文章地址:Messages Behind the Sound: Real-Time Hidden Acoustic Signal Capture with Smartphones
开头震惊,这篇 paper 的工作也太solid了吧,整目录就给👴整懵了
文章目录
- Insight
- 分段分析
- 1 Introduction
- 2 Background
- 2.1 Human Auditory System
- 2.2 Speaker and Smartphone Microphone
- 3 THE ACOUSTIC SPEAKER-MICROPHONE CHANNEL
- 3.1 Audio Time-Frequency Characteristics
- 3.2 Ambient Noise
- 3.3 Frequency Shift
- 3.4 Phase Shift
- 4 DOLPHIN DESIGN
- 4.1 System Overview
- 4.2 Signal Embedding
- 4.2.1 OFDM Signal Design
- 4.2.2 Energy Analysis
- 4.2.3 Adaptive Embedding
- 4.3 Signal Extraction
- 4.3.1 Preamble Detection
- 4.3.2 Channel Estimation
- 4.3.3 Symbol Extraction
- 4.4 Error Correction
- 4.4.1 Analysis of Data Errors
- 4.4.2 Orthogonal Error Correction
- 5 IMPLEMENTATION AND EVALUATION
- 5.1 Subjective Perception Assessment
- 5.1.1 Embedding Strength Coefficient β
- 5.1.2 Adaptive Embedding Improvement
- 5.2 Communication Performance
- 5.2.1 Decoding Rate and Throughput
- 5.2.2 Encoding and Decoding Time
- 5.2.3 Error Correction
- 5.2.4 Energy Consumption
- 5.3 Other Practical Considerations
- 5.3.1 Distance and Angle
- 5.3.2 Ambient Noise
- 5.3.3 Obstacles
- 5.3.4 Device Motion
- 5.3.5 Different Smartphone Models
- 6 RELATED WORK
- 7 CONCLUSIONS
- 收获
Insight
使用智能手机上的扬声器和麦克风来实现一个基于声音的双通道通信系统。
常用名词
composite audio :复合音频
unobtrusive: 不引人注目的
分段分析
1 Introduction
作者刚开始没讲声音通信,而是讲了一个当时流行的研究热点,那就是屏幕和摄像头之间的通信。
为什么会有 screen-camera communication 呢?
当前,社会环境中存在着大量拥有屏幕和扬声器的设备,并且在北美视频/音频流占据了高峰期网络带宽的70%。在这样的趋势下,我们希望屏幕和扬声器能够通过视频和音频向人类的智能设备传递更多有意义以及定制的内容。比如你在体育馆通过屏幕看球赛时球队信息能发送到你手机上。
目前我们看视频时,如果有新消息到来,会弹出一个弹窗,这会导致资源紧张并且影响用户体验。于是有些研究就希望设备能够一边向用户展示视频内容,一边悄悄地进行通信,最终实现实时的,不引人注目的摄像头与屏幕之间的通信。
(没懂这个 screen-camera communication到底是啥,同一部手机?手机屏幕在正面,摄像头在背面,这咋通信?)
按论文的说法,似乎是一种可见光通信,算了,不重要,先搁置
因为摄像头角度的问题,再加上智能设备的用户会随处走动,屏幕与摄像头间的通信有很大阻碍,于是作者就发明了基于声音的通信系统 Dolphin
Dolphin通过多路复用原始音频(面向人类听众)和嵌入式数据信号(面向智能手机)为扬声器生成复合音频。(把原本给人听的声音加点东西,使手机也能“听得懂”)
相比可见光,声音信号有如下优点:
(1)可以向任何方向传播,因此信号接收角度可以很大
(2)就算有障碍物,声音也可以通过衍射和反射传播
(3)声音频率在智能手机上很容易被分离,因此可以通过 OFDM 正交频分复用来提高吞吐量
Dolphin 的设计主要有三个挑战:
(1)信号的鲁棒性与声音质量之间存在一个 trade-off,嵌入式信号越强,抗干扰能力越强,但是对人耳来说就越弱
为了解决这个问题,作者提出了一个自适应的信号嵌入方法。嵌入信号的调制方法以及强度可以根据载波音频的能量特性进行自适应调整
(2)声音通信会受到手机硬件(比如对声音频率的分辨率)、声音信道的噪声干扰、多径干扰等限制。为了解决这些问题,作者对嵌入式信号使用了 OFDM,并且根据信道特性来决定系统参数。不仅如此,作者还使用了一种基于“hybrid-type pilot arrangement”的技术来进行信道估计,这可以将 "frequency-time selective fading"和 "Doppler frequency offset"的影响最小化。
(3)不同的环境导致不同的 bit error rate,为了提升系统可靠性,作者设计了一个“双层正交误差校正”方案
作者说自己的贡献主要有三个:
(1)提出了 Dolphin 这种声音通信系统
(2)提出了一种基于 OFDM 和载波音频信号能量分析的自适应嵌入式方法。
(3)制作了 Dolphin 的样品,并实验证明它有用
2 Background
第二部分介绍Dolphin需要的人类视听系统的一些特性
2.1 Human Auditory System
人耳主要有两个功能:
(1)感知声音强度以及坠落感
(2)masking effects
什么是 masking effects?
(1)同频率声音,强度大的会掩盖强度小的
(2)不同频率声音,低频率的会掩盖高频率的
人耳能听到的声音频率在 20 ∼ 18000Hz
2.2 Speaker and Smartphone Microphone
大多数扬声器和麦克风的接收频率在 50 to 20000Hz,这两种设备都存在 frequency selectivity,性能在高频声音下退化显著,人耳也是在高频段下听不见,二者重合了,因此在人类注意不到的情况下开辟第二声音信道不是一件容易的事。
3 THE ACOUSTIC SPEAKER-MICROPHONE CHANNEL
Dolphin 的成功主要依靠 the acoustic speaker-microphone channel 的特性,因此作者做了大量实验来理解这种信道的特性。
3.1 Audio Time-Frequency Characteristics

