参考之前小节的大数据010——Hive与大数据012——HBase成功搭建Hive和HBase的环境,并进行了相应的测试,并且在大数据011——Sqoop中实现Hive、HBase与MySQL之间的相互转换;本文讲述如何将Hive与HBase进行整合。
1. Hive与HBase整合概述
1.1 整合原理
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-handler-*.jar工具类来实现。
1.2 应用场景
1.2.1 将ETL操作的数据存入HBase
通过Hive的ETL操作把经过处理数据加载到HBase中,数据源可以是HDFS上的文件也可以是Hive中的表。

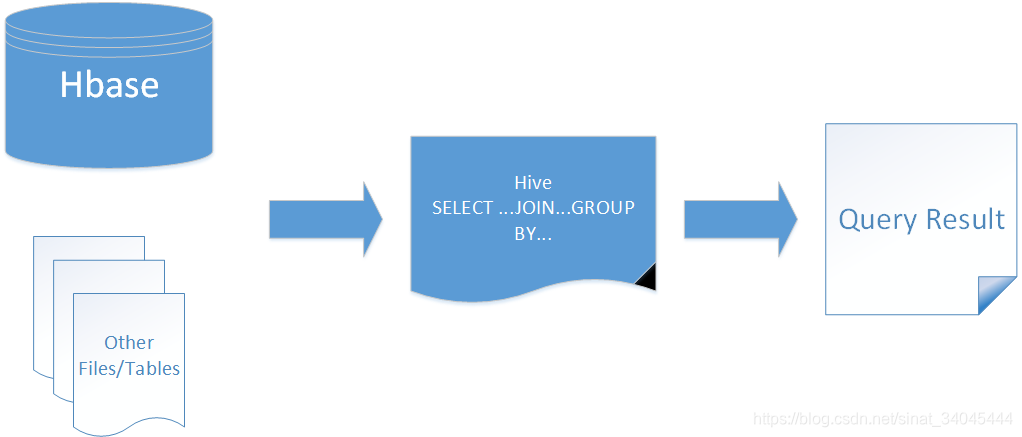
1.2.2 HBase作为Hive的数据源
如果让HBase作为数据源,则通过整合可以让HBase数据与HDFS文件数据用Hive 实现 JOIN、GROUP等SQL查询语法。
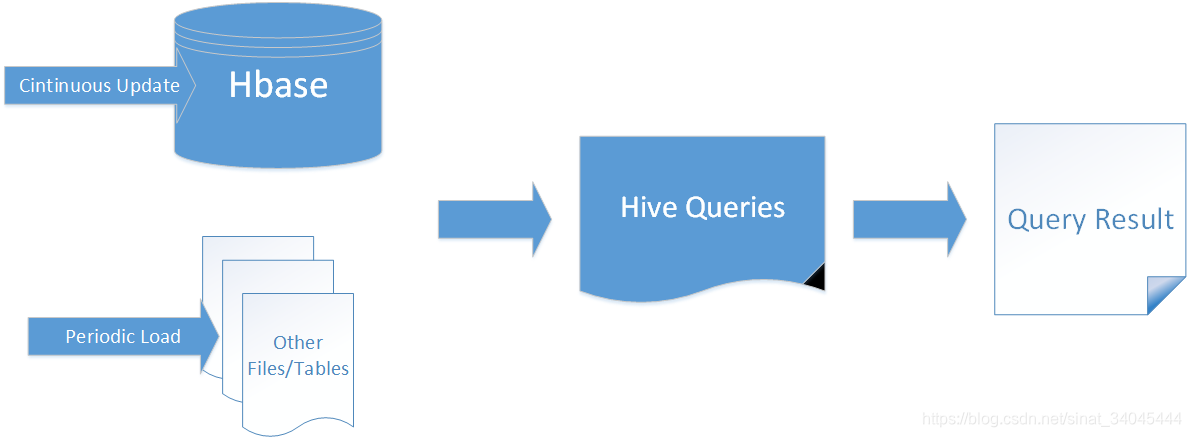
1.2.3 构建低延时的数据仓库
通过整合Hive不仅可完成HBase的数据实时查询,也可以使用Hive查询HBase中的数据完成复杂的数据分析。
2. Hive与HBase整合配置
2.1 环境准备
参照之前小节安装Hadoop集群、Hive、HBase。
2.2 关键配置
1)、进入到 hive/lib 目录下,把 hive-hbase-handler-1.2.1.jar 复制到 hbase/lib 目录下:
[root@node01 ~]# cd /home/hive-1.2.1/lib
[root@node01 lib]# cp -f hive-hbase-handler-1.2.1.jar /home/hbase-0.98.12.1/lib/
2)、把 hbase/lib 目录下的所有的jar包拷贝到 hive/lib 目录下:
\cp -rf /home/hbase-0.98.12.1/lib/* /home/hive-1.2.1/lib
注意:\cp 命令可以不提示覆盖文件的提示cp: overwrite xxx。
3)、修改 hive 的配置文件 hive/conf/hive-site.xml 增加属性:
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
4)、在 hive 中创建映射表
- 启动Zookeeper集群、Hadoop集群、MySQL 服务;
- 启动 hive、hbase;
- 创建映射表:
hive> CREATE TABLE hivetb(key int, name string, age string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:name,cf1:age")
TBLPROPERTIES ("hbase.table.name" = "hbasetb", "hbase.mapred.output.outputtable" = "hbasetb");
- 检查表格:
hive> show tables;
OK
hbasetbl
hivetb
psn
Time taken: 0.096 seconds, Fetched: 3 row(s)
hbase(main):002:0> list
TABLE
SYSTEM.CATALOG
SYSTEM.FUNCTION
SYSTEM.SEQUENCE
SYSTEM.STATS
hbasetb
5 row(s) in 0.0800 seconds
=> ["SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "hbasetb"]
hbase(main):003:0> desc 'hbasetb'
Table hbasetb is ENABLED
hbasetb
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMP
RESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.3220 seconds
2.3 测试
使用HQL向hive表插入一条数据:
hive> INSERT INTO TABLE hivetb VALUES(1,'zhangsa',18),(2,'lisi',22);
Query ID = root_20190127174636_a94d5259-84ca-4de3-ab82-9253c60a38f2
Total jobs = 1
......
2019-01-27 17:46:48,514 Stage-0 map = 0%, reduce = 0%
2019-01-27 17:47:21,544 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 2.43 sec
MapReduce Total cumulative CPU time: 2 seconds 430 msec
Ended Job = job_1548581535082_0001
MapReduce Jobs Launched:
Stage-Stage-0: Map: 1 Cumulative CPU: 2.43 sec HDFS Read: 9789 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 430 msec
OK
Time taken: 47.42 seconds
hive> use default;
OK
Time taken: 0.506 seconds
hive> select * from hivetb;
OK
1 zhangsa 18
2 lisi 22
Time taken: 0.119 seconds, Fetched: 2 row(s)
hive>
在HBase端查看插入的数据:
hbase(main):002:0> scan 'hbasetb'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=1548582441196, value=18
1 column=cf1:name, timestamp=1548582441196, value=zhangsa
2 column=cf1:age, timestamp=1548582441196, value=22
2 column=cf1:name, timestamp=1548582441196, value=lisi
2 row(s) in 0.1600 seconds
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)