零、数据集以及数据集简介以及任务分析
项目任务:
根据海量广告投放的用户点击数据,通过机器学习构建预测模型预估用户的是否进行广告点击,即给定某条广告相关的媒体、上下文内容等信息和用户标签的条件下,预测这个用户是否点击此广告。我们的任务就是通过分析数据,对于数据进行
训练数据集
train1.txt和train2.txt
两个数据集可以使用pandas读入
| 字段 |
说明 |
| instance_id |
样本id |
| click |
是否点击 |
| adid |
广告id |
| advert_id |
广告主id |
| orderid |
订单id |
| advert_industry_inner |
广告主行业 |
| advert_name |
广告主名称 |
| campaign_id |
活动id |
| creative_id |
创意id |
| creative_type |
创意类型 |
| creative_tp_dnf |
样式定向id |
| creative_has_deeplink |
响应素材是否有deeplink(Boolean) |
| creative_is_jump |
是否是落页跳转(Boolean) |
| creative_is_download |
是否是落页下载(Boolean) |
| creative_is_js |
是否是js素材(Boolean) |
| creative_is_voicead |
是否是语音广告(Boolean) |
| creative_width |
创意宽 |
| creative_height |
创意高 |
| app_cate_id |
app分类 |
| f_channel |
一级频道 |
| app_id |
媒体id |
| inner_slot_id |
媒体广告位 |
| app_paid |
app是否付费 |
| user_tags |
用户标签信息,以逗号分隔 |
| city |
城市 |
| carrier |
运营商 |
| time |
时间戳 |
| province |
省份 |
| nnt |
联网类型 |
| devtype |
设备类型 |
| os_name |
操作系统名称 |
| osv |
操作系统版本 |
| os |
操作系统 |
| make |
品牌(例如:apple) |
| model |
机型(例如:“iphone”) |
一、数据预处理
1、加载检查数据
data = pd.read_csv("train1.txt",sep='\t')
data.append(pd.read_csv("train2.txt",sep='\t'))
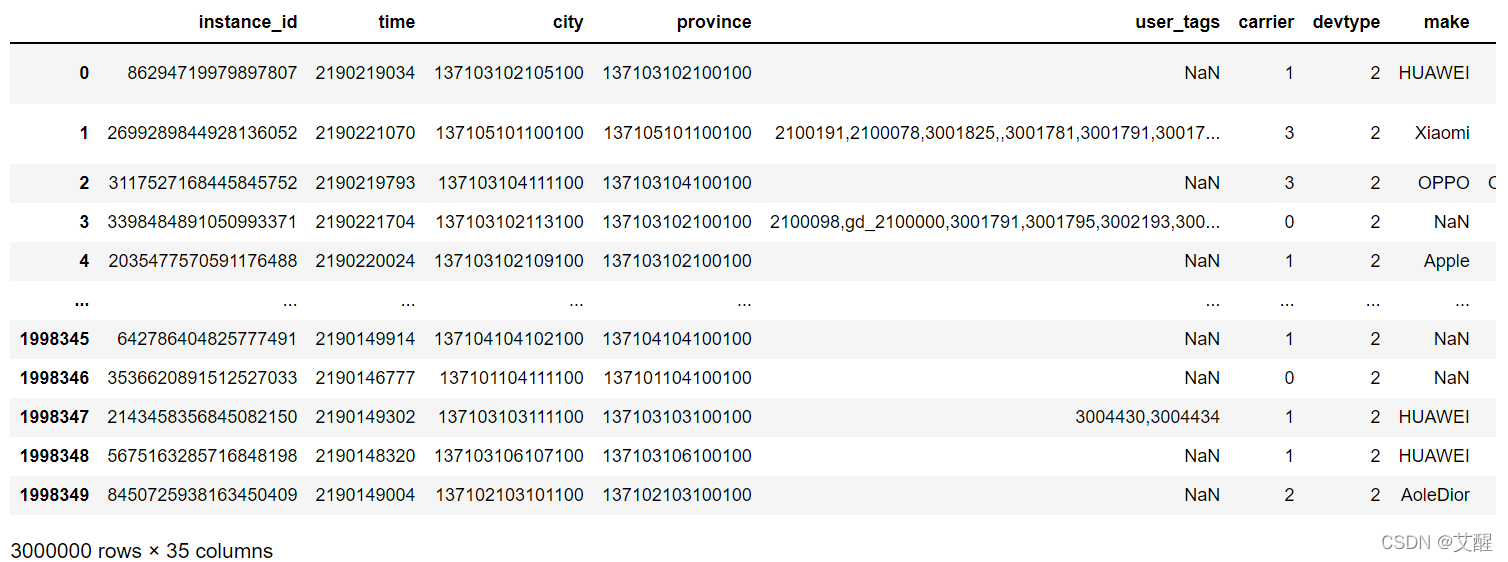
(1)特殊特征
我们可以看到user_tags这个特征和其他的有很大的区别,他包含了多个特征,并且每个数据所含的user_tags的特征并不相同,所以为了方便后期处理我们先把user_tags特征从data中分离出来单独处理
user_tags = data["user_tags"]
data = data.drop("user_tags", axis=1)
(2)特殊特征的处理
由于user_tags特征较为特殊,并且长度不唯一,所以我们采用以下方式对他进行处理
1.补全空数据,这里默认为空的数据即为没有任何标签,在这里我们规定设为标签‘0’
2.统计每种用户标签在用户中出现的次数
3.取前save_n个在用户中出现的最多作为保留标签
4.假设数据条数为n,建立一个形状为(n,save_n)的二维零矩阵:user_tags_mark
5.如果第i条数据的用户标签中存在保留标签j,我们将user_tags_mark的第i行第j列置为1
6.为了方便之后对新数据进行预测,我们将标签对应的出现次数:tags_dict以及user_tags和user_tags_mark的映射关系tags_map一并保存下来
def get_tags(user_tags, save_n):
user_tags.fillna('0', inplace=True)
