摘要
修剪神经网络的参数可以在训练和测试期间节省时间、内存和能量。最近的研究发现,通过一系列昂贵的训练和修剪周期,初始化时存在中奖彩票或稀疏可训练的子网络。这就提出一个基本问题:我们能否在初始化时识别出高度稀疏的可训练的子网络,而不需要训练,或者实际上不需要查看数据。答案是肯定的,该文章首先在数学上制定并实验验证了一个守恒定律,该定律解释了为什么现有的基于梯度的修剪算法在初始化时会出现层塌,整个层的过早修剪使网络不可训练。该理论还阐明了如何完全避免层塌,激发了一种新的剪枝算法迭代突触流剪枝(SynFlow)。该算法可以解释为在初始化时,受稀疏性约束,保持网络中突触强度的总流。值得注意的是,该算法不参考训练数据,并且在初始化一系列模型(VGG和ResNet)、数据集(CIFAR-10/100和Tiny ImageNet)和稀疏性约束(高达99.99%)时,始终与现有的最先进的修剪算法竞争或优于它们。因此,我们的数据不可知修剪算法挑战了现有的范式,在初始化时,必须使用数据来量化哪些突触是重要的。
引言
我们的目标是在初始化时识别出高度稀疏的可训练的子网络,而不需要训练、甚至不需要查看数据。为了实现这一目标,该文首先研究了现有剪枝算法(SNIP,Grasp)在初始化时的局限性,确定了避免这些限制的简单策略,并提供了一种新的数据不可知算法、实现了最先进的结果。该文章的主要贡献有:
1.研究了层塌,对整个层的过早修剪使网络不可训练、并制定了最大临界压缩公理,假定修剪算法应该尽可能避免层塌。
2.从理论和经验上证明,突触显著性,一种基于梯度的修剪分数的一般类别,在神经网络的每个隐藏单元和层上是保守的。
3.表明了这些守恒定律意味着大层中的参数比小层中的参数获得更低的分数,这说明了为什么单次修剪不成比例的修剪最大的层,导致层塌。
4.假设迭代幅度修剪可以避免层塌,因为梯度下降有效地鼓励幅度分数遵守守恒定律,这与迭代结果相结合,在修剪期间最大层的相对分数增加。
5.证明了一个剪枝算法完全避免层塌,并满足最大临界压缩,如果它使用迭代,积极的突触显著性分数。
6.介绍了一种新的数据不确定算法迭代突触流剪枝(SynFlow),它满足最大临界压缩,并实证证明该算法在12个不同的模型和数据集组合上实现了最先进的剪枝性能。
一、层崩溃:初始化剪枝的关键障碍
初始化剪枝算法由两个步骤定义。第一步根据某种度量对网络参数进行评分,第二步根据评分对参数进行屏蔽(删除或保留参数)。最近的工作已经确定了现有的使用全局掩蔽的剪枝算法的一个关键失效模式——层塌缩。当算法删除单个权重层中的所有参数时,即使可修剪的参数仍然存在于网络的其他地方,也会发生层塌,这使得网络不可训练,精度突然下降。
压缩比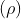 是原始网络中的参数数量除以修剪后剩余的参数数量。当压缩比
是原始网络中的参数数量除以修剪后剩余的参数数量。当压缩比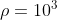 时,在修剪后只有千分之一的参数保留。最大压缩比
时,在修剪后只有千分之一的参数保留。最大压缩比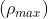 是不会导致层崩溃的网络的最大可能压缩比。例如对于一个具有L层和N个参数的网络,
是不会导致层崩溃的网络的最大可能压缩比。例如对于一个具有L层和N个参数的网络,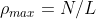 ,这是与每层除一个参数外的所有参数修剪相关的压缩比,临界压缩
,这是与每层除一个参数外的所有参数修剪相关的压缩比,临界压缩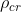 是一个给定算法在不引起层塌的情况下所能达到的最大压缩比,特别的,算法的临界压缩始终是网络的最大压缩上界:
是一个给定算法在不引起层塌的情况下所能达到的最大压缩比,特别的,算法的临界压缩始终是网络的最大压缩上界: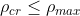 ,这个不等式激发了以下公理,我们假设任何成功的算法都应该满足:
