pooling层是如何进行反向传播的?
- average pooling: 在前向传播中,就是把一个patch的值取平均传递给下一层的一个像素。因此,在反向传播中,就是把某个像素的值平均分成n份 分配给上一层。
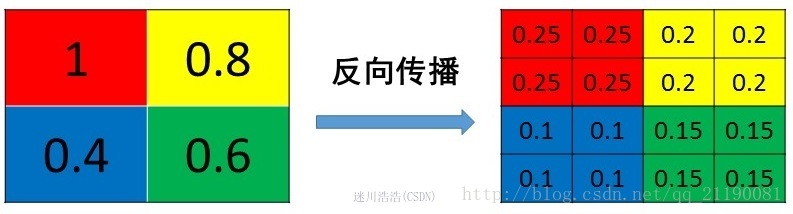
- max pooling: 在前向传播中,把一个patch中最大值传递给下一层,其他值会被舍弃掉。因此,在反向传播中,就是将当前梯度直接传递给前一层的某个像素,而让同一个patch中的其他像素值为0。

pooling层的作用
- 增加非线性。
- 保留主要的特征同时减少参数和计算量,防止过拟合,提高模型的泛化能力。
- 提供invariance(不变性),包括平移, 旋转,尺度等
- 增大感受野
ROI Pooling 和 ROI Align区别
ROI Pooling:使用两次量化操作,分割任务像素级导致定位偏移太大,检测还是没太大影响。
ROI Align: 并没有采用两次量化,仅使用双线性插值算法。
Cascade RCNN的motivation
**先介绍Faster RCNN中相关点:**在训练阶段,经过RPN提取2000左右proposals, 这些proposals会被送入到Fast RCNN中。在Fast RCNN中首先会计算每个proposals 和gt之间的IOU,然后通过人为设定的IOU阈值,把这些proposals分成正负样本,并对这些样本进行采样,使得他们之间的比例尽量满足1:3(128),之后将128个proposals送入Roi Pooling,最后进行类别分类和box回归。在inference阶段,RPN网络提取300左右的proposals,而300个全被当作正样本送去分类和回归。
Cascade中所提出的问题:
- 过拟合问题,提高IOU阈值,满足这个阈值条件的proposals必然比之前少了, 容易导致过拟合
- 更加严重的mismatch问题:训练阶段都是质量比较高的proposal,会导致过拟合,而inference阶段由于没有经过阈值的采样,因此会存在很多的质量较差的proposals,而检测器之前都没见过这么差的proposal。
难负样本挖掘(OHEM) 和 Focal loss的区别
OHEM:
- 硬加权
- 选中的样本,权重为1。滤掉的样本,权重为0。
- 挖掘固定比例或数量的样本
- 不能充分利用所有样本
Focal Loss:
- 软加权
- 分类越正确(容易样本),权重越低
- 分类越错误(困难样本), 权重越高
- 所有的样本都能参与训练,能够充分利用所有样本。
插值算法
最近邻插值
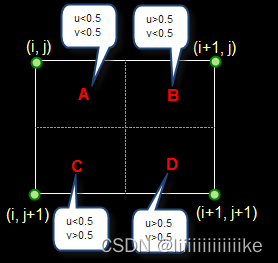
算法:在待求像素的四个邻域中,将距离待求像素最近的像素值赋值给待求像素,如下图待求像素为(i+u, j+v)的像素灰度值,其中i和j为正整数,如果u<,0.5 v <0.5则把(i,j)这个值赋值给待求像素点, 在FPN中从下到上的上采样使用的就是最近邻插值
双线性插值
算法:利用待求像素四个相邻像素的灰度在两个方向上做线性插值,也就是做两次线性变换。
优缺点:计算量比最近邻插值更大,但没有灰度不连续的缺点
三次内插法
利用三次多项式求逼近理论上的最佳插值函数,待求像素的灰度值由其周围16个灰度值加权内插得到。
三者比较:
- 效果:最近邻插值 < 双线性插值 < 三次插值
- 速度:最近邻插值 > 双线性插值 > 三次插值