tags_dict = dict()
for i in range(len(user_tags)):
tl = user_tags[i].split(',')
for t in tl:
if t in tags_dict.keys():
tags_dict[t] += 1
else:
tags_dict[t] = 1
tags_dict = sorted(tags_dict.items(), key=lambda x:x[1], reverse=True)[:save_n]
tags_dict = {key:value for key, value in tags_dict}
tags_map = {key:value for value, key in enumerate(tags_dict.keys())}
user_tags_mark = np.zeros((len(user_tags), len(tags_map)))
for i in range(len(user_tags)):
tl = user_tags[i].split(',')
for t in tl:
if t in tags_map.keys():
user_tags_mark[i][tags_map[t]] += 1
return user_tags, tags_dict, tags_map, user_tags_mark
user_tags, tags_dict, tags_map, user_tags_mark = get_tags(user_tags, 20)
(3)特殊特征处理后生成的新特征

2、数据类型与缺失值处理
(1)查看数据信息
data.info()
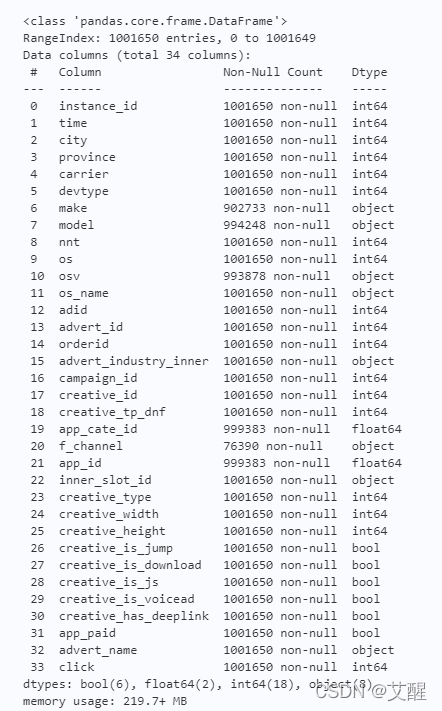
可以看到其中的make, model, osv, os_name, advert_industry_inner, f_channel, inner_slot_id, advert_name,app_cate_id, app_id都有缺失。但他们的补全方式不相同,其中make~advert_name的类型是object,观测数据后发现均是以字符串形式存储的数据、相关信息的缺失可以认为是由于技术手段或者用户不愿意透露导致的,所以这一部分信息的缺失本身也传达着一种信息,所以我们这里将这一类型的数据缺失标记为“NaN”,意为找不到其他数据信息。而app_cate_id, app_id数据类型为float,这里使用中位数来补全以反映大多数的情况。
注:此时的数据已经将user_tags分离出去了
(2)数据补全以及类型转换
由于计算机不能够对字符串格式的数据进行运算,所以我们要将字符串转换为计算机能够理解的标签,我们在数据补全的同时使用OrdinalEncoder将objects_list中的特征转换为标签的格式,并且将字符串和标签的对应关系保存下来(objects_cates)
objects_list = ["make", "model", "osv", "os_name", "advert_industry_inner", "f_channel", "inner_slot_id", "advert_name"]
floats_list = ["app_cate_id", "app_id"]
def Completer(data, bool_list=[], objects_list=[], floats_list=[]):
from sklearn.preprocessing import OrdinalEncoder
objects_cates = dict()
flag = False
for obj in objects_list:
flag = True
data[obj].fillna("NaN", inplace=True)
data_cat = data[[obj]]
encoder = OrdinalEncoder()
data_cat = encoder.fit_transform(data_cat)
cate_dict = dict()
categories = encoder.categories_[0]
