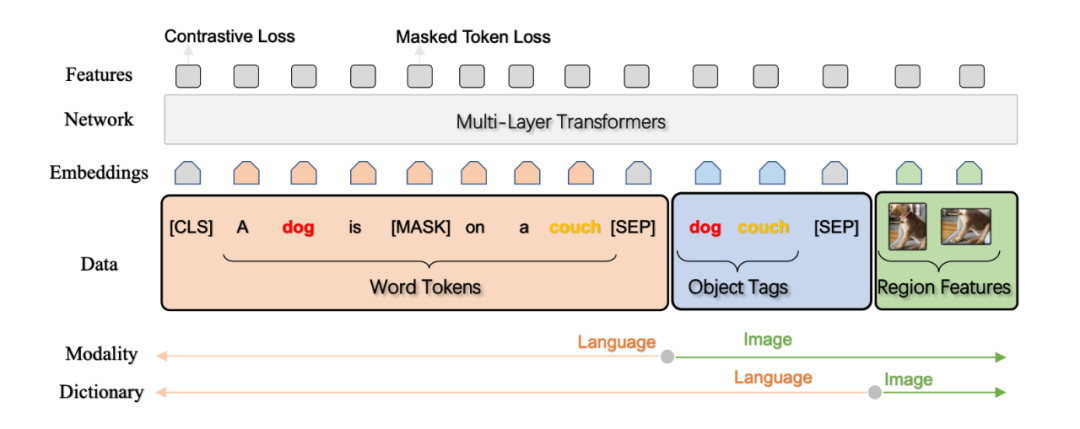
本文预训练使用的数据是 图片-文本-检测到的 object 标签 三元组,相当于用物体标签做图片和文本的锚点,减小两种模态之间的 gap,因为标签一方面和图片的某区域对应,另一方面它又是文本内容。
两个预训练任务:A Dictionary View:Masked Token Loss,即恢复被 mask 掉的文本 token,可能在句子里,也可能是 tags;A Modality View: Contrastive Loss,把 tags 序列以 50% 概率换掉,然后在输出进行二分类,判断此时的三元组是正确的还是被污染的。

SOHO
论文标题:
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
论文地址:
https://arxiv.org/abs/2104.03135
作者团队来自北京科技大学、Beijing Engineering Research Center of Industrial Spectrum Imaging、MSRA。本文提出模型 SOHO(see out of the box),用整张图片作为输入,用端到端的方式学习视觉语言表征,即无需提取区域化特征,所以叫做 out of the(bounding)box。由于不需做目标检测,推理速度快了十倍。
SOHO 通过便于跨模态理解的视觉字典(VD)提取全面而紧凑的图像特征。本文使用一个叫做 MVM(masked visual modeling)的预训练,会利用到 VD,其他预训练有 MLM、ITM(图文匹配)。但其实使用网格特征很多之前的工作都已经在用了。
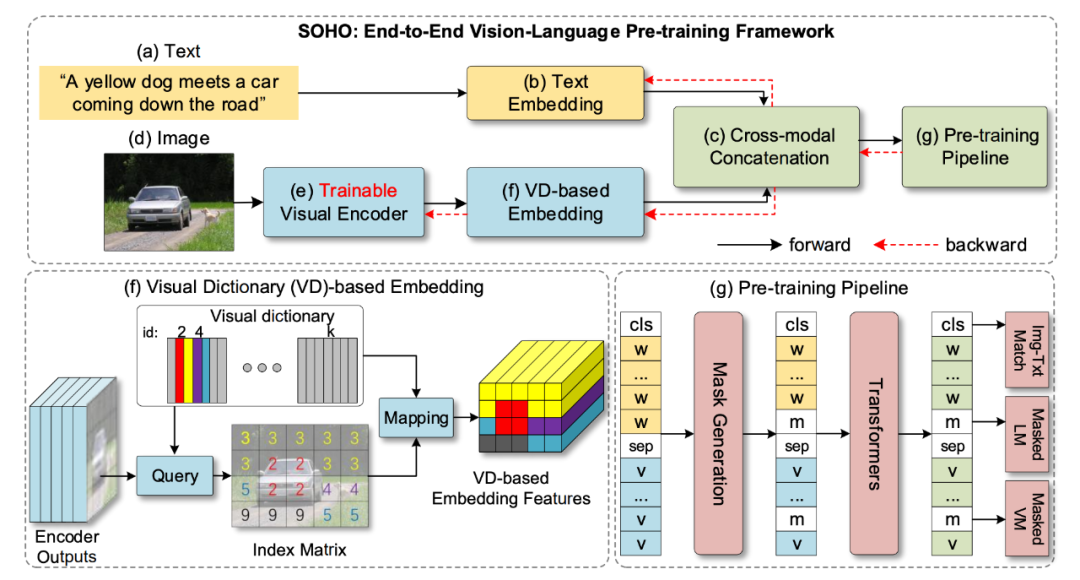
很常见的结构,比较新的是 visual dictionary 的提出,它的 motivation 是 CNN 提取出的图片的网格化特征并没有一个明确的含义(不像区域化特征对应了 object),VD 目的是弥补网格特征和语言 token 之间的 gap,比较巧妙,最终实现的目的是让属于同一类 object 的网格特征具有更高的语义相似性。
VD 是一个二维矩阵,由 k 个特征 d 组成,对于某一个视觉特征 v,计算最相似的 d(二范数距离最小),(然后用这个 d 替代 v,但我觉得这样的话会丧失一个物体的不同网格之间的特异性)。VD 的更新:先随机初始化,然后用移动平均法更新:
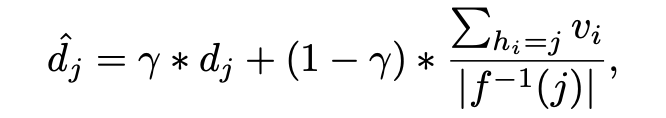
没太看懂它的公式,总之思路就是视觉字典中的特征 d 应该向目前输入的特征 v 学习,就是找到和 v 最相似的存储的特征后,再用 v 更新这个存储的特征,使得存储的特征越来越趋向于表征某一类物体。
预训练用了 masked language modeling、image-text matching,以及 masked visual modeing,MVM 是随机 mask 掉某个物体的所有网格,然后预测这些网格属于的类别(这里的类别指的是在 VD 中,每一个存储的特征给一个编号)。
实验在一些下游任务上都取得了较可观的效果。