,这个不等式激发了以下公理,我们假设任何成功的算法都应该满足:
公理最大临界压缩。应用于网络的剪枝算法的临界压缩应该始终等于该网络的最大压缩。
这个公理意味着,如果存在另一组相同的基数,可以保持网络可训练,那么修剪算法永远不应该修剪一组导致层崩溃的参数,当然、任何剪枝算法都可以通过引入专门的分层剪枝率来满足这个公理,但是为了保留全局屏蔽的好处,我们制定了一种算法,迭代突触修剪(SynFlow),它通过构造满足这一特性。SynFlow是幅度修剪的自然延伸,它保留了从输入到输出的突触强度的总流,而不是单个突触强度本身。
二、突触显著性的守恒定律
理解为什么某些评分指标会导致层塌,对于改进修剪算法的设计至关重要。
假设一个层内基于梯度的平均分数与层大小成反比,通过构建基于流网络的理论框架来检验这一假设,我们首先定义了一类基于梯度的分数,证明了这些分数的守恒定律,然后用这个定律证明了我们的层大小与平均分数反比的假设完全成立。
一类基于梯度的分数。突触显著性是一类得分指标,可以用哈达玛乘积表示:
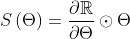
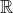 是前馈网络参数为
是前馈网络参数为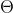 输出y的标量损失函数,当为训练损失
输出y的标量损失函数,当为训练损失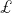 时,得到的突触显著性度量值等价于
时,得到的突触显著性度量值等价于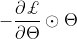 ,这个度量和SNIP的
,这个度量和SNIP的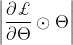 ,Grasp的
,Grasp的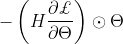 相似。这种评分指标的一般类别,虽然不包括,但暴露了用于修剪的基于梯度的评分的关键属性。
相似。这种评分指标的一般类别,虽然不包括,但暴露了用于修剪的基于梯度的评分的关键属性。
突触显著性的守恒。所有的突触显著性指标都尊重两个惊人的守恒定律,在任何初始化和训练步骤中都成立。
定理1.突触显著性的神经元守恒
对于一个连续齐次激活函数的的前馈神经网络,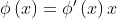 ,传入参数
,传入参数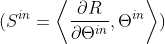 (包括偏置)到隐藏神经元的突触显著性之和等于来自隐藏神经元的传出参数
(包括偏置)到隐藏神经元的突触显著性之和等于来自隐藏神经元的传出参数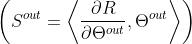 的突触显著性之和。
的突触显著性之和。
定理2.突触显著性的网络守恒
在前馈神经网络中,具有齐次激活函数的输入神经元x和输出神经元y之间的任意一组参数的突触显著性之和相等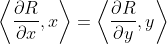
当考虑一个带有偏差的简单前馈网络时,这些守恒定律暗示了非平凡关系:![\left \langle \frac{\partial R}{\partial W^{[l]}},W^{l} \right \rangle+\sum _{i=1}^{L}\left \langle \frac{\partial R}{\partial b[i]},b^{[i]} \right \rangle=\left \langle \frac{\partial R}{\partial y},y \right \rangle](https://latex.codecogs.com/gif.latex?%5Cleft%20%5Clangle%20%5Cfrac%7B%5Cpartial%20R%7D%7B%5Cpartial%20W%5E%7B%5Bl%5D%7D%7D%2CW%5E%7Bl%7D%20%5Cright%20%5Crangle+%5Csum%20_%7Bi%3D1%7D%5E%7BL%7D%5Cleft%20%5Clangle%20%5Cfrac%7B%5Cpartial%20R%7D%7B%5Cpartial%20b%5Bi%5D%7D%2Cb%5E%7B%5Bi%5D%7D%20%5Cright%20%5Crangle%3D%5Cleft%20%5Clangle%20%5Cfrac%7B%5Cpartial%20R%7D%7B%5Cpartial%20y%7D%2Cy%20%5Cright%20%5Crangle)