for i in range(len(categories)):
cate_dict[categories[i]] = i
objects_cates[obj] = cate_dict
data[obj]=data_cat.reshape(-1, 1)[:,0]
for f in floats_list:
median = data[f].median()
data[f].fillna(median, inplace=True)
return data, objects_cates, flag
data, objects_cates, flag = Completer(data, bool_list, objects_list, floats_list)
(3)补全后的数据
3、异常值分析
运用EllipticEnvelope和KNNImputer识别异常值并进行修改
bool_list = ["creative_is_jump", "creative_is_download", "creative_is_js", "creative_is_voicead", "creative_has_deeplink", "app_paid"]
def OutlierHander(data, boll_list):
from sklearn.covariance import EllipticEnvelope
from sklearn.impute import KNNImputer
import numpy as np
for b in bool_list:
data[b] = data[b].astype(np.float64)
detector = EllipticEnvelope() # 构造异常值识别器
detector.fit(data) # 拟合识别器
idx = detector.predict(data) == -1# 预测异常值
ls = [i for i in range(len(data))]
data[idx] *= np.nan
imputer = KNNImputer()
data = imputer.fit_transform(data)
return data
data = OutlierHander(data, bool_list)
注:1.这个函数的运行过程会非常慢;2.要将所有的bool类型转换之后才能进行补全
二、 探索性分析与特征工程
众所周知,用户标签(user_tags)可以表明一个一个用户的偏好,从而一定程度上反映用户是否会对广告进行点击。但是这个标签是多维度的数据,尤其是在我们利用用户标签生成新的特征(user_tags_mark)之后,只取一部分用户标签信息来进行分析很明显会引导我们进入一个误区,所以我们在这里保留用户标签这个特征不做分析
1、单变量图分析
(1)原数据变量分析
data.hist(bins=51, figsize=(20, 15))
plt.show()
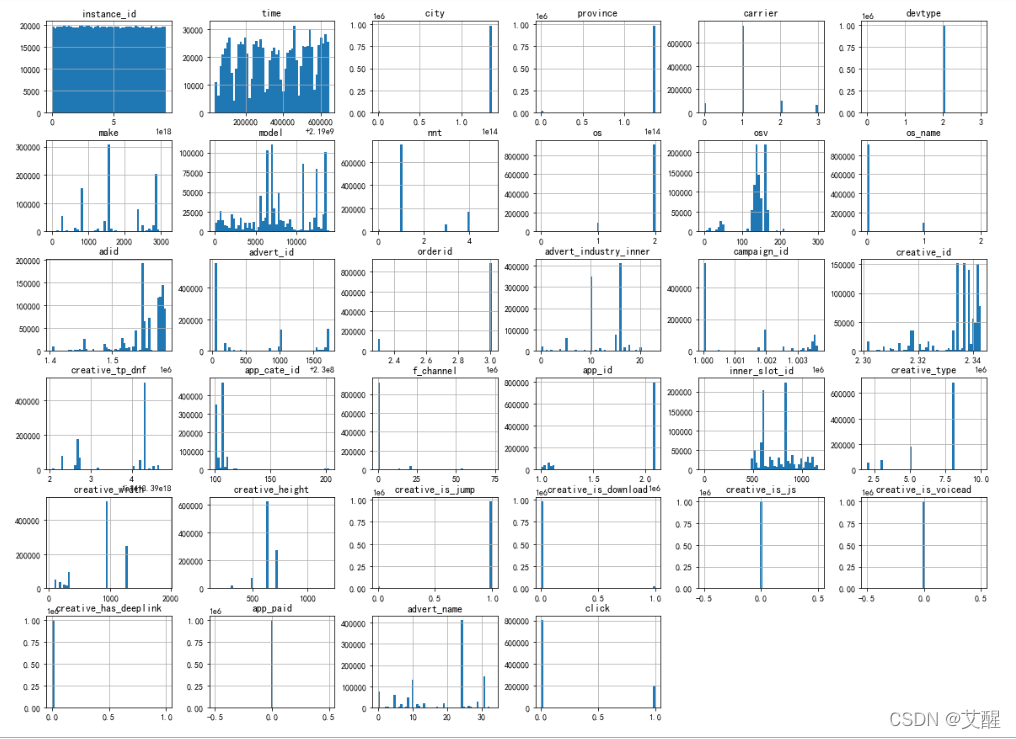
从图中可以看到:
1.样本id(instance_id)分布比较均匀,并且按照生活常识来讲他对是否点击广告没有什么影响,所以可以去掉这一特征
2.数据的分布的时间(time)呈周期性,说明收集到的数据跟时间相关,在不同时间段中能收集到的数据不同表明不同时间用户看到广告的次数不同,所以我们需要添加新特征,如:周、月特征
3.省份、城市、媒体id、广告id、广告主id、订单id、活动id、创意id、样式定向id由于编码问题会影响作图效果以及后续的训练效果,所以在这里我们做了一个数据映射
4.点击和不点击的数据正负样本不均衡,在训练前应该进行欠采样,即减少对负样本的采样
(2)处理数据
1.添加新特征
data["time"] = pd.to_datetime(df['time'],unit='s',origin=pd.Timestamp('1970-01-01'))
data["month"] = data["time"].dt.month
data["dayofweek"] = data["time"].dt.dayofweek