ViLT
论文标题:
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
论文地址:
https://arxiv.org/abs/2102.03334
本文 motivation 在于视觉特征不管用目标检测得到的区域特征,还是卷积得到网格化特征,都是很耗时的。
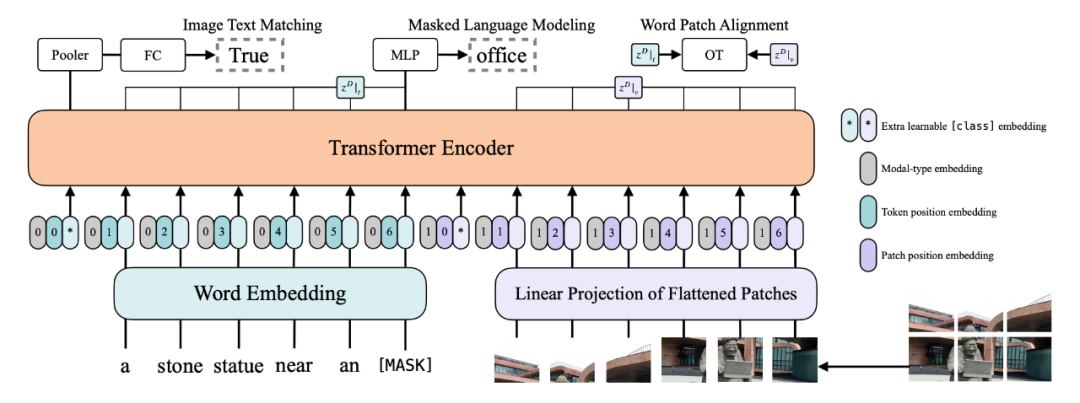
ViLT 提取图片特征的方法模仿 ViT,对每个 patch 做一个 linear projection,参数量骤降,具体做法就是把每个 patch( )展成一维,再映射到隐状态维度。模型初始化使用 ViT 的权重,结构也和 vit 相同(结构上与 bert 唯一的不同在于 LN 层的位置)。
预训练的方法有:image text matching(ITM)and masked language modeling(MLM)。另外使用了一种 word patch alignment(WPA)的方法计算文本子集和视觉子集的对齐分数(仿照 uniter)。
引入 WholeWord Masking 的方法,因为分词时有时会把一个词分开,这种方法是把属于一个词的所有分词都 mask 掉。使用 Image Augmentation 增强模型泛化性,在微调时,他们使用 RandAugment 里的所有方法,除了两个:颜色转换和裁剪。