保存和单发修剪导致层塌。突触显著性的守恒定律为我们提供了理论工具来验证我们之前的假设,即层大小和平均层分数成反比是导致基于梯度的修剪方法层塌的根本原因。考虑一个简单的,完全连接的神经网络的一层中的参数集。这个集合可以准确地将输入神经元和输出神经元分开。因此,通过突触显著性的网络守恒,该集合的总分对于所有层都是固定的,这意味着平均值与层大小成反比,通过计算模型每一层的总分,我们可以对现有剪枝方法在规模上这种关系进行经验评估,虽然这种反向关系对于突触显著性是准确的,但其他密切相关的基于梯度的分数,如在SNIP和Grasp中使用的分数,也尊重这种关系。这验证了经验观察,对于给定的压缩比,基于梯度的修剪方法将不成比例地修剪最大的层,因此,如果压缩比足够大,并且只评估一次修剪分数,那么基于梯度的修剪方法将完全修剪最大的层,导致层塌。
三、量级修剪通过守恒和迭代避免层塌
迭代剪枝(Iterative Magnitude Pruning,IMP)是最近提出的一种剪枝方法,该方法似乎完全避免了层塌这个问题,该算法遵循三个简单步骤,首先训练一个网络,其次修剪最小值的参数,第三将未修剪的参数重置为初始化,重复直到所需的压缩比。虽然简单而强大,但IMP是不切实际的,因为它涉及多次训练网络,基本上违背了构建稀疏初始化的目的。
如果没有足够的修剪迭代,IMP将遭受层塌,仅凭修剪迭代的次数并不能解释IMP在避免层崩溃方面的成功,请注意,如果IMP在每个修剪周期中都没有训练网络,那么,无论修剪迭代的次数是多少,它都相当于单次修剪。因此,在训练过程中,参数的大小必须发生一些非常关键的事情,当与足够的修剪迭代相结合时,允许IMP避免层崩溃,我们假设,梯度下降训练有效地鼓励分数遵守一个近似的分层守恒定律,当与足够的修剪迭代相结合时,允许IMP避免层塌。
梯度下降鼓励保存。为了更好地理解IMP算法在训练过程中的动态,我们将考虑一个在算法上等价于量级分数的可微分数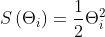 ,考虑在损失函数L上使用无穷小步长(即梯度流)进行梯度下降的整个训练中的这些分数。在这种情况下,参数的temporal导数等于
,考虑在损失函数L上使用无穷小步长(即梯度流)进行梯度下降的整个训练中的这些分数。在这种情况下,参数的temporal导数等于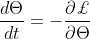 ,因此分数的temporal导数是
,因此分数的temporal导数是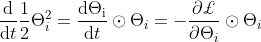 ,,令人惊讶的是,这是突触显著性的一种形式,因此适用于神经元和层的守恒定律,特别地,这意味着对于一个简单的全连接网络的任意两层l和k有
,,令人惊讶的是,这是突触显著性的一种形式,因此适用于神经元和层的守恒定律,特别地,这意味着对于一个简单的全连接网络的任意两层l和k有![\frac{\mathrm{d} }{\mathrm{d} t}\left \| W^{[l]} \right \|_{F}^{2}=\frac{\mathrm{d} }{\mathrm{d} t}\left \| W^{[k]} \right \|_{F}^{2}](https://latex.codecogs.com/gif.latex?