2.id映射
city_dict = {key:value for value, key in enumerate(set(data["city"]))}
for key, value in city_dict.items():
tmp = data[data["city"] == key]
tmp["city"] = value
data[data["city"] == key] = tmp
province_dict = {key:value for value, key in enumerate(set(data["province"]))}
for key, value in province_dict.items():
tmp = data[data["province"] == key]
tmp["province"] = value
data[data["province"] == key] = tmp
campaign_id_dict = {key:value for value, key in enumerate(set(data["campaign_id"]))}
for key, value in campaign_id_dict.items():
tmp = data[data["campaign_id"] == key]
tmp["campaign_id"] = value
data[data["campaign_id"] == key] = tmp
app_id_dict = {key:value for value, key in enumerate(set(data["app_id"]))}
for key, value in app_id_dict.items():
tmp = data[data["app_id"] == key]
tmp["app_id"] = value
data[data["app_id"] == key] = tmp
adid_dict = {key:value for value, key in enumerate(set(data["adid"]))}
for key, value in adid_dict.items():
tmp = data[data["adid"] == key]
tmp["adid"] = value
data[data["adid"] == key] = tmp
advert_id_dict = {key:value for value, key in enumerate(set(data["advert_id"]))}
for key, value in advert_id_dict.items():
tmp = data[data["advert_id"] == key]
tmp["advert_id"] = value
data[data["advert_id"] == key] = tmp
orderid_dict = {key:value for value, key in enumerate(set(data["orderid"]))}
for key, value in orderid_dict.items():
tmp = data[data["orderid"] == key]
tmp["orderid"] = value
data[data["orderid"] == key] = tmp
campaign_id_dict = {key:value for value, key in enumerate(set(data["campaign_id"]))}
for key, value in campaign_id_dict.items():
tmp = data[data["campaign_id"] == key]
tmp["campaign_id"] = value
data[data["campaign_id"] == key] = tmp
creative_id_dict = {key:value for value, key in enumerate(set(data["creative_id"]))}
