文章目录
- 摘要
- 引言
- 基础知识
- Hypergraph Generation
- Distance-based hypergraph generation
- Representation-based hypergraph generation
- Attribute based hypergraph generation
- Network based hypergraph generation
- Comparison of hypergraph generation methods
- Dynamic Hypergraph Structure Learning
- Hypergraph Learning for Multi-Modal Data
摘要
超图学习是一种在超图结构上学习的方法。在本文中,我们首先系统重温了现有的超图生成方法,包括基于距离的,基于表示的,基于属性的和基于网络的方法。然后介绍超图上现存的学习方法包括transductive hypergraph learning, inductive hyper graph learning,超图结构更新以及多模态超图学习。
引言
超图是一种泛化的图结构,包含一组节点和超边。不同于简单图一条边包含两个节点,超边可以包含任意数量的节点。与只能建模对级连接关系的图结构相比,超图在建模复杂关系时具有显著优势。比如说,在一张超图中,节点表示研究者,超边表示多个作者共同署名的文章。这样,研究者之间合作关系越紧密,他们之间的超边就越多。
超图学习与图学习紧密相关,因为超图是一种泛化的图结构。类似于图学习,超图上的学习也可以看作在超图结构上的信息传播。从这个角度来说,图学习是超图学习的一个特例。不同于图学习,超图学习模型探索数据中的高阶关系,因此有更好的效果。
先前的超图学习方法有两个主要缺点。其一,构建的超图不是最优的,因此不能很好适配数据。其二,计算复杂度大,尤其当超图结构同时更新时,更为严重,很难扩展到大规模数据中。
基础知识
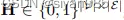
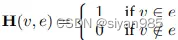
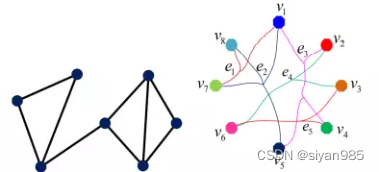
H(v,e)表示节点v是否存在于超边e中,W为超边权重。
超边e的度和节点v的度的定义
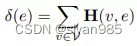
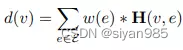
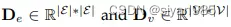
De,Dv为对角矩阵,分别表示超边和节点的度矩阵
超图的拉普拉斯矩阵为
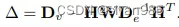
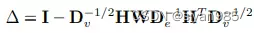
Hypergraph Generation
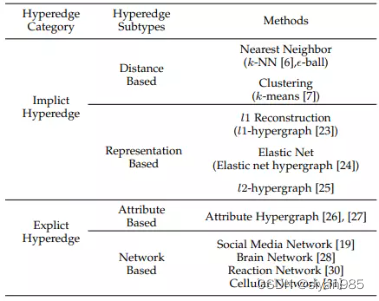
使用超图建模关系首先要从数据中构建超图。超图的质量直接影响关系建模的好坏。现有的超图生成方法主要分为四类即distance-based, representation-based, attributed-based和network-based方法。
Distance-based hypergraph generation
基于距离的超图生成方法是使用特征空间中的距离来建模节点之间的关系。主要的目标是在特征空间中找到邻居节点构成超边。常见的构建超边的方式有两种,最近邻居的搜索(a)和聚类(b)。
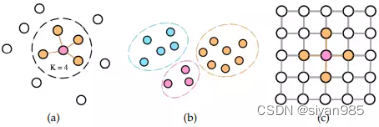
在基于最近邻居节点的方法中,超边的构建需要先为每个节点找到最近的邻居。对于每个节点,超边包含自己和在特征空间中最近的邻居节点。而邻居节点的数量k往往是提前定义好的。这种类型的超边包含着一组连接与同一节点的相似节点。
处理基于最近邻居的方法外,还有基于聚类的方法。通过在所有节点上使用聚类算法把节点分到不同的簇中。一条超边超边对应一个簇,簇中节点全连接。不同尺度的聚类算法可以用于生成多个超边。
在得到超边后,计算超边的权重或者置信度可以通过如下方法计算,其中σ可以用所有节点对间距离的中位数表示,d(.)表示节点对之间的距离。
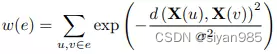
处理特征空间中的相似度外,位置信息也可以用于基于距离的超边生成方法中。每个节点可以直接原则空间相连的所有邻居构成一条超边。如©所示。
基于距离的构造方法主要的缺陷在于在一些场景下由于噪声或者离群点使距离是不精确的。还有就是超边的度的大小等。
Representation-based hypergraph generation
基于表示的超图生成方法是通过特征重构来建模节点间关系的。L1-hypergraph采用稀疏编码建模节点间的关系。具体来说,每个节点作为中心节点,然后用最近的邻居节点表示它即
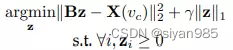
X(v)表示中心节点v的特征向量表示,B为k个最近的邻居的特征向量表示。zi表示第i个最近近邻样本学到的相关系数。基于这个表示,k个最近邻的样本中系数非零的样本构成超边。但是这种方法对系数重构误差比较敏感,不能处理非线性数据。