%5Cfrac%7B%5Cmathrm%7Bd%7D%20%7D%7B%5Cmathrm%7Bd%7D%20t%7D%5Cleft%20%5C%7C%20W%5E%7B%5Bl%5D%7D%20%5Cright%20%5C%7C_%7BF%7D%5E%7B2%7D%3D%5Cfrac%7B%5Cmathrm%7Bd%7D%20%7D%7B%5Cmathrm%7Bd%7D%20t%7D%5Cleft%20%5C%7C%20W%5E%7B%5Bk%5D%7D%20%5Cright%20%5C%7C_%7BF%7D%5E%7B2%7D) ,之前已经注意到这种不变性是一种隐式正则化形式,并用于解释经过训练的多层模型可以具有类似的分层幅度的经验现象,在修剪的背景下,这种现象意味着梯度下降训练,在足够小的学习率下,鼓励平方量级分数收敛到近似的分层守恒。
,之前已经注意到这种不变性是一种隐式正则化形式,并用于解释经过训练的多层模型可以具有类似的分层幅度的经验现象,在修剪的背景下,这种现象意味着梯度下降训练,在足够小的学习率下,鼓励平方量级分数收敛到近似的分层守恒。
守恒和迭代避免了层崩溃。通过在最大的层中分配相对于较小层的参数的较低分数的参数,仅守恒就会导致层塌,但是,如果将守恒与迭代修剪相结合,那么当最大的一层被修剪,变得更小的时,在后续的迭代中,该层的其余参数将被赋予更高的相对分数。有了足够的迭代,守恒与迭代相结合就形成了一种自平衡的修建策略,允许IMP避免层塌,这种关于守恒和迭代的重要性的见解更广泛地适用于具有精确或近似守恒性质的其他算法。
四、一种满足最大临界压缩的数据不可知算法
在上一节中,我们确定了IMP能够避免层塌的两个关键因素:(1)修剪分数的近似层守恒。(2)这些分数的迭代重新评估。虽然这些属性允许IMP算法识别高性能和高度稀疏,可训练的神经网络,但它需要不切实际的计算量来获得他们。
因此,我们的目标是构建一个更有效的剪枝算法,同时仍然继承IMP成功的关键方面,那么,什么是剪枝算法的基本成分,以避免层塌,并可证明实现最大临界压缩?
定理3.迭代、积极、保守评分达到最大临界压缩。如果一个具有全局屏蔽的修剪算法,分配了尊重分层守恒的正分数,如果修剪尺寸,在任何迭代中修剪的参数的总分,严格小于临界尺寸,整个层的总分,只要可能,那么该算法满足最大临界压缩公理。
迭代突触流修剪(SynFlow)算法。定理3直接激发了新修剪算法SynFlow的设计,可以证明它达到了最大临界压缩。首先,迭代评分的必要性阻碍了设计批量数据反向传播的算法,相反,激励了高效的数据独立评分过程的开发。第二,积极性和保守型激发了损失函数的构建,从而产生积极的突触显著性得分。我们将这些观点结合起来,引入了一个新的损失函数(其中 是全一向量,
是全一向量,![\left | \Theta ^{[l]} \right |](https://latex.codecogs.com/gif.latex?%5Cleft%20%7C%20%5CTheta%20%5E%7B%5Bl%5D%7D%20%5Cright%20%7C) 是第l层参数的元素绝对值)
是第l层参数的元素绝对值)
![\mathbb{R}_{SF}=\mathbb{I}^{T}(\prod _{l=1}^{L}\left | \Theta ^{[l]} \right |)\mathbb{I}](https://latex.codecogs.com/gif.latex?%5Cmathbb%7BR%7D_%7BSF%7D%3D%5Cmathbb%7BI%7D%5E%7BT%7D%28%5Cprod%20_%7Bl%3D1%7D%5E%7BL%7D%5Cleft%20%7C%20%5CTheta%20%5E%7B%5Bl%5D%7D%20%5Cright%20%7C%29%5Cmathbb%7BI%7D)
这就产生了积极的突触显著性分数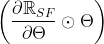 ,我们称之为突触流,对于一个简单的全连接网络,即
,我们称之为突触流,对于一个简单的全连接网络,即![\left ( f(x)=W^{\left [ N \right ]}...W^{[1]}x \right )](https://latex.codecogs.com/gif.latex?%5Cleft%20%28%20f%28x%29%3DW%5E%7B%5Cleft%20%5B%20N%20%5Cright%20%5D%7D...W%5E%7B%5B1%5D%7Dx%20%5Cright%20%29) ,我们可以将参数