for key, value in creative_id_dict.items():
tmp = data[data["creative_id"] == key]
tmp["creative_id"] = value
data[data["creative_id"] == key] = tmp
creative_tp_dnf_dict ={key:value for value, key in enumerate(set(data["creative_tp_dnf"]))}
for key, value in creative_tp_dnf_dict.items():
tmp = data[data["creative_tp_dnf"] == key]
tmp["creative_tp_dnf"] = value
data[data["creative_tp_dnf"] == key] = tmp
(3)数据处理后变量分析
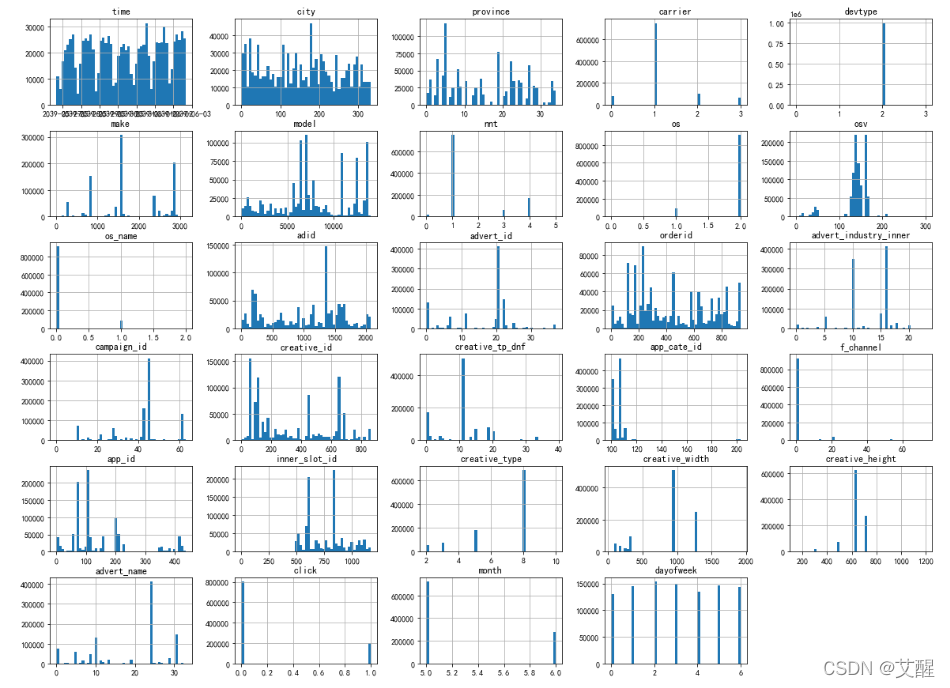
2、相关性关系分析
(1)计算相关矩阵
columns = ["tag"+str(i) for i in range(20)]
tags_mark = pd.DataFrame(user_tags_mark, columns=columns)
tags_mark["click"] = data["click"]
data_corr =data.corr()
tags_corr = tags_mark.corr()
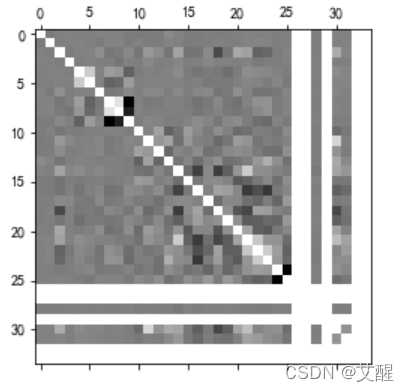
(2)热力图显示
data:
plt.matshow(data_corr, cmap=plt.cm.gray)
plt.show()
tags_mark:0
plt.matshow(tags_corr, cmap=plt.cm.gray)
plt.show()
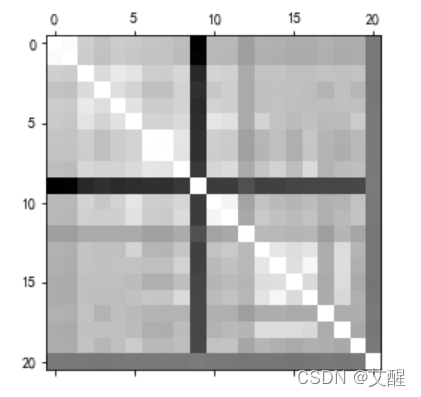
数值越大表明数据相关性越强,在图像中的颜色就越亮,根据data的相关矩阵生成的热力图有几行/列特别亮并不是因为他们的相关性特别强,而是因为相关性过弱导致数值成立NaN。同时可以看到tags_mark整体都比较亮,说明整体tags的相关性较强。但是data和tags的相关性并不大,说明带预测的结果与特征不是线性相关的,需要多个数据共同作用
3、特征工程与特征选择
data_corr["click"].sort_values(ascending=True)
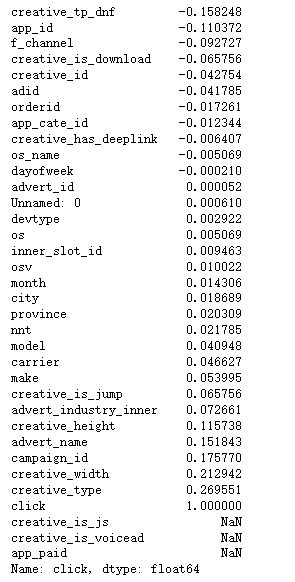
tags_corr["click"].sort_values(ascending=True)
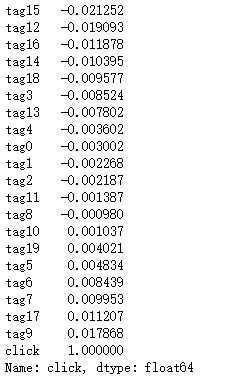
这里我们选用data中相关性较强的特征,而tags_ mark完全保留
4、双变量图分析
from pandas.plotting import scatter_matrix
attributes1 = ["creative_tp_dnf", "campaign_id", "creative_width", "creative_height", "app_id", "advert_name", "creative_type", "click"]
scatter_matrix(data[attributes1], figsize=(12, 8))
plt.show()
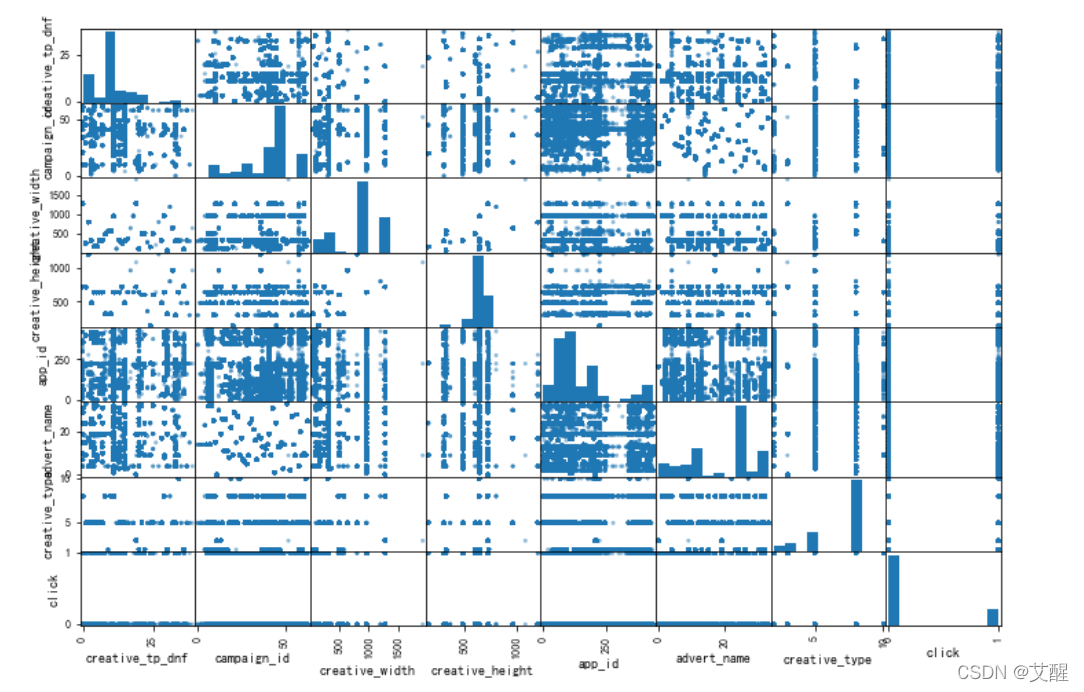
可以看到数据之间的联系不大,所以也不存在线性关系
5、新特征生成
在上面的数据分析的过程中已经生成了新特征:dayofweek, month和、user_tags_mask
现在需要将data中相关性较大的特征和tags_mark特征数据合并在一起
new_data = pd.concat([data[attributes1], tags_mark], axis=1)
new_data.tail()