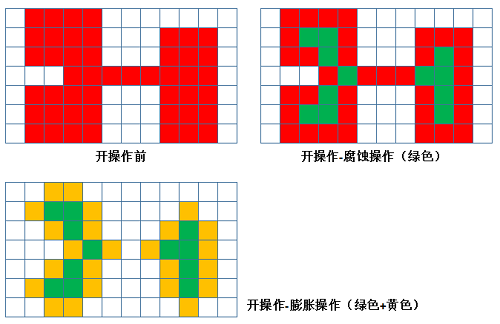
开操作和闭操作
开操作:
- 先腐蚀,再膨胀
- 开操作可以移除较小的明亮区域,在较细的地方分离物体。
- 应用例子:通过开操作将阈值处理后的细胞分离,可以更清晰地统计细胞的数目
闭操作:
- 先膨胀,后腐蚀
- 闭操作可以填充物体内的细小空间、连接邻近的明亮物体

顶帽操作
步骤:原图与开操作的差
效果:局部亮度极大点被分割出来
黑帽操作:
步骤:闭操作与原图的差
效果:局部黑色的洞被分割出来
目标检测anchor -base 和 anchor-free
anchor-based:
优点:
- 使用anchor机制产生密集的anchor box, 使得网络可直接在此基础上进行目标分类及边界框坐标回归。加入先验框,训练稳定
- 密集的anchor box可有效提高网络目标召回率,对于小目标检测来说提升非常明显
缺点:
- anchor机制下,需要设定超参,这需要较强的先验知识
- 造成严重的正负样本不平衡问题
- 泛化能力差
anchor-free:
优点:
- anchor-free要比anchor-base少2/3在预测的时候计算量
- 不需要设定超参数
- 容易部署,解码方便:直接对heatmap使用池化,就等价于做了NMS,然后利用偏移和宽高就可以获得对应的检测框。(FCOS使用nms,centernet使用池化)。nms计算只能在cpu上,无法在GPU上并行
缺点:
- 语义模糊性(两个目标中心点重叠),现在主要是用focal loss和FPN来缓解
- 通用能力差,泛化能力强
anchor-base流程:
- 在图像中提前铺设大量的anchor
- 回归目标相对于anchor的四个偏移量
- 用对应的anchor和回归的偏移量修正精确的目标位置
目标检测中为什么要引入anchor?
相当于在检测网络中引入先验信息,因为在一张图片中修正目标位置比定位目标位置更容易一些
anchor-free
anchor-free的精度能媲美anchor-based方法:最大功劳归于FPN(提供多尺度信息),其次归于Focal Loss(对中心区域的预测有很大帮助)
基于anchor-free的目标检测算法有两种方式:
- 关键点检测:通过定位目标物体的几个关键点来限定它的搜索空间。
- 中心点检测:通过目标物体的中心点来定位,然后预测中心到边界的距离。
基于关键点检测算法
CornerNet通过检测目标框的左上角和右下角两个关键点获得预测框。整个网络流程:输入图像通过串联多个Hourglass模块来特征提取,然后输出两个分支,即左上角预测分支和右下角点预测分支;每个分支模型通过corner pooling后输出三个部分:1. heatmaps:预测角点位置 2. embeddings:预测角点分组 3. offsets:微调预测框。
基于关键点检测算法
CenterNet 只需要提取目标的中心点,无需对关键点分组和后处理。网络结构采用编解码的方式提取特征,输出端分为三块:1. heatmap:预测中心点的位置 2. wh:对应中心点的宽高 3. reg:对应中心点的偏移
centernet推理:
- 输入图片
- 对输入图片进行下采样,在128*128大小的heatmap上执行预测;
- 然后在128*128大小的heatmap上采用3x3的最大池化操作来获取heatmap中满足条件的关键点(类似nms效果),并选取100个关键点
- 最后根据confindence阈值来过滤最终的检测结果
目标检测为什么要考虑去掉anchor?