SimVLM
论文标题:
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
论文地址:
https://arxiv.org/abs/2108.10904
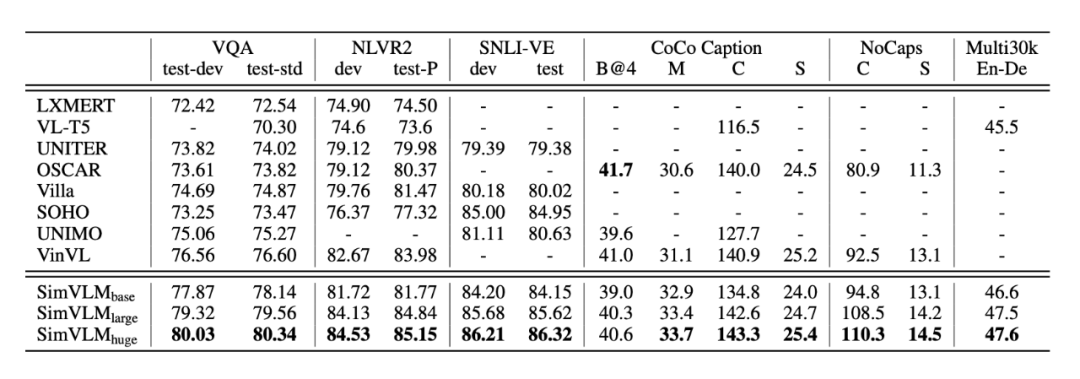
作者团队来自 CMU、谷歌、华盛顿大学。总体思路是用更大尺度弱监督数据做预训练,用一个语言建模的目标去进行端到端地训练。在相当多任务上达到 sota,尤其在 VQA2.0 上,达到了 80 的准确率,刷新认知,犹记得大四下做 VQA 时,准确率还停留在 70 出头,当时想上个 70 都很难,现在都卷到 80 了。。SimVLM 预训练更简单,不需要做目标检测(不需使用区域化特征)或辅助的损失(比如lxmert 里使用了 5 个预训练任务),但是获得了很好的表现。并且模型有很强的泛化能力,在零样本学习中同样表现良好。
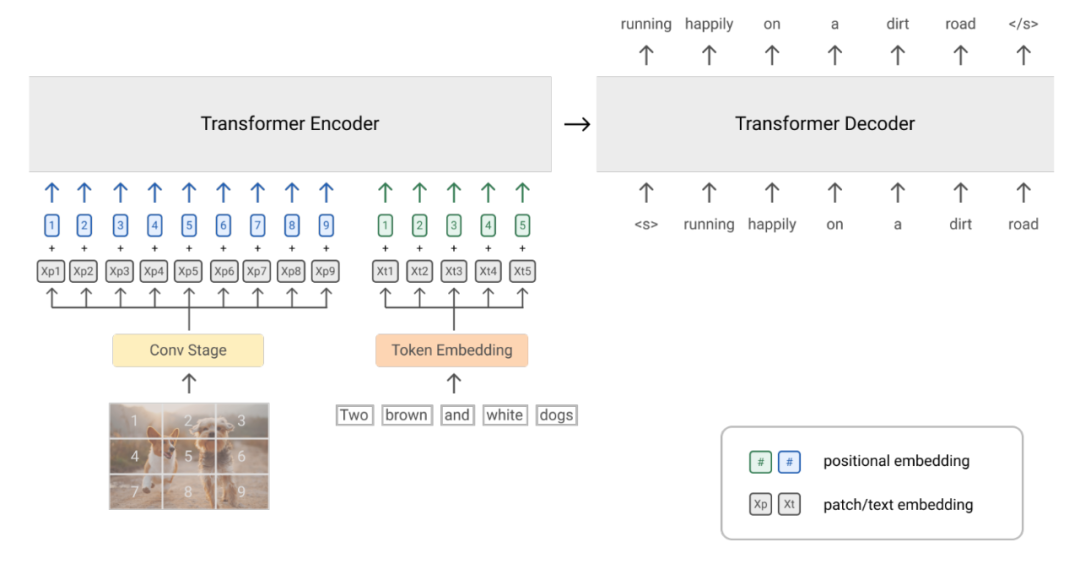
simvlm 使用的结构还是 transformer,与之前的模型的一个区别在于预训练方法的不同,本文使用 prefixLM。之前的预训练一般用 MLM,建模双向的关系,或者生成式的 LM,逐词生成,建模单向的关系。prefixLM 算是两者的结合,即给定前半段文本,逐词生成后半段文本。
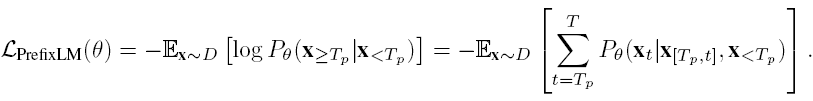
预训练的数据取用的是大尺度的图片-文本对(由于数据量很大,所以也含有较多噪声),数据来自 Scaling up visual and vision-language representation learning with noisy text supervision 。由于预训练任务对模态不敏感,所以也可以用纯文本加入预训练,弥补图片-文本对时包含的噪声。
实验
设计了三种变体:base、large、huge。具体超参数设置见原文。使用 AdamW 做优化器。在 5 个下游任务作了微调:VQA、Visual entailment(视觉文本关系判断)、视觉推理、image caption、多模态翻译。
零样本生成任务:不需微调训练。比如 image caption,在推理时,给一个前缀 prompt“a picture of”,就可以生成后续的描述。获得了和监督学习一样好的效果。还比如开放域 VQA 等。