三、机器学习模型交叉验证
1、欠采样并划分数据集
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from random import shuffle
idx = [i for i in range(len(new_data[new_data["click"] == 0]))]
shuffle(idx)
idx = idx[:len(new_data[new_data["click"] == 1])]
data_0 = new_data[new_data["click"] == 0]
data_sample = data_0.sample(n=len(new_data[new_data["click"] == 1]))
new_data = data_sample.append(new_data[new_data["click"] == 1])
x_train, x_test, y_train, y_test = train_test_split(new_data.drop("click", axis=1), new_data["click"], test_size = 0.3, random_state = 7)
2、归一化
data_std = StandardScaler()
data_std.fit(x_train)
x_train = data_std.transform(x_train)
x_test = data_std.transform(x_test)
3、不同模型进行交叉验证对比效果
由于数据较大,考虑到效率问题首先排除KNN和SVM
(1)决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
tree = DecisionTreeClassifier()
tree.fit(x_train, y_train)
cross_val_score(tree, x_test, y_test)
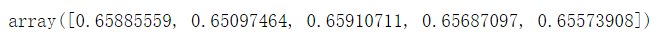
(2)贝叶斯
from sklearn.naive_bayes import BernoulliNB
nb = BernoulliNB()
nb.fit(x_train, y_train)
cross_val_score(nb, x_test, y_test)
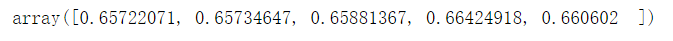
(3)随机森林
from sklearn.ensemble import RandomForestClassifier
rd_tree = RandomForestClassifier()
rd_tree.fit(x_train, y_train)
cross_val_score(rd_tree, x_test, y_test)
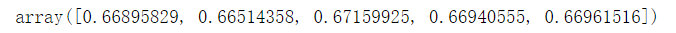
(4)bagging
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=100)
bag_clf.fit(x_train, y_train)
print("bagging:")
print("交叉验证:", cross_val_score(sgd, x_test, y_test))
print("精度:", precision_score(y_test, bag_clf.predict(x_test)))
print("召回率:", recall_score(y_test, bag_clf.predict(x_test)))

(5)ada boosting
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(), n_estimators=100)
ada_clf.fit(x_train, y_train)
print("ada:")
print("交叉验证:", cross_val_score(ada, x_test, y_test))