- 预先设定的anchor尺寸需要根据数据集的不同做改变,可以人工设置或对数据集聚类得到
- anchor的数量相比目标的个数多很多,造成正负样本不均衡的现象
ATSS:自适应的选取正样本
- 对于每个输出的检测层,计算每个anchor的中心点和目标中心点的L2距离,选取K个anchor中心点离目标中心点最近的ahchor为候选正样本
- 计算每个候选正样本和GT之间的IOU,计算这组IOU的均值和方差
- 根据均值m和方差g,设置选取正样本的阈值:t = m + g
特征提取器:通过函数,将同一类型的数据分布,映射到同一解空间,归为一类
为什么max pooling更常用?什么场景下average pooling比max pooling更合适?
- max pooling做特征选择,选出分类辨识度更好的特征,提供了非线性。pooling作用一方面是去掉冗余信息,一方面保留feature map的特征信息,在分类问题中,我们需要知道图像有什么object,而不关心这个object位置在哪,显然max pooling比average pooling更合适。
- average pooling 更强调对整体信息进行一层下采样,在减少参数维度的贡献上更大一点,更多体现在信息的完整传递这个维度上,在一个很大很有代表性的模型中,比如说DenseNet中的模块之间的连接大多采用average pooling,在减少维度的同时,更有利信息传递到下一个模块进行特征提取。
数据增强方式
- 单样本几何变换:翻转、旋转、裁剪、缩放
- 单样本像素内容变换:噪声、模糊、颜色扰动
- 多样本插值mix up: 图像和标签都进行线性插值
为什么在模型训练开始会有warm up ?
warm up在刚刚开始训练时以很小的学习率进行训练,使网络熟悉数据,随着训练的进行,学习率慢慢变大,到了一定程度,以设置的初始学习率进行训练。
- 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
- 有助于保持模型深层的稳定性
简述一下 R CNN到Faster R CNN
- R CNN
- 首先通过Selective Search算法在图片上获取2000个左右Region Proposal
- 将这些Region Proposal通过预处理统一尺寸输入到预训练的cnn中进行特征提取
- 然后将提取的特征输入到SVM中进行分类
- 最后对分类后的region proposal进行bbox回归。
- SPPNet
- Fast R CNN
- 首先通过selective search算法在图片上获取2000个左右region proposal;
- 接着对整张图片进行特征提取;
- 然后利用region proposal坐标在CNN的最后一个特征图上进去ROI pooling提取目标特征
- 然后将ROI pooling提取到的特征输入到FC模块中,此时算法的整个过程相比R-cnn 得到极大简化, 但依然无法联合训练
- Faster Rcnn
- 首先通过可学习的RPN网络进行Region Proposal的提取
- 接着利用region proposal坐标在CNN的特征图上进行ROI pooling操作
- 然后利用ROI pooling进行空间池化使其所有特征图输出尺寸相同
- 最后将所有特征图输入到后续的FC层进行分类和回归,实现了端到端的训练。
阐述一下mask rcnn网络,并相比与faster rcnn有哪些改进的地方
mask rcnn是基于faster rcnn提出的目标检测网络,该网络可以有效地完成目标检测的同时完成实例分割。mask rcnn主要的贡献如下:
- 强化了基础网络:通过ResNext101+fpn用作特征提取网络
- Roi align替换了faster rcnn中的roi pooling
- 使用新的损失函数:mask rcnn的损失函数是分类+回归+mask预测的损失之和
阐述一下SSD网络及其优缺点
SSD网络是对不同尺度下的feature map的每个点都设置一些default box,这些default box有不同的大小和纵横比,对这些框进行分类和边框回归的操作。SSD的核心是固定设置default box计算属于各类物体的概率以及坐标调整的数值。
优点:ssd运行速度超过yolo,精度在一定条件下超过faster rcnn。
缺点:需要人工设置先验框和长宽比,网络中default box的基础大小和形状不能直接通过学习获得,虽然使用了图像金字塔的思路,但对小目标的召回率依然一般。
FPN为什么能提升小目标的准确率?
