分布式实时数据处理框架——Storm
1. Storm简介与核心概念
1.1 Storm 简介
全称为 Apache Storm,是一个分布式实时大数据处理系统。它是一个流数据框架,具有最高的获取率。它比较简单,可以并行地对实时数据执行各种操作。它通过Apache ZooKeeper 集群管理分布式环境和集群状态。Apache Storm 继续成为实时数据分析的领导者。Storm 易于设置和操作,并且它保证每个消息将通过拓扑至少处理一次。
Storm区别于Hadoop,但又被业界称为实时版的Hadoop,源于越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
1.2 Storm 核心概念(组件)
- Nimbus:Storm 集群主节点(master),负责资源分配和任务调度。我们提交任务和截止任务都是在 Nimbus 上操作的。一个 Storm 集群只有一个 Nimbus 节点;
- Supervisor:Storm 集群工作节点(slave),负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程;
- Worker:工作进程,每个工作进程中都有多个 Task;
- Task:任务,每个 Spout 和 Bolt 都是一个任务,每个任务都是一个线程;
- Topology:计算拓扑,是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构;
- Stream:消息流,是拓扑中数据流的来源,关键抽象概念,是没有边界的 Tuple 序列;
- Spout:消息流的源头,Topology 的消息生产者,一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中,这些数据源可以来自数据库、文件、消息队列;
- Bolt:消息处理单元,可以完成过滤、聚合、联结、查询数据库等几乎所有的数据处理需求;
- Stream grouping:消息分发策略,一共 8 种,定义每个 Bolt 接受何种输入;
- Reliability:可靠性,Storm 保证每个 Tuple 都会被处理。
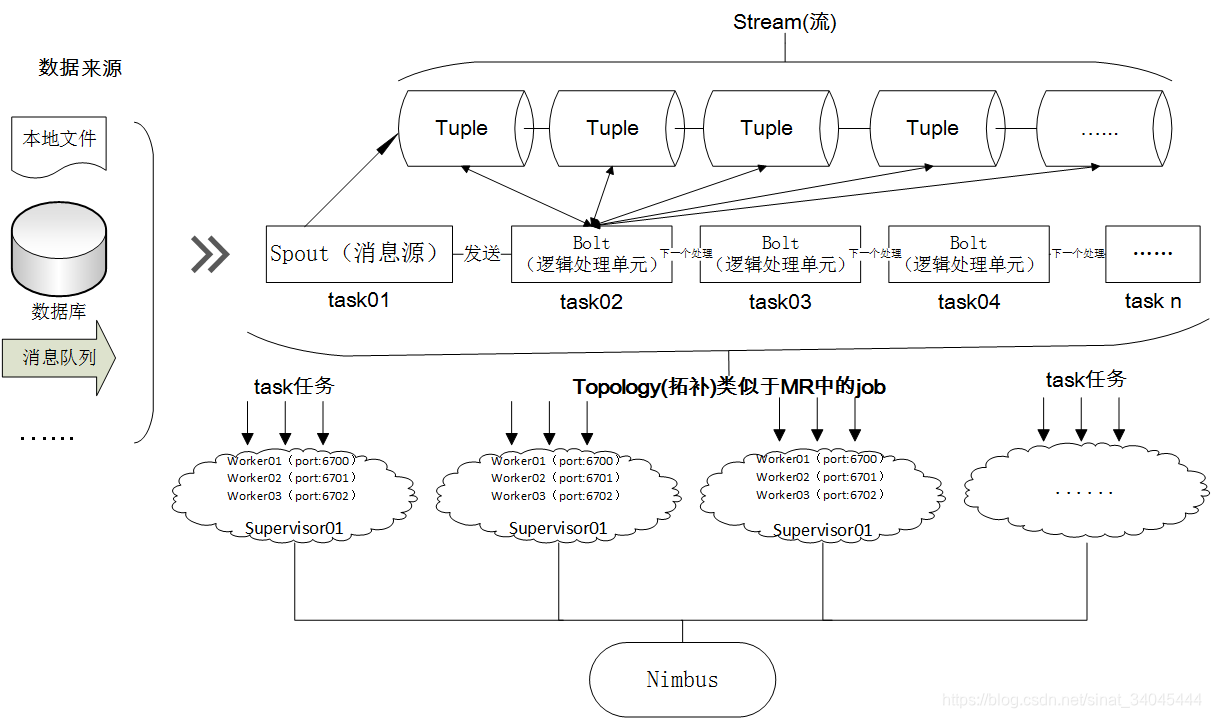
1.3 Storm 架构原理
1.3.1 Storm 集群架构
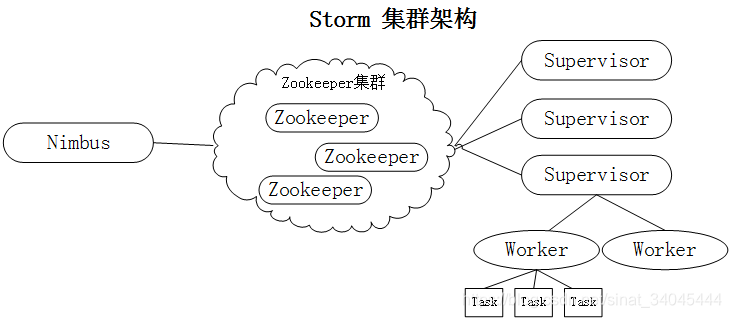
Zookeeper 集群负责Nimbus 节点和 Supervior 节点之间的通信,监控各个节点之间的状态,它在 Storm 集群中逻辑上是独立的,但在实际部署的时候,一般会将 zk节点部署在 Nimbus 节点或 Supervisor 节点上。
1.3.2 Storm 数据处理流程
Storm 处理数据的特点:适合管理实时数据,数据源源不断,不断处理:
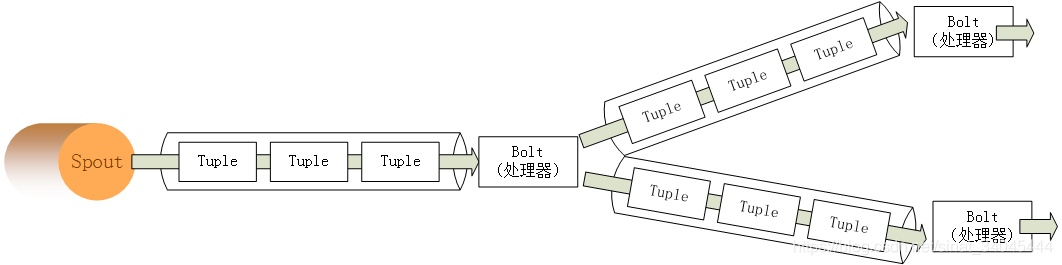
- Spout:消息流的源头,Topology 的消息生产者;
- Bolt:消息处理单元,可以过滤、聚合、查询数据库;
- tuple:就是一个值列表,是 storm 主要数据结构,是 storm 中使用的最基本单元、数据模型和元组。
1.3.3 Storm 拓扑图(spouts 和 bolts 组成的图)
storm 中是没有数据存储结构的,本身是不存储数据,需要我们自己设计数据落地接口,指明数据存储到哪一部分中:
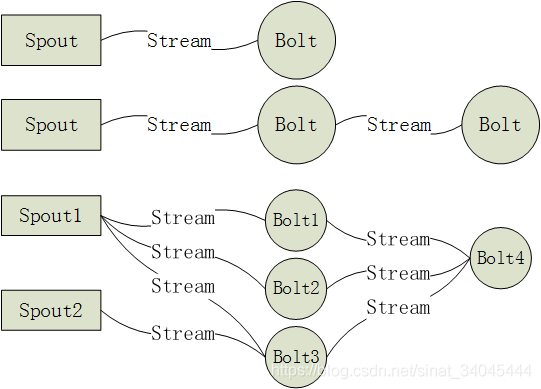
- 第一种简单类型:由一个Spout获取数据,然后交给一个Bolt进行处理;
- 第二种稍复杂类型:由一个Spout获取数据,然后交给一个Bolt进行处理一部分,然后在交给下一个Bolt进行处理其他部分。
- 第三种复杂类型一个Spout可以同时发送数据到多个Bolt,而一个Bolt也可以接受多个Spout或多个Bolt,最终形成多个数据流。但是这种数据流必须是有方向的,有起点和终点,不然会造成死循环,数据永远也处理不完。就是Spout发给Bolt1,Bolt1发给Bolt2,Bolt2又发给了Bolt1,最终形成了一个环状。
1.4 Storm 的主要应用
1.4.1 数据流处理( stream processing)
Storm 可用来实时处理新数据和更新数据库,兼具容错性和可扩展性,即 Storm 可以用来处理源源不断流进来的消息,处理之后将结果写入某个存储中。如:
- 条件过滤:这是Storm最基本的处理方式,对符合条件的数据进行实时过滤,将符合条件的数据保存下来,这种实时查询的业务需求再实际应用中很常见。
- 中间计算:我们需要改变数据中某一个字段(例如是数值),我们需要利用一个中间值经过计算(值比较、求和、求平均等等)后改变该值,然后将数据重新输出。
- 求TopN:相信大家对TopN类的业务需求也比较熟悉,在规定时间窗口内,统计数据出现的TopN,该类处理在购物及电商业务需求中,比较常见。
1.4.2 持续计算( continuous computation)
Storm 可进行连续查询并把结果即时反馈给客户端,如把 Twitter 上的热门话题发送到浏览器中 ,Storm能保证计算可以永久运行,直到用户结束计算进程为止。如:
- 推荐系统:有时候在实时处理时会从mysql及hadoop中获取数据库中的信息,例如在电影推荐系统中,传入数据为:用户当前点播电影信息,从数据库中获取的是该用户之前的一些点播电影信息统计,例如点播最多的电影类型、最近点播的电影类型,及其社交关系中点播信息,结合本次点击及从数据库中获取的信息,生成推荐数据,推荐给该用户。并且该次点击记录将会更新其数据库中的参考信息,这样就是实现了简单的智能推荐。
- 批处理:所谓批处理就是数据积攒到一定触发条件,就批量输出,所谓的触发条件类似事件窗口到了,统计数量够了即检测到某种数据传入等等。
- 热度统计:热度统计实现依赖于Storm提供的TimeCacheMap数据结构,现在可能推荐用RotatingMap,该结构能够在内存中保存近期活跃的对象。我们可以使用它来实现例如论坛中热帖排行计算等。
1.4.3 分布式远程程序调用( distributed RPC)
轻松地并行化CPU密集型操作。如:
- 分布式RPC:Storm有对RPC进行专门的设计,分布式RPC用于对Storm上大量的函数进行并行计算,最后将结果返回给客户端。
2. Storm 入门案例
通过Strom API 编写入门案例,在非集群的本地环境下运行体验 Storm 实时处理数据的底层实现,有助于更好的理解 Storm 实时数据处理的开发流程。
2.1 数字累加操作
| 业务 | 对1,2,3,4....这种递增数字进行累加求和 |
| topology | spout | 负责产生从1开始的递增数据,每次加1 |
| bolt | 负责对spout发送出来的数据进行累加求和 |
- eclipse 开发工具借助 Maven 环境新建项目;
- 添加 Storm 依赖:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.2</version>
</dependency>
- 编写代码:
public class LocalTopology {
public static class MySpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
int num=0;
@Override
public void nextTuple() {
num++;
this.collector.emit(new Values(num));
System.out.println("spout:"+num);
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
public static class SumBolt extends BaseRichBolt{
private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
int sum = 0;
@Override
public void execute(Tuple input) {
Integer num = input.getIntegerByField("num");
sum+=num;
System.out.println("和为:"+sum);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spoutid", new MySpout());
topologyBuilder.setBolt("boltid", new SumBolt()).shuffleGrouping("spoutid");
LocalCluster localCluster = new LocalCluster();
String simpleName = LocalTopology.class.getSimpleName();
Config config = new Config();
localCluster.submitTopology(simpleName, config, topologyBuilder.createTopology());
}
}
- 结果:
spout:1
和为:1
spout:2
和为:3
spout:3
和为:6
spout:4
和为:10
.....
2.2 实时累计成交订单金额
| 业务 | 模拟解析天猫用户订单数据,对用户下单总金额进行实时汇总 |
| topology | tmalldataspout | 负责读取文件中的一行行内容 |
| parsebolt | 负责对订单信息进行解析 |
| sumbolt | 负责对订单金额进行汇总 |
- 项目根目录下传入tmalldata.txt文件:
100010 会飞的鱼_123 13210982233 2016/12/1 10:11 89.9 请发顺丰快递
100011 别来我回忆里微笑 18712317876 2016/12/1 12:21 199 无
100012 真心不如红钞票 18623450989 2016/12/1 12:43 39.9 无
100013 qingfeng7109 18901292615 2016/12/1 13:11 167 无