print("精度:", precision_score(y_test, ada_clf.predict(x_test)))
print("召回率:", recall_score(y_test, ada_clf.predict(x_test)))

(6)逻辑回归
from sklearn.linear_model import LogisticRegression
reg = LogisticRegression()
reg.fit(x_train, y_train)
cross_val_score(reg, x_test, y_test)
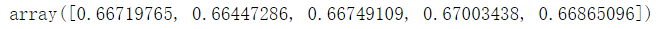
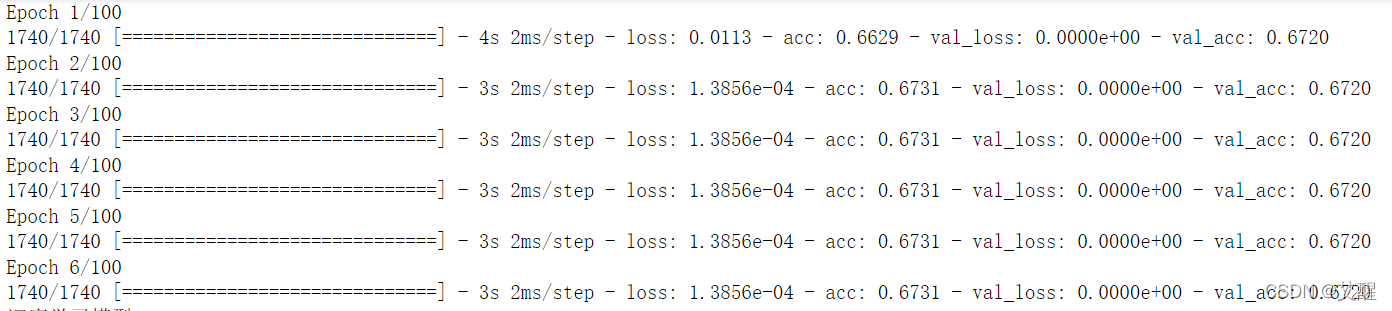
(7)深度学习全连接模型
def to_one_hot(y):
ans = np.zeros((len(y), 2))
for i in range(len(y)):
ans[i][y[i]] = 1
return ans
y_train_hot = to_one_hot(y_train)
y_test_hot =to_one_hot(y_test)
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.layers import Dense, Input
from keras.models import Model
early_stopping_cb = EarlyStopping(patience=5, restore_best_weights=True)
checkpoint_cb = ModelCheckpoint("datas.h5", save_best_only=True)
data_input = Input(shape=(27,))
data_layer1 = Dense(128)(data_input)
data_layer2 = Dense(64)(data_layer1)
data_layer3 = Dense(32)(data_layer2)
data_layer4 = Dense(2)(data_layer3)
data_model = Model(data_input, data_layer4)
data_model.compile(optimizer='rmsprop',loss='binary_crossentropy', metrics=['acc'])
data_history = data_model.fit(np.array(list(x_train)), np.array(list(y_train_hot)), epochs=100, validation_split=0.2, batch_size=128, callbacks=[early_stopping_cb, checkpoint_cb])
(8)随机梯度下降
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier()
sgd.fit(x_train, y_train)
cross_val_score(sgd, x_test, y_test)
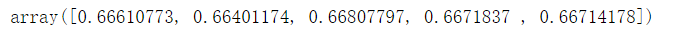
(9)xgboost
from xgboost import XGBClassifier
from sklearn.metrics import log_loss
xgb = XGBClassifier()
xgb.fit(x_train, y_train, eval_metric="logloss")
(10)GradientBoosting
由于GradientBoosting属于弱分类器,所以我们这里使用bagging将他集成起来以达到更好的效果
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import BaggingClassifier
gbc = GradientBoostingClassifier()