底层的特征语义信息比较少,但是目标定位准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。原来多数的object detection算法都是用高层特征做预测。FPN同时利用底层和高层的语义信息,通过融合这些不同特征层的特征达到预测的效果,并且预测是在每个融合后的特征层上单独进行的。
训练过程中loss一直无法收敛可能的原因
- 数据和标签的问题
- 学习率设定不合理
- 网络模型不合理
- 数据归一化
为什么图像输入到网络之前需要进行归一化操作?
- 如果输入层很大,在反向传播时候传递到输入层的梯度会变得很大。梯度很大,学习率就得非常小,否则越过最优。
- 一般归一化是做减去均值除以方差的操作,这种方式可以移除图像的平均亮度值,很多情况下我们对图像的亮度并不感兴趣,而更多地关注其内容,比如在目标检测任务追踪,图像的整体明亮程度并不会影响图像中存在的是什么物体。此时,在每个样本上做归一化可以移除共同部分,凸显个体差异。
Yolox中nms free采用的pss结构

在最后增加一个pss分支,用来代替nms,并提出与其相匹配的loss。
在inference的时候,最终bbox得分是

然后正负样本直接对这个数进行排序,取topk得到,无nms过程。
Batchsize如何影响模型性能?
- 大的batch size减少训练时间,提高稳定性
- 大的batch size导致模型泛化能力下降,主要原因是小的batch size带来的噪声有助于逃离局部最优
- batch size在变得很大(超过临界点),会降低模型的泛化能力,在此临界点之下,模型的性能变换随batch size通常没有学习率敏感。
数据增强的方式
- 随机裁剪:可保留主要特征,裁剪掉背景噪声
- mixup:两张图按0.5比例叠加,增加样本数量,丰富了目标背景,提高模型的泛化能力
- cutmix:cutout和mixup结合,将图片的一部分区域擦除并随机填充训练集中的其他数据区域像素值
- random erasing:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景
- cutout:只用正方形填充,填充值只有0或其他纯色填充(作者发现区域的大小比形状更重要)
参数初始化
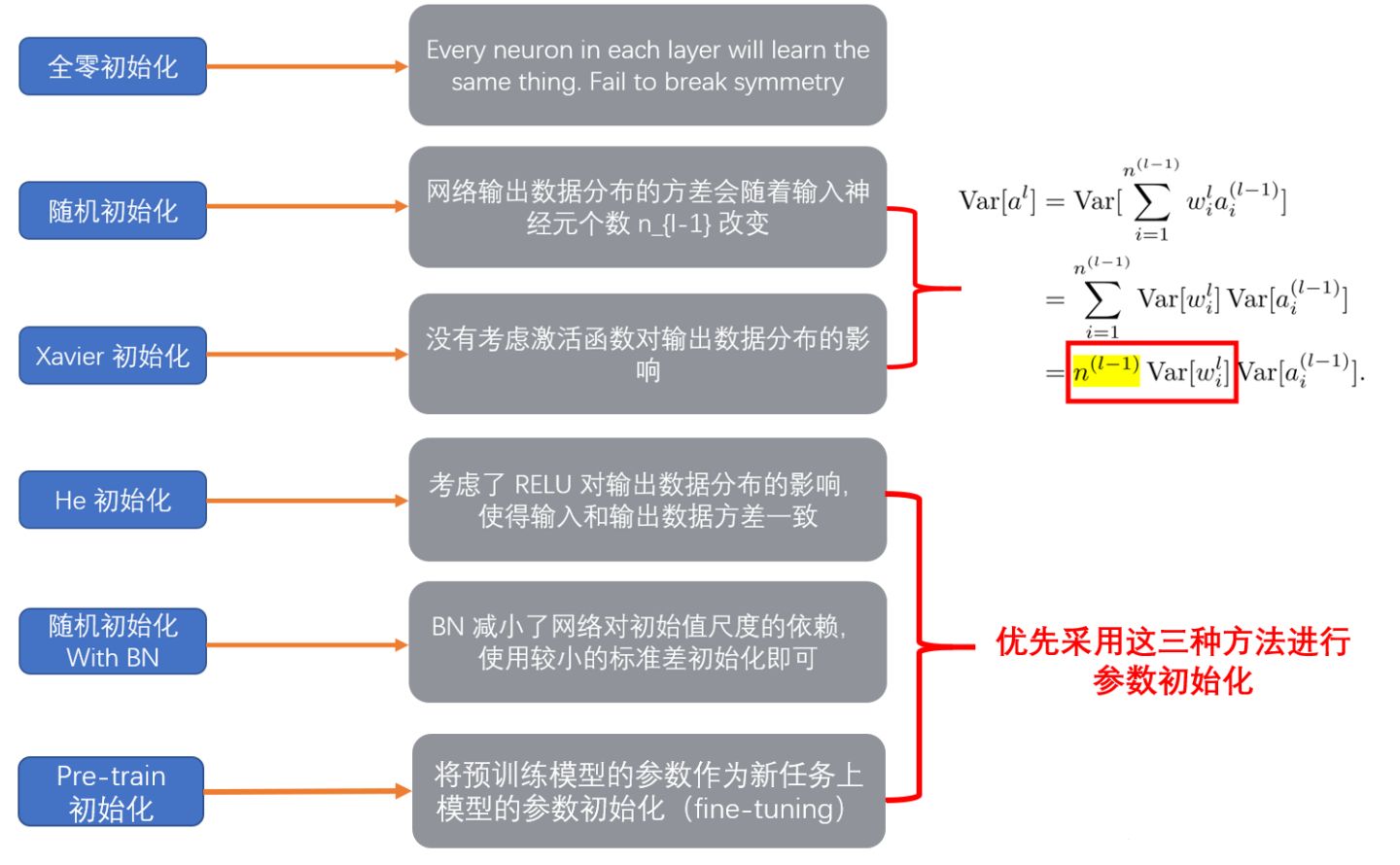
- 随机初始化:过小导致梯度消失,过大导致梯度爆炸
- 带BN的随机初始化:BN可以将过大过小的数据都归一化到0-1分布,避免了梯度爆炸和梯度消失的情况
- xavier初始化(泽维尔):保证输入和输出的数据分布一致,即保证输入输出的均值和方差一致。
- he初始化:xavier适合关于0点对称的激活函数,不适合relu,解决思想:在relu网络中,假定每一层有一半神经元被激活,另一半为0,所以要保持方差不变,只需要在xavier基础上再除以2

pytorch中function和module的区别
- function只是定义一个操作,无法保存参数;module是保存了参数,因此适合定义一层
