首先,如果使用GPU,确认你电脑的有关环境是否符合以下要求:
- CMake >= 3.12
- CUDA >= 10.0
- OpenCV >= 2.4
- cuDNN >= 7.0
- GPU with CC >= 3.0
不知道具体的版本号也没关系,如果不符和,在代码运行时会提示的,到时候根据错误提示调整对应的版本就可以了。
目录
第一步:下载GitHub源码并编译测试。
第二步:修改/创建有关文件,训练自己的数据集
第一步:下载GitHub源码并编译测试。
首先创建一个存放YOLOv4代码的文件夹,cd到该文件夹下。如,我在/home/(用户名)/RoboGroup文件夹下创建了一个yolo4文件夹,然后在该文件夹中右键选择“Open in Terminal”,打开终端,输入以下命令,从GitHub上下载darknet源码:
git clone https://github.com/AlexeyAB/darknet.git
下载之后,在该文件夹下会多出一个darknet文件夹,如下:
(小白指路:文件管理器中左边栏的Home文件夹其实就是/home/(用户名),例如,如果你的用户名叫hhh,则Home=/home/hhh。你可以依次点击Other Location -> Computer -> home -> (你的用户名) 看一下)
开始编译darkent文件。首先双击进入上述darknet文件夹,如果配置好了GPU和OpenCV环境,则修改Makefile文件相关内容如下:
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1
保存后在darknet文件夹下,右键点击“Open in Terminal”,输入make,则开始darknet的编译,中间会出现warning信息,不用理会。编译完成后,在终端输入./darknet,如果出现usage: ./darknet <function>,则说明编译成功。然后下载官方给出的权重文件yolov4.weight进行测试,下载的权重文件放到darknet主目录下就可以。然后执行如下命令:
./darknet detect cfg/yolov4.cfg yolov4.weights data/person.jpg
该命令使用训练好的权重检测示例图片,效果如下:

至此,测试阶段就完成了,下面是训练自己的数据集。
第二步:修改/创建有关文件,训练自己的数据集
step1:首先在darknet/cfg文件夹下创建自己的cfg文件(cfg文件定义了网络的模型及参数),这里我命名为my.cfg(如何命名甚至放哪里都无所谓,只要记得你的cfg文件的位置和叫啥名就行) ,然后将cfg文件夹下的yolov4-custom.cfg文件内容复制到my.cfg中(你不创建新的cfg文件,直接修改yolov4-custom.cfg文件也可以),然后根据自己的数据集来修改里面的内容,都要改些啥那?关于cfg文件中参数的意义,请参考这里。
- 更改batch=64、subdivision=16。但是,具体的值要根据GPU容量来改,例如我就只能设置batch=8、subdivision=8了。
- 更改max_batches=classes*2000。max_batches其实就是整个训练过程的迭代次数,跑完一个batch算一次。classes*2000是官方给出的值,例如我的数据集有两个类别,所以我的max_batches最好设置为4000,为什么最好那?因为你也可以设为别的数,比如3000或者6000。
- 设置steps值分别为80%*max_batches和90%*max_batches。这也是个经验性的设置值,用以控制什么时候学习率衰减。
- 设置width=416、height=416或者任意32的整数倍的值。我给的608。
- 改变每个[yolo]层(三个yolo层,所以共有三处)的classes值为你的类别数,我有俩类别,所以就是2
- 改变每个[yolo]层前面一层的filters参数,值为(classes + 5)x3,我这里就是21。同样也是需要改三处。如果用到了[Gaussian_yolo],其前面的filters值也要做同样的修改,我这里没用就不用管了,代码里默认没用。
step2:修改完你的.cfg文件后,下一步就是创建obj.name文件(同样的,只要你记得你的文件名和位置,无所谓在哪里创建或者叫什么),这里我在darknet/data文件夹下创建该文件,内容格式如下:
urchin
trepang
然后在该文件夹下继续创建obj.data文件,内容如下,当然,内容要根据自己的文件位置及文件名修改。这里提到的两个txt文件以及.name文件会在后面的步骤中生成,backup代表训练好的模型存放的位置。
classes = 2
train = data/2020_train.txt
valid = data/2020_test.txt
names = data/obj.names
backup = backup/
step3:VOC数据集的文件格式如下,这是个习惯性的格式。具体的文件名可以自己定义,后面的代码啥的也做相应的修改就不影响模型的训练。这里要注意:yolov4的数据集跟这个区别较大,但构建数据集的时候还会用到这个格式的文件,后面会讲到。
└── VOCdevkit
└── VOC2012
├── Annotations