从上到下依次是 人声、轻音乐、摇滚乐的时域与频域特性。
人声在时域上是断断续续的,因为人说话有停顿。
摇滚乐在频域上的能量分布显著宽于人声和轻音乐
3.2 Ambient Noise
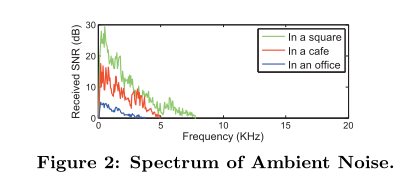
这是在一部三星Note4手机上测得的不同环境下的噪声。
3.3 Frequency Shift
多普勒效应公式:
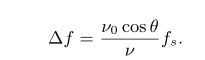
fs 是信号载波的频率(也就是声音);
θ
\theta
θ 是智能手机运动方向与 扬声器之间的角度(这里的扬声器是另一部手机上的,是信号源,默认相对静止;智能手机是信号接收者,相对扬声器运动);
v0 是智能手机运动的速度,即信号接收方运动的速度;
Δ
\Delta
Δf 是接收到的信号相对于发出的信号的频率偏移
在 OFDM 系统中多普勒效应会更加严重
3.4 Phase Shift
当前,手机扬声器和麦克风的最大采样频率为 44.1KHZ,对于一个10KHZ的正弦波来说,在这样的采样频率下一个周期就只能采4个点
怎么算?
每 1/44.1K 秒采样一次,频率10KHZ的信号一个周期 1/10K 秒,那么一个周期也就最多采4个
根据奈奎斯特采样定律,采样频率至少是被采样信号两倍,也就是说一个周期至少能采两个点,而现实中一般都会是4-5倍
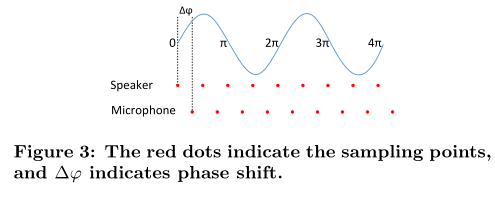
如上图所示,对于10KHZ的信号来说,4个点一个2
π
\pi
π周期,那么因为发送端与接收端不同步问题,偏一个点就会造成
π
\pi
π/2的相移,而常用的一些方法会偏移5个点,因此PSK调制不适合Dolphin
4 DOLPHIN DESIGN
4.1 System Overview
Dolphin 的系统结构如下所示:

在发送端,首先根据Data Bits 的 packets的能量分布分析来选择子载波调制方法,然后对Original Audio的每个symbol作能量分析,如果symbol的能量足够 mask 嵌入信号,那就根据能量特性嵌入信号,如果不足够mask,就不嵌入。
(猜测论文中的一个 part 就是一个 symbol)
在接收端,可以通过检测包头精确分割每个symbol,因为传输过程中存在衰减,为了不影响decoding rate,在提取 symbol前先做一个 channel estimation
4.2 Signal Embedding
这一大节介绍发送端信号嵌入的详细过程
4.2.1 OFDM Signal Design
这一小节介绍基于声音信道特性的OFDM实现过程
(1)选择带宽
手机设备的接收频率在 50HZ-20KHZ
前面有说过环境造影在 8KHZ 之上可以忽略,同时,还有文献证明 17-20KHZ之间的频率人耳几乎不能听到,最后为了提高吞吐量,作者选用 8-20KHZ作为嵌入数据的带宽
(复习:不同频率,低频率信号可以 mask 高频率信号)
(2)symbol 载波调制
之前说过因为相移严重所以PSK不适合,又因为OFDM系统中载波频率范围有限,所以FSK也不适合,所以作者采用ASK调制。
因为同一频率强度越低越能被mask,所以对于embedded data作者采用ASK中的特例OOK(0, 1两种),如下所示:

ASK的一个缺点是原始音频在 embedded data 的带宽中的能量必须非常低,因此作者先将原始音频在此带宽中的能量消除后才开始嵌入数据。为了使人耳听不到嵌入的数据,作者将带宽限制在 14-20KHZ,因此原始音频在14KHZ以上的能量全部被砍掉。
如果原始音频在8KHZ以上的能量相对来说比较高,那么就选用 EDK调制(Energy difference keying)
EDK 可以在载波中心频率周围调整能量分布。其执行流程没看懂,反正用EDK调制不用 cut off 原音频能量
(3)Dolphin packet format
将embedded data 划分为 packets,packet的组成如下所示:
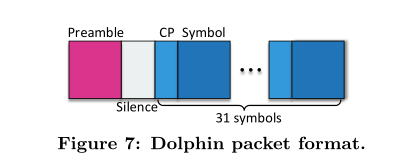
每个 packet 由 一个 报头 和 31 个 symbol 组成,每个symbol前都有一个循环前缀 CP
报头用来同步packet,symbol是 data bits
作者参照航空声学通信系统,使用一种叫 chirp signal 的信号来作为 报头,这种信号的特性如下:
Its frequency ranges from fminto fmaxin the first half of the
duration and then decreases back to fminin the second half.
在本paper中, fmax 为19KHZ, fmin为 17KHZ,duration 为 100ms。因为报头的能量很高,作者在报头后填充了50ms沉默期以免影响报文
如下所示,embedded signal的一个symbol 由时域变换为频域,在14KHZ-19.9KHZ范围内用60个载波来编码 data bits。20KHZ的信号作为导频,用于时间选择性衰弱和多普勒频偏。
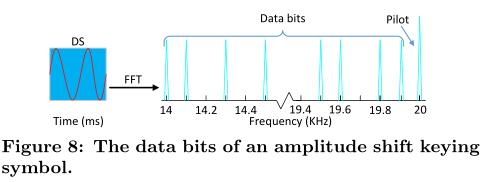
经作者实验,对于每个symbol来说,100ms的duration和60的子载波数量正好在 鲁棒性与吞吐量之间做了一个trade-off
在 RF OFDM radios 中,循环前缀CP用来解决码间串扰与载波间串扰。CP从本symbol的前一个symbol的末尾复制了一定的长度,CP的duration 为 10ms.
4.2.2 Energy Analysis
公式就不说了,作者根据 data 的能量分布在每个报头插入了一个19.6KHZ的控制信号,用来指示使用的调制方式
因为语音信号是断断续续的,所以如果在停顿出插入 embedded data,那么用户就容易察觉到,所以作者以symbol为单位也对原始音频作了能量分析,低能量的音频段就不嵌入Data bits
receiver 只需要检测 20KHZ 的导频就可以知道这一段音频是否嵌入了 data bits,可以节省资源
4.2.3 Adaptive Embedding
当原始音频强度高时,embedded signal 的强度也高,反之,原始音频强度 低时,embedded signal的强度也低。
具体公式见论文
4.3 Signal Extraction
4.3.1 Preamble Detection
作者通过包络检测来识别 preamble chirp signals
在实际中,因为 “the ringing and rise time ”,在接收端包络之间挨得很近,会导致5个采样点之内的同步错误,在Dolphin中,每个symbol对应 4410个采样点,因此5个采样点的误差可以忽略不计。
4.3.2 Channel Estimation
在 symbol extraction之前,作者使用基于 pilot arrangement 的信道估计技术
(1)Choosing the type of pilot:选择导频种类
pilot (导频)有两种,block-type pilot 和 comb-type pilot