- function需要定义三个方法:init,forward,backward;module只需要定义init和forward,而backward的计算由自动求导机制构成
- module由一系列的function组成,因此在forward的过程中,function和variable组成了计算图,在backward时,只需要调用function的backward就可以得到结果,因此module不需要再定义backward
- module不仅包括了function,还包括了对应的参数,以及其他函数与变量
python列表、元组、集合和字典的区别 list set dict

Relu 优缺点
优点:
- 不存在梯度饱和
- 收敛速度快
- 计算效率高,且将负值截断为0,为网络引入了稀疏性,进一步提升了计算高效性
缺点:
- Relu的输出不是0均值对称,导致梯度更新方向出现锯齿路径
- dead relu问题。解决方法:1. 学习率不要设置过大,使用动量等优化方法 2. leaky relu:α 取值0.01 PRelu: α是可学习参数
- 没有对数据做压缩,容易出现nan
- 低维度做relu运算容易造成信息的丢失,而高维度进行relu运算信息丢失则会很少
内部协变量偏移(ICS)
每个神经元的输入数据不再是”独立同分布‘
- 上层参数需要不断适应新的输入数据分布,降低学习速度
- 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止
- 每层的更新都会影响到其他层,因此每层的参数更新策略需要尽可能的谨慎
YOLO系列
v1创新点:
- 将整张图作为网络输入,直接在输出层回归bounding box的位置和所属的类别
- 速度快,one-stage detection开山之作
v2创新点:
- 大尺度预训练分类
- 新的backbone:Darknet19
- 加入anchor
v3创新点:
- 新的backbone:Darknet53
- 融合FPN
- 用逻辑回归替代softmax作为分类器
改善模型思路
工业落地流程
- 产品定义,需求调研
- 场景约束,数据采集
- baseline开发,针对性优化
- 算法部署,多维测试
- 持续维护,功能拓展
TensorRT
将现有的模型编译成一个engine,类似于c++编译过程。在编译engine过程中,会为每一层的计算操作寻找最优的算子方法,将模型结构和参数以及相应kernel计算方法都编译成一个二进制engine,因此在部署之后大大加快了推理速度。
优势:
- 把一些网络层进行了合并
- 取消一些不必要的操作,比如不用专门做concat操作
- TensorRT会针对不同的硬件做相应的优化,得到优化后的engine
- TensorRT支持INT8和FP16的计算,通过在减少计算量和保持精度之间达到一个理想的trade-off
端侧静态多batch和动态多batch的区别
当设置静态多batch为6时,那么之后不管是输入batch=2还是batch=4,都会按照batch=6的预设开始申请资源。