├── ImageSets
│ ├── Main
├── JPEGImages
之后在darknet/data文件夹下创建obj文件夹,将你数据集里的图片全部复制进来。
然后是创建train.txt及val.txt文件。这两个文件是将数据集划分成训练集和验证集的文件,也是创建创建我的2020_train.txt、2020_val.txt的中间文件,Python代码如下,需要根据自己的实际情况做适当修改,生成的文件将会保存到上述的Main文件夹中。
注:这里的VOCdevkit2020是我自定义的自己的VOC数据集。
import os
from os import listdir
if __name__ == '__main__':
source_folder =r'VOCdevkit2020/VOC2020/JPEGImages'
dest = r'VOCdevkit2020/VOC2020/ImageSets/Main/train.txt'
dest2 = r'VOCdevkit2020/VOC2020/ImageSets/Main/val.txt'
file_list = os.listdir(source_folder)
train_file = open(dest, 'w')
val_file = open(dest2, 'w')
i=0
for file_obj in file_list:
file_name, file_extend = os.path.splitext(file_obj)
if (i%4 ==0):
val_file.write(file_name + '\n')
else:
train_file.write(file_name + '\n')
i+=1
train_file.close()
val_file.close()
step4:之后生成2020_train.txt、2020_val.txt文件。这两个文件就是训练时要用的文件,包含了训练和验证数据集中图片的位置等信息。可以使用darknet/scripts/voc_label.py文件生成,文件内容要做适当的修改。我根据自己的有关文件配置,修改如下:主要是sets、class以及文件名和路径的修改。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2020', 'train'), ('2020', 'val'), ('2020', 'test')]
classes = ["urchin", "trepang"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit2020/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit2020/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit2020/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit2020/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit2020/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('../data/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit2020/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
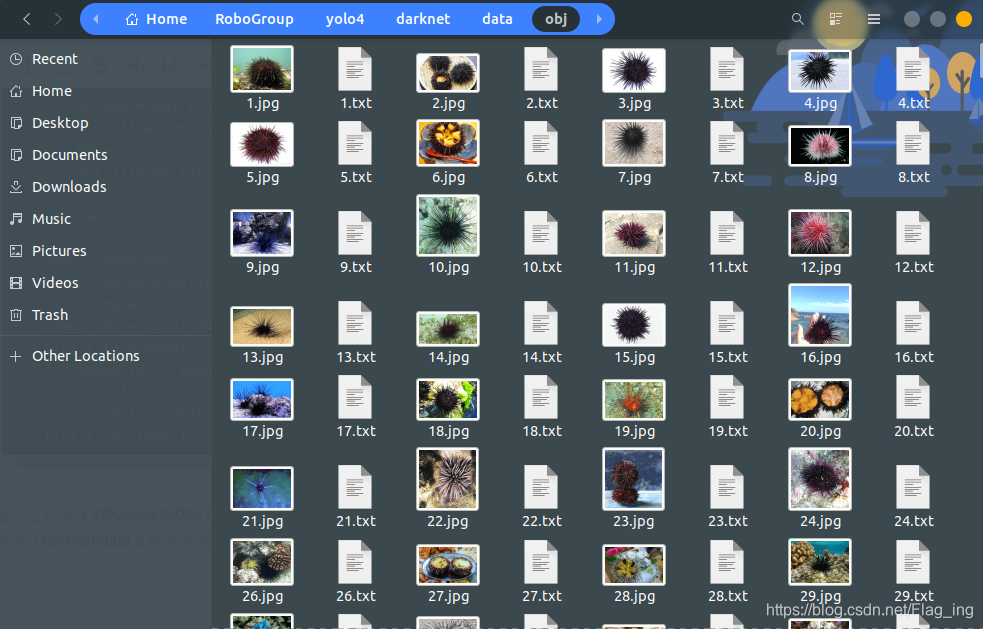
运行之后会在VOCdevkit2020文件夹中生成labels文件夹,将里面的内容(所有txt文件)复制到之前创建的data/obj文件夹中,每个txt文件对应着相应的JPG图片的groundtruth信息,如下。然后还会在darknet/data文件夹下生成2020_test.txt、2020_train.txt、2020_val.txt三个文件。在这里就清楚YOLOv4的数据集格式了吧,就是下图所示的格式!
step5:做好了这些,下步就是下载预训练权重文件yolov4.conv.137,下载好后放在darknet文件夹下就可以了。
step6:最后一步就是训练模型了。cd 到darknet文件夹下,在终端输入如下指令:
./darknet detector train data/obj.data cfg/my.cfg yolov4.conv.137
这里要注意把obj.data文件以及my.cfg文件的路径写对,根据自己文件所在的位置来写。
step7:训练完成后,来输入以下命令坐下测试:
./darknet detector test data/obj.data cfg/my.cfg backup/my_last.weights -thresh 0.95 data/test1.jpg

同样的,具体的路径名要根据自己的实际情况来填写
参考:https://github.com/AlexeyAB/darknet#geforce-rtx-2080-ti
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)