图里是一个symbol
一个圆圈是一个采样点
横着看一排是一个子载波,每一排子载波代表一种频率
block-type pilot 是给symbol的每个子载波都插入导频,在假设信道传递函数变化不是很快的情况下,它在估计频率选择性衰落信道中是有效的;
Comb-type pilot只给symbol中特定的子载波插入导频(这个特定频率的子载波在全时域范围内都是导频),它对于估计每个符号的时间选择性衰落和多普勒频偏有效,因此适用于时变信道
因为在 speaker-microphone 系统中,频率选择性衰落和多普勒效应都很严重,所以作者选择 a hybrid-type pilot arrangement,即除了在每个子载波中设置导频外,还在每个symbol的20KHZ处设置附加导频
(2)Estimating channel transform function
作者使用最小二乘估计来进行 real-time signal extraction
接下来就是通过公式推导来解释是如何通过信道传递函数评估来消除频率选择性、时域选择性以及多普勒频偏的
没看懂
4.3.3 Symbol Extraction
通过长度为子载波带宽的 data window 来提取嵌入信号
4.4 Error Correction
4.4.1 Analysis of Data Errors
如下图所示是一个 packet 经过重复实验得到的误差分布

可见大多数symbols经过测试,出错比特数都不超过3个,并且误差分布比较随机,很可能是由噪声引起的,而不是speaker-microphone系统的频率选择性。因此,少量的冗余纠错码即可纠正所有的错误。
有些symbol 错误比特数超过10,这应该是多径干扰引起的,需要使用 excessive coding(???)来解决
这一小节是作为接下来使用OEC的实验分析依据
4.4.2 Orthogonal Error Correction
OEC 是在 time 和 space 两个维度上,包含了 intra-symbol error correction (符号内纠错)和inter-symbol erasure correction(符号间擦除校正)
(1)Intra-symbol error correction
关注由噪声引起的错误
使用一种叫 Reed-Solomon (RS) codes 的技术
(2)Inter-symbol erasure correction
这是为了纠正极少数 symbol 会产生的大量错误,这是 RS code无法解决的
通过其他误差小的 symbol来纠正误差大的 symbol
5 IMPLEMENTATION AND EVALUATION
进入实物制作部分
sender 由PC端的扬声器实现
receiver 由不同手机的安卓APP实现
实验设置:
sender: DELL Inspiron 3647 with 2.9 GHz CPU and 8 GB memory controlling a HiVi M200MKIII loudspeaker
默认发送音量:80dB
默认间隔距离:1m
receiver: Galaxy Note4
sampling rate: 44.1KZH
5.1 Subjective Perception Assessment
为了获得一组良好的系统设计参数
作者进行了一组用户实验,请了一组志愿者以检测人们对嵌入信号的感知
5.1.1 Embedding Strength Coefficient β
The embedding strength coefficient(嵌入强度系数) β 是最重要的参数
β
\beta
β越大,系统越可靠,但是用户越能感知到音频的变化
为了作对比试验,作者使用ASK进行了静态嵌入,即嵌入信号能量不随载波能量而调整,其结果如下所示

其中,subjective pereption score 越高说明越不容易被用户察觉
如图所示, 在静态嵌入中,
β
\beta
β越大,分数越低,基本上
β
\beta
β大于0.3用户就能察觉到了
5.1.2 Adaptive Embedding Improvement
使用自适应嵌入的得分如下所示:

可见明显的提升
就算是使用自适应嵌入,
β
\beta
β也不要超过0.5
5.2 Communication Performance
这一大节基于不同的标准来评估 Dolphin
5.2.1 Decoding Rate and Throughput
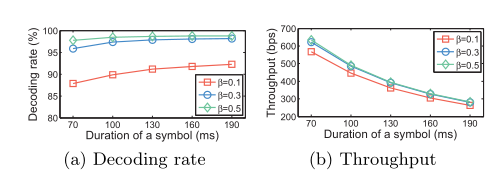
decoding rate(解码率) 和 throughput(吞吐量) 主要取决于两个参数:the symbol duration T(符号持续时间) and the number of subcarriers N(子载波数目)
作者将 T设为100ms,将N设为60
下图展示了T的变化相对于 decoding rate 和 throughput的影响,可见,T与 decodign rate 成正比例关系,与 throughput成反比例关系
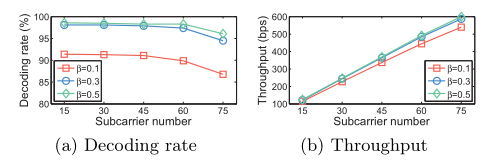
下图展示了 N 对于 decoding rate 和 throughput的影响,可见,与 T 相反,N 同 decoding rate 成反比关系,同 throughput成正比关系
5.2.2 Encoding and Decoding Time
作者评估了每个symbol的编码和解码时间,以检验 Dolphin的实时通信能力。
编码时间如下所示:
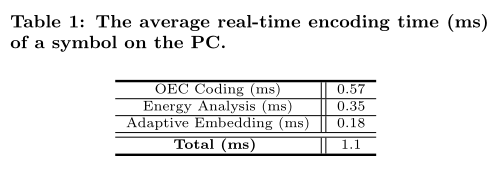
可见,编码时间远小于 duration time,所以完成能够实现实时通信
解码时间如下所示:

对于 symbol 来说也是小于 duration time
但是可以看到 报头检测花了远大于 duration time的时间,这是因为存在循环迭代操作,但是没有关系每隔一个 packet,也就是很多 symbols才会有一点延时
5.2.3 Error Correction
检验不同通信距离下的误码率
 goodput定义为正确解码的数据位(不包括用于纠错的位)与总传输时间的比率
goodput定义为正确解码的数据位(不包括用于纠错的位)与总传输时间的比率
可见距离越大,goodput越低
5.2.4 Energy Consumption
如下图所示,作者测试了两种幸好的智能机,都能支持Dolphin连续收发超过4小时

5.3 Other Practical Considerations
这一部分在不适用 OEC 前提下评估其他实际因素对系统性能的影响
5.3.1 Distance and Angle
distance 对于 decoding rate 来说非常重要,因为音频能量是随着距离的平方而衰减的,如下图所示:

作者还测试了手机的角度对decoding rate 的影响,角度变化有两种:垂直旋转和水平旋转
结果如下所示:

可见,垂直旋转对系统影响不大,水平旋转超过一定角度后下降明显,但这是因为选用的 HiVi M200MKIII 音箱发出的声音是有方向性的。
可见 Dolphin 是可靠的
5.3.2 Ambient Noise
如下图所示,展示了环境噪音对于 decoding rate 的影响。
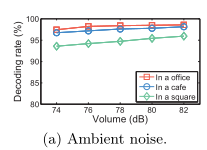
可见,Dolphin 对于环境噪声的抗干扰性很强,decoding rate 都在 90% 以上,Square 的效果较差是因为室外会有很多高频噪音源,不像室内多是人声。
5.3.3 Obstacles
如果声源和接收器麦克风之间存在障碍物是否会有影响?
如下图所示:
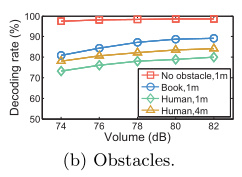
有障碍物的话确实会明显影响 decoding rate,障碍物越大,decoding rate 越低
同时作者发现,因为 HiVi M200MKIII speaker 存在方向性传输,如果障碍物离音箱很近,那么声波就会被完全挡住,因此 Dolphin 在拥有更宽的传输角度的 speaker 下会发挥得更好。
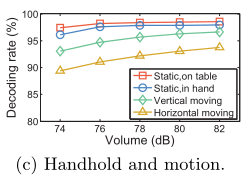
5.3.4 Device Motion
如下图,可见水平移动伤害最大
5.3.5 Different Smartphone Models
使用4部智能机来探究不同手机对于系统的影响。结果如下所示:
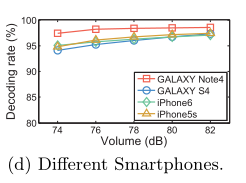
差距主要是由麦克风的频率选择性造成的,音量越大,decoding rate 越高,这是因为在每个 packet 的第一个symbol有导频,会大幅减轻频率选择性衰减
6 RELATED WORK
这一部分作者介绍了在
Unobtrusive screen-camera communication、Aerial acoustic communication、Audio watermarking这三个领域的重要工作
7 CONCLUSIONS
重复说了 Introduction 中提到的那几个贡献
收获
读了这篇paper主要明白了:
(1)声音通信是什么?
将要传输的信号嵌入正常的语音中进行传输,同时被嵌入的载波音频不能使人耳察觉到发生了变化。
(2)一篇关于新系统的文章应该要包含哪些工作?
首先是背景知识介绍;然后是系统设计细节,尤其要说明这个系统是如何解决可能会出现的各种针对编解码的干扰的;最后要详细评估这个系统的可靠性与精读。
(3)就一个声音通信系统来说,对于频率的把控很重要
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)