而动态多batch不用预设batch数,会根据实际场景中的真实输入batch来优化资源的申请,提高端侧实际效率,由于动态多batch的高性能,通常推理耗时和内存占用会比静态batch时要大。
滑动平均
用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关,

滑动平均的优势:占用内存少,不需要保存过去10个或者100个历史值,就能估计其均值。滑动平均虽然不如将历史值全部保存下来计算准确,但后者占用更多内存,并且计算成本更高。
为什么滑动平均在测试过程中被使用?
滑动平均可以使模型在测试数据上更加鲁棒。
python中实例方法、静态方法和类方法三者的区别?
- 不用@classmethod和@staticmethod修饰的方式为实例方法
- 采用@classmethod修饰的方法为类方法
- 采用@staticmethod修饰的方法为静态方法
DataLoader内部调用方式步骤:
-
确定数据集长度(dataset的____len____方法实现)
-
确定抽样的indices(dataloader中的sampler和batchsampler实现)
-
取出一批批样本batch(dataset的____getitem___方法实现)
-
整理成features和labels(dataloader的collate_fn方法实现)
损失函数有哪些?
- 回归模型:通常使用nn.MSELoss
- 二分类模型:通常使用nn.BCELoss或者nn.BCEWithLogitsLoss
- 多分类模型:通常推荐使用nn.CrossEntropyLoss(y_pred未经过nn.softmax) == y_pred(经过softmax) + nn.NLLLoss
- nn.MSELoss(均方误差损失,也叫做L2损失,用于回归)
- nn.L1Loss (L1损失,也叫做绝对值误差损失,用于回归)
- nn.SmoothL1Loss (平滑L1损失,当输入在-1到1之间时,平滑为L2损失,用于回归)
- nn.BCELoss (二元交叉熵,用于二分类,输入已经过nn.Sigmoid激活,对不平衡数据集可以用weigths参数调整类别权重)
- nn.BCEWithLogitsLoss (二元交叉熵,用于二分类,输入未经过nn.Sigmoid激活)
- nn.CrossEntropyLoss (交叉熵,用于多分类,要求label为稀疏编码,输入未经过nn.Softmax激活,对不平衡数据集可以用weigths参数调整类别权重)
- nn.NLLLoss (负对数似然损失,用于多分类,要求label为稀疏编码,输入经过nn.LogSoftmax激活)
- nn.KLDivLoss (KL散度损失,也叫相对熵,等于交叉熵减去信息熵,用于标签为概率值的多分类,要求输入经过nn.LogSoftmax激活)
- nn.CosineSimilarity(余弦相似度,可用于多分类)
- nn.AdaptiveLogSoftmaxWithLoss (一种适合非常多类别且类别分布很不均衡的损失函数,会自适应地将多个小类别合成一个cluster)
Pytorch建模流程
- 准备数据
- 定义模型
- 训练模型
- 评估模型