100014 梦醒de泪痕 13910002697 2016/12/1 13:49 132 请开具纸质发票
100015 wuah1314 17911112836 2016/12/1 14:07 248 无
100016 黑白色 15611595966 2016/12/1 14:18 178 无
100017 仰望天猪 13311295111 2016/12/1 14:29 86.9 无
100018 天涯浪子 18511512315 2016/12/1 15:20 78.2 无
100019 dingdang 17210963299 2016/12/1 15:39 156 无
100020 堕落的永恒 15610615388 2016/12/1 15:54 124 无
- 编写代码:
public class LocalTmallTopology {
public static class TmallDataSpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
private BufferedReader bufferedReader;
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.conf = conf;
this.context =context;
this.collector = collector;
try {
bufferedReader = new BufferedReader(new FileReader("tmalldata.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
String line = null;
@Override
public void nextTuple() {
try {
line = bufferedReader.readLine();
if(line!=null){
this.collector.emit(new Values(line));
}
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
public static class ParseBolt extends BaseRichBolt{
private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] splits = line.split("\t");
if(splits.length==6){
this.collector.emit(new Values(splits[0],splits[4]));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id","actualFee"));
}
}
public static class SumBolt extends BaseRichBolt{
private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
double sum = 0;
@Override
public void execute(Tuple input) {
String price = input.getStringByField("actualFee");
sum+=Double.parseDouble(price);
System.out.println("订单总金额:"+sum);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spoutid", new TmallDataSpout());
topologyBuilder.setBolt("boltid1", new ParseBolt()).shuffleGrouping("spoutid");
topologyBuilder.setBolt("boltid2", new SumBolt()).shuffleGrouping("boltid1");
LocalCluster localCluster = new LocalCluster();
String simpleName = LocalTmallTopology.class.getSimpleName();
Config config = new Config();
localCluster.submitTopology(simpleName, config, topologyBuilder.createTopology());
}
}
- 结果:
订单总金额:89.9
订单总金额:288.9
订单总金额:328.79999999999995
订单总金额:495.79999999999995
订单总金额:627.8
订单总金额:875.8
订单总金额:1053.8
订单总金额:1140.7
订单总金额:1218.9
订单总金额:1374.9
订单总金额:1498.9
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)