gbc_bag = BaggingClassifier(gbc, n_estimators=80)
gbc_bag.fit(x_train, y_train)
(11)投票器
from sklearn.ensemble import VotingClassifier
vot_clf = VotingClassifier(estimators=[
('xgb_clf', xgb),
('gbc_bag_clf', gbc_bag)], voting = 'soft')
vot_clf.fit(x_train, y_train)
cross_val_score(vot_clf, x_test, y_test, cv=5)
4、精度和召回率
|
决策树 |
随机森林 |
bagging |
ada boosting |
逻辑回归 |
深度学习全连接模型 |
随机梯度下降 |
贝叶斯 |
| 测试数据精度 |
0.632 |
0.635 |
0.634 |
0.633 |
0.611 |
0.501 |
0.606 |
0.613 |
| 测试数据召回率 |
0.783 |
0.816 |
0.812 |
0.8095 |
0.926 |
0.326 |
0.951 |
0.867 |
5、logloss
|
决策树 |
随机森林 |
bagging |
ada boosting |
逻辑回归 |
深度学习全连接模型 |
随机梯度下降 |
贝叶斯 |
xgboost |
GradientBoosting |
| 测试数据logloss |
13.29 |
1.00 |
0.59 |
0.74 |
0.58 |
11.0 |
13.57 |
0.78 |
0.423 |
0.429 |
| 从上表中可以看到本问题适合使用基于树和集成学习的模型 |
|
|
|
|
|
|
|
|
|
|
四、对模型进行超参数调整
1、针对最佳模型,进行超参数优化
根据上述分析我们可以得到这样一张表
|
决策树 |
随机森林 |
bagging |
ada boosting |
逻辑回归 |
深度学习全连接模型 |
随机梯度下降 |
贝叶斯 |
xgboost |
GradientBoosting |
| 测试数据准确率 |
0.664 |
0.669 |
0.666 |
0.664 |
0.667 |
0.672 |
0.666 |
0.657 |
- |
- |
| 测试数据精度 |
0.632 |
0.635 |
0.634 |
0.633 |
0.611 |
0.501 |
0.606 |
0.613 |
- |
- |
| 测试数据召回率 |
0.783 |
0.816 |
0.812 |
0.8095 |
0.926 |
0.326 |
0.951 |
0.867 |
- |
- |
| 测试数据logloss |
13.29 |
1.00 |
0.59 |
0.74 |
0.58 |
11.0 |
13.57 |
0.78 |
0.423 |
0.429 |
综合考虑下我们选用xgboost和GradientBoosting进行参数优化
2、评估效果
对xgboost和GradientBoosting模型评估并调参后得到的结果
|
xgboost |
GradientBoosting |
| logloss |
0.417 |
0.416 |
五、结论
得出结论性分析
随机梯度下降模型虽然在精度上表现一般,但是在准确率和召回率上表现很好,尤其是召回率,他的召回率的最高的。逻辑回归的召回率相对较低,logloss较低,但是logloss仍然没达到一个令人满意的程度,xgboost和GradientBoosting的logloss是全体模型中最低的。根据投放广告的实际需求我们可以选择不同的模型,如果苛求每个会点击的用户都能看到广告可以盲目的追求召回率来选择随机梯度下降;如果对logloss有要求,但是要求不高,可以选择逻辑回归;如果侧重于logloss可以选择xgboost和GradientBoosting如果追求更好的效果还可以使用投票器选择最符合评判标准的模型进行投票还可以选择LGBM或者选用对xgboost和GradientBoosting集成学习来获取更好的结果