- 使用模型
- 保存模型
编解码结构设计思想
在编码器中,引入池化层可以增加后续卷积层的感受野,并能使特征提取聚焦在重要信息中,降低背景干扰,有助于图像分类。然而,池化操作使位置信息大量流失,经过编码器提取出的特征不足以对像素进行精确的分割。这给解码器修复物体的细节造成了困难,使得在解码器中直接由上采样/反卷积层生成的分割图像较为粗糙,因此有人提出了建立快捷连接(unet)和aspp结构,使高分辨率的特征信息参与到后续解码环节,进而帮助解码器更好地复原目标地细节信息。
介绍一下yolov5
yolov5和v4都是在v3基础上改进的,性能与v4旗鼓相当,但从用户角度来说,易用性和工程性,v5更优。v5的原理可以分为四个部分:
- 输入端:针对小目标检测,沿用v4的mosaic增强,使用自适应锚框计算(将锚框的计算加入了训练的代码中)
- backbone:沿用v4的cspdarknet53结构,但是在图片输入之前加入Focus操作(v6.0换成6*6卷积)。在v5中,提供了四种不同大小的网络结构:s、m、l、x,通过depth和width两个参数控制
- neck:采用sppf + panet多尺度特征融合
- 输出端:沿用v3的head,使用GIOU损失进行边界框回归,输出还是三个部分:置信度、边框信息、分类信息。
RPN实现细节
一个特征图经过sliding window处理,得到256特征,对每个特征向量做两次全连接操作,一共得到2个分数(前景和背景分数),4个坐标(针对原图坐标的偏移)
交叉熵CE不适用于回归问题
当mse和交叉熵同时应用到多分类场景下时,mse对于每一个输出的结果都非常看重,而交叉熵只对正确分类的结果看重。

从上述公式中可以看出,交叉熵的损失函数只和分类正确的预测结果有关系,而mse的损失函数还和错误的分类有关系,该分类函数除了让正确的分类尽量变大,还会让错误的分类变得平均,但实际在分类问题这个调整没有必要。但是对于回归问题来说,这样的考虑就显得很重要了。
深度学习中优化学习方法(一阶、二阶)
- 一阶方法:随机梯度下降、动量、牛顿动量法(Nesterov动量)、adagrad(自适应梯度)、Rmsprop、adam
- 二阶方法:牛顿法、拟牛顿法、
- 自适应优化算法:adagrad、rmsprop、adam

深度学习为什么在计算机视觉领域这么好?
- 以目标检测为例,传统的计算机视觉方法首先基于经验手工提取特征,然后使用分类器分类,这两个过程都是分开的。
- 而深度学习中,使用cnn来实现对局部区域信息的提取,获得更高级的特征,当神经网络层数越多时,提取的特征会更抽象,将有助于分类,同时神经网络将提取特征和分类融合在一个结构中。
L1正则化和L2正则化有什么区别?
- L1:能产生稀疏性,导致w中许多项变为零。稀疏性除了在计算量的好处外,更重要的是更具有“可解释性”。(比如说,一个病如果依赖于 5 个变量的话,将会更易于医生理解、描述和总结规律,但是如果依赖于 5000 个变量的话,基本上就超出人肉可处理的范围了)
- L2:使得模型的解偏向于范数较小的W,通过限制解空间,从而在一定程度上避免了过拟合。
Python中生成器是什么?