METER
论文标题:
An Empirical Study of Training End-to-End Vision-and-Language Transformers
论文地址:
https://arxiv.org/abs/2111.02387
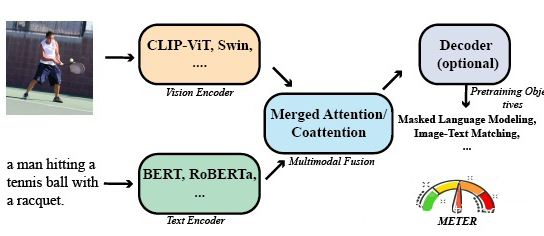

这篇文章就是在视觉、语言特征提取上用了最新的有效的基于 transformer 的模型比如 swin、roberta 等,最后在下游任务上,比如 VQA2.0,取得了仅次于 simvlm 的结果,文章强调了 meter 的预训练数据只有 4M,而 simvlm 用了 1.8B。
这篇文章做了大量的实验,在每一个环节都尝试了大量的方法,经典“a+b”,不过大部分这些预训练的文章感觉创新都不是很大。结构上,视觉特征用了 ViT,DeiT,Distilled-DeiT,CaiT,VOLO,BEiT,Swin Transformer,CLIP-ViT,文本用了 BERT,RoBERTa,ELECTRA,ALBERT,DeBERTa。融合模块用了双流和单流两种。整体结构有 Encoder-Only,Encoder-Decoder 两种。
预训练又试了很多:MLM、ITM、MIM(设计了两种 masked patch classification 方法)(mim 用处不大)。
实验
证明了文本 roberta、视觉 swin transformer、CLIP-ViT-224/16 效果较好。
发现的 trick:(1)随机初始化的权重设置学习率应大于有预训练的权重的学习率;(2)用插值等方法提高图像分辨率。
融合部分 co-attention 优于 merged attention。
预训练部分证明了 MLM 和 ITM 是有效的,MIM 起反作用。

VLMO
论文标题:
VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
论文地址:
https://arxiv.org/abs/2111.02358
这篇论文也是 11 月份刚挂在 arxiv 上的多模态预训练模型 VLMO。作者团队来自微软。

本文作出的主要改进在于这几个方面:对 transformer 结构做了一些修改,将传统编码器的 FFN 分为三条路径(视觉、语言、跨模态),分别构成了 dual encoder 和 fusion encoder,可以分别适用于不同的下游任务,比如检索任务用 dual、需要跨模态语义信息的分类任务用 fusion;预训练任务分阶段进行,image-only、text-only、image-text。
作者认为多模态编码器可以分为两类,一类是像 CLIP、ALIGN 这样的 dual encoder,分别对图片、文本编码后,计算一个编码特征之间的相似度;一类是 fusion encoder,就是我们常见的这些,挖掘跨模态的语义信息。vlmo 做的事情主要就是把两类融合起来,这样可以适用的预训练、下游任务更广泛。
具体方法。图片表征和 vit、vilt 相同,分 patch,再展平做线性映射作为输入。(这种方法最大的优势就是快,但从 vlit 结果来看,准确率有点拉,这篇文章虽然也用这种方法,但是准确率很高)文本编码一样,联合特征就是拼接起来。模型结构比较灵活,要单独编码图片、文本时,就用 V-FFN、L-FFN,编码拼接起来的图片文本序列时,用 VL-FFN。daul 时,就用前两层;fusion 时,底层用前两个分别编码,上层用 VL-FFN 编码高级特征。
预训练。三个:Image-Text Contrast,一个 batch 的图片、文本作对比学习,对角线上是正样本对(这是一般的方法,但本文的方法分为图片对文本、文本对图片的相似度,没太看懂);MLM;ITM。预训练在三类数据上分阶段进行。实验也是常用的四个预训练数据集:coco、vg、sbu、gcc。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)