仅供自己学习使用!!!
这篇博客先对数据集做一些介绍
参考链接:http://docode.techyoung.cn/breast_cancer_wisconsin.html
乳腺癌的早期诊断意义重大!
数据集:威斯康辛大学关于乳腺癌诊断数据集
链接:https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29

数据集共有30个特征,前10个特征是样本图像中细胞核特征值的平均值:

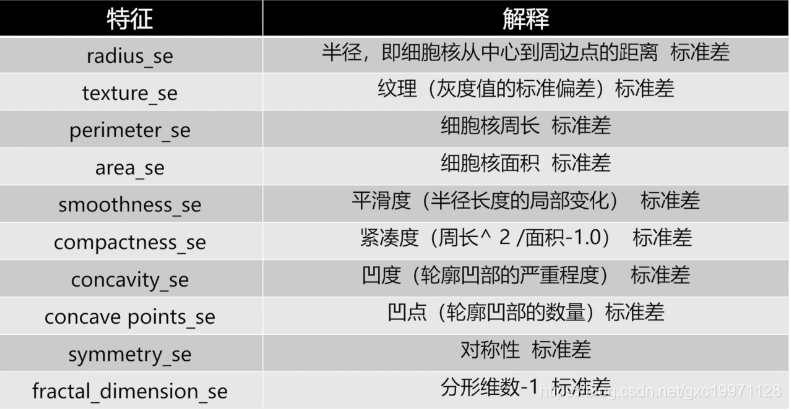
第11到第20个特征为样本图像中细胞核特征值的标准差,反映的是在一个样本图像中不同细胞核在各个特征数值上的波动情况:
第21到30个特征为样本图像中细胞核特征值的最大值,这个最大值并非是整个样本最大值,而是特征值前三名的平均值,这样可以减弱计算和测算过程中误差所带来的影响:

为数据集作一个整体总结:


均值可以看出样本中细胞核总体形态特征;标准差反映各个细胞核中的差异程度,是一个良好的分类特征;恶性与良性有些细胞核面积差异较大,用最大值能够较好反映特征。
特征讲解
半径


纹理


周长和面积


平滑度


凹点



凹度



对称性


分形维数



前十个均值特征之间的关系

小结

代码
1.数据加载
原数据集中有30个特征,样本数量为569
import numpy as np
import pandas as pd
dataset = pd.read_csv(r'D:\Documents\myProject\dadaists\wdbc.csv', header=0,
usecols = range(0,32,1))
dataset
print(dataset)
上面尝试失败,下面用导包的方式:
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = load_breast_cancer()#导入数据集,探索数据
data.data.shape
print(data.data.shape)#输出乳腺癌数据集中的数据情况,从输出结果可以看出乳腺癌数据集有569条数据,30个特征

正式开始:
1.若使用sklearn库,则代码实现如下:
从sklearn库中导入该乳腺癌数据集,主体代码中,首先load,第三行中的cv=5是指实现五折交叉验证

2.不使用sklearn库,而是自己定义:


本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)