生成器是一种创建迭代器的工具,它们和常规函数的区别是,在返回数据时使用yield语句。每当对它调用next函数,生成器从它上次停止的地方重新开始。
生成器和迭代器的区别
- 生成器本质上是一个函数,它记住了上一次返回时函数体的位置,生成器不仅仅记住了它的数据状态,也记住了它执行的位置。
- 迭代器是一种支持next操作的对象,它包含一组元素,执行next操作,返回其中一个元素,当所有元素都返回时,再执行则会报错
区别:
Python的传参是传值还是地址
- 实参为不可变参数,则用值传递
- 实参为可变参数,则引用传递
Python中的is和== 有什么区别?
is:比较两个对象的id值是否相等
==:比较的是两个对象的内容是否相等,默认会调用对象equal()方法
python 进程和线程
- 线程:是一个基本的cpu执行单元,它必须依托于进程存活。多线程的优点在于多个线程可以共享进程的内存空间,所以进程间的通信非常容易实现;但是如果使用官方的CPython解释器,多线程受制于GIL(全局解释器锁),并不能利用CPU的多核特性
- 进程:是指一个程序在给定数据集合上的一次执行过程,是系统分配内存的基本单位,每个进程启动时都会最先产生一个主线程,然后主线程会创建其他的子线程。使用多进程可以充分利用CPU的多核特性,但是进程间通信相对比较麻烦,需要使用IPC机制(管道、套接字等)
区别:
- 线程必须在某个进程中执行。
- 一个进程可包含多个进程,其中有且只有一个主线程。
- 多线程共享同个地址空间,打开的文件以及其他资源。
- 多进程共享物理内存、磁盘、打印机以及其他资源。
选择多线程还是多进程?
- CPU密集型:程序比较偏重于计算,需要经常使用CPU来运算。————————> 多进程
- I/O密集型:程序需要频繁进行输入输出操作。例如 :爬虫 ——————————> 多线程
os和sys模块的作用?
- os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口。
- sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行环境。
闭包
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称为闭包。
OSTU算法(大津法)
OSTU是一种用于二值化最佳阈值的选取方法,基本原理是根据阈值T将图像中的像素点分为C1和C2两类,不断调整阈值T之后,若此时两类之间存在最大类间方差,那么此阈值即是最佳阈值。
图像分割
图像分割有:基于阈值、基于区域、基于边缘、基于聚类、基于深度学习的图像分割方法等。
https://blog.csdn.net/m0_45447650/article/details/124398438
基本思想:假设图像中有明显的目标和背景,则其灰度直方图呈双峰分布,当灰度级直方图具有双峰特性,选取双峰之间的谷底对应的灰度值作为阈值。
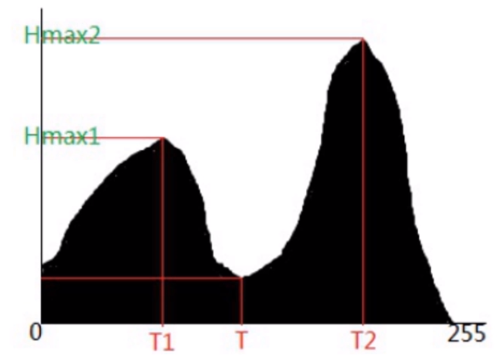
自动阈值法
- 自适应阈值法:对于简单的图像固定阈值法可以很好的分割,但是对于元素多,明暗变化不均匀的图像,固定阈值法就无法很好的进行分割
cv2.adaptiveThreshold(): 小区域阈值计算方式 1. 小区域内取均值 2. 小区域内加权求和,权重是个高斯核
- 迭代阈值分割:1. 求出图像的最大灰度值和最小灰度值 ,令初始阈值T0 = (最大灰度值+最小灰度值)/2 **2.**根据阈值将图像分割为前景和背景,分别计算前景和背景的平均灰度值(z1,z2) 3. 求出新的阈值 T1 = (z1 + z2)/2 4. 若T0 == T1,则所得即为阈值,否则转2,迭代计算 5. 使用计算后的阈值进行固定阈值分割
- otsu大津法:最大类间方差是一种基于全局阈值的自适应方法,即寻找一个阈值让前景和背景的类间方差最大化。
边缘检测

梯度方向和模计算