,我们可以将参数![w_{ij}^{[l]}](https://latex.codecogs.com/gif.latex?w_%7Bij%7D%5E%7B%5Bl%5D%7D) 的Synaptic Flow评分因式为:
的Synaptic Flow评分因式为:
![S_{SF}(w_{ij}^{[l]})=[\mathbb{I}^{T}\prod _{k=l+1}^{N}\left | W^{[k]} \right |]_{i}\left | w_{ij}^{[l]} \right |[\prod _{k=1}^{l-1}\left | W^{[k]} \right |\mathbb{I}]_{j}](https://latex.codecogs.com/gif.latex?S_%7BSF%7D%28w_%7Bij%7D%5E%7B%5Bl%5D%7D%29%3D%5B%5Cmathbb%7BI%7D%5E%7BT%7D%5Cprod%20_%7Bk%3Dl+1%7D%5E%7BN%7D%5Cleft%20%7C%20W%5E%7B%5Bk%5D%7D%20%5Cright%20%7C%5D_%7Bi%7D%5Cleft%20%7C%20w_%7Bij%7D%5E%7B%5Bl%5D%7D%20%5Cright%20%7C%5B%5Cprod%20_%7Bk%3D1%7D%5E%7Bl-1%7D%5Cleft%20%7C%20W%5E%7B%5Bk%5D%7D%20%5Cright%20%7C%5Cmathbb%7BI%7D%5D_%7Bj%7D)
从这个角度来看,突触流评分是量级评分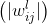 的泛化,其中评分考虑了每个参数中流动的突触强度的乘积,考虑了参数的层间相互作用。事实上,这个更广义的幅度是在之前的文献中已经作为路径范数进行了讨论,
的泛化,其中评分考虑了每个参数中流动的突触强度的乘积,考虑了参数的层间相互作用。事实上,这个更广义的幅度是在之前的文献中已经作为路径范数进行了讨论,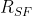 中的突触流损失是网络的l1路径范数,参数的突触流分数是通过该参数的范数的一部分,我们在下面伪代码中总结的迭代突触修剪(SynFlow)算法中使用突触流评分。
中的突触流损失是网络的l1路径范数,参数的突触流分数是通过该参数的范数的一部分,我们在下面伪代码中总结的迭代突触修剪(SynFlow)算法中使用突触流评分。

给定一个网络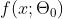 和指定的压缩比
和指定的压缩比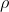 ,SynFlow算法只需要一个额外的超参数,即修剪迭代次数n
,SynFlow算法只需要一个额外的超参数,即修剪迭代次数n
五、总结
在本文中,我们开发了一个统一的理论框架,解释了为什么现有的剪枝算法在初始化时会出现层塌,我们应用我们的框架来阐明迭代量级修剪如何克服层塌,以在初始化时识别中奖彩票。在此基础上,我们设计了一种新的数据不可知剪枝算法SynFlow,该算法可以避免层塌并达到最大临界压缩,最后,我们从经验上证实,我们的SynFlow算法在12个不同的模型和数据集组合中始终匹配或优于现有算法、尽管我们的算法是数据不可知的,并且不需要预先训练,这项工作有希望的未来方向是:(1).探索满足最大临界压缩的潜在剪枝算法的更大空间。(2)利用SynFlow作为计算适当的每层压缩比的有效方法,以结合现有的评分指标。(3).将剪枝作为神经网络初始化方案的一部分。总的来说,我们的数据不可知修剪算法挑战了现有的范式,即在初始化时必须使用数据来量化神经网络的哪些突触是重要的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)