l2-hypergraph 通过把系数噪声从原始数据中分离出来并整合了局部性,保留了线性回归的约束条件。C是系数矩阵,E是数据误差矩阵,Q是局部适配器矩阵。
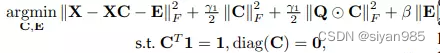
基于表示的超边构造方法可以评估每个节点在特征空间中的重构能力。但是和基于距离的构造方法类似,这些方法也会受到数据噪声和离群点的影响。还有就是基于表示的方法需要采样,只有部分相关的节点参与重构,因此生成的表示不能完全表示数据关系。
Attribute based hypergraph generation
基于属性的超图构造是使用属性信息来构建超图的。在基于属性的超图中的超边为视作一个团,超边的权重使用团内对级边的heat kernel权重的平均值即
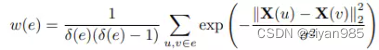
σ(e)表示超边的度。由于属性可以是分层的,可以得到不同尺度属性连接的超边。虽然属性信息有重要的作用但是并非在所有情况下都有属性信息可用。一种解决方法就是从现有数据中学习属性信息。
Network based hypergraph generation
在很多应用中,网络数据非常常见如社交网络,交互网络,分子网络和大脑网络。这些网络数据可以用于生成主观的关系。比如,在文献X中,节点表示用户和图像,超边包含同质和异质两种来捕获多类型关系。同质超边表示视觉和文本关系,使用最近邻居方法和基于属性的方法生成;异质超边使用用户和图像之间的社交关系构建。
除了一阶关系,还可以根据网络中的高阶关系构建超边。比如,在网络中,一个中心节点的一阶和高阶节点可以共同组成一条超边。
Comparison of hypergraph generation methods
四种超边生成方法可以进一步分为隐式和显式分类。隐式的超边在生成中不能直接通过原始数据获得,而需要度量方法和建立表示进行重构。因此,基于距离的方法和基于表示的方法属于隐式的。显式的超边可以利用原始数据的结构信息直接构建。因此,基于属性和基于网络的方法就是显式的,他们通过属性或者网络连接来构建超边的。
这些方法各有利弊。基于距离的方法直接,高效。但是对于相似度的计算方法和超参的设置非常敏感。基于表示的方法可以通过系数编码避免噪声点的影响但是在计算重构系数时引入了额外的计算量。基于属性的方法适合有明确属性的样本。这些属性可以在输入时给定或者手动定义或者自动生成。但该方法不能用于属性单一的情况。并且属性之间的关系也没有利用到。基于网络的方法非常适合图结构化的数据,可以使用确定的先验知识来构建超图。
一般情况下,给定一个具体的任务,可能会有一个最适合的超图生成方法。由于超图邻接关系的可扩展性,可以通过融合多个超图来创建一个复杂的超图。
Dynamic Hypergraph Structure Learning
不同于在静态的超图结构上学习,超图的动态结构更新是在学习过程中动态的调整超边的权重,节点的权重,和关联矩阵,学习建模的数据关系更加精确。
1)超边权重
超边权重用于显示不同超边的重要程度。根据超边的表达能力计算超边的权重非常重要,因为不同的超边在建模节点间连接时拥有不同的精确度。一个经典的方法是在学习节点标记向量的同时自适应的学习超边的权重。通过将权重之和设置为1,自适应的超边权重方法是一个双重优化问题表示如下
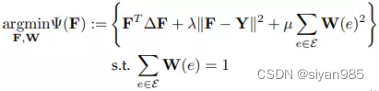
2)节点权重
在超图学习中,不同的节点重要性也不同。在一些工作中,节点的权重最初是按照训练样本每个类别的数据分布来计算的。然后,在该节点加权的超图上,标签向量与节点权重同时优化。
对于节点v,标签为label_v,d为节点到同类节点距离的平均数,则该节点的权重记作
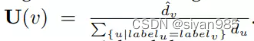
拉普拉斯矩阵为
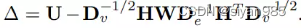
因此,学习任务可以表示为
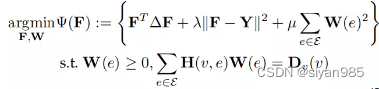
3)超图结构
超图结构学习就是优化关联矩阵。超图结构学习可以和标签预测在同一个框架中进行。文章Dynamic hypergraph在一个双重学习框架中联合学习标签向量和邻接矩阵。其目标函数如下
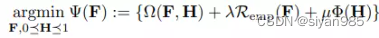
第一项为正则项,第二项为loss项,第三项为根据输入特征对关联矩阵H的约束。对于拥有共享相似特征的两个主体应该有更多更强的连接。一般把约束描述为
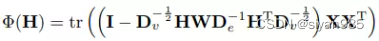
Hypergraph Learning for Multi-Modal Data
假设一个主体包含m个模态,可以把每个主体视作节点构建m个超图。为了达到全局的效果,需要为每个超图学习一个最优的权重系数来预测节点标签。
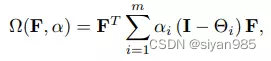
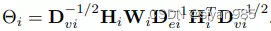
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)