异常检测算法种类繁多,包括聚类,树,统计分布,机器学习,深度学习等多种形式,下面对一些常见问题进行了自己的总结:
1.如何选型?
主要看算法原理和数据分布:
如下图所示,第一二张图的异常点容易成一个团,形成局部离群点,而图三则是全局离群点,不同的离群方式应当采用不同的算法,比如图1,2用聚类,图3用孤立森林。

一个非常好用的异常检测工具包:https://github.com/yzhao062/pyod
2.算法集成。
算法种类多,有时候单一算法并不能满足要求,需要对多算法做测试甚至进行集成,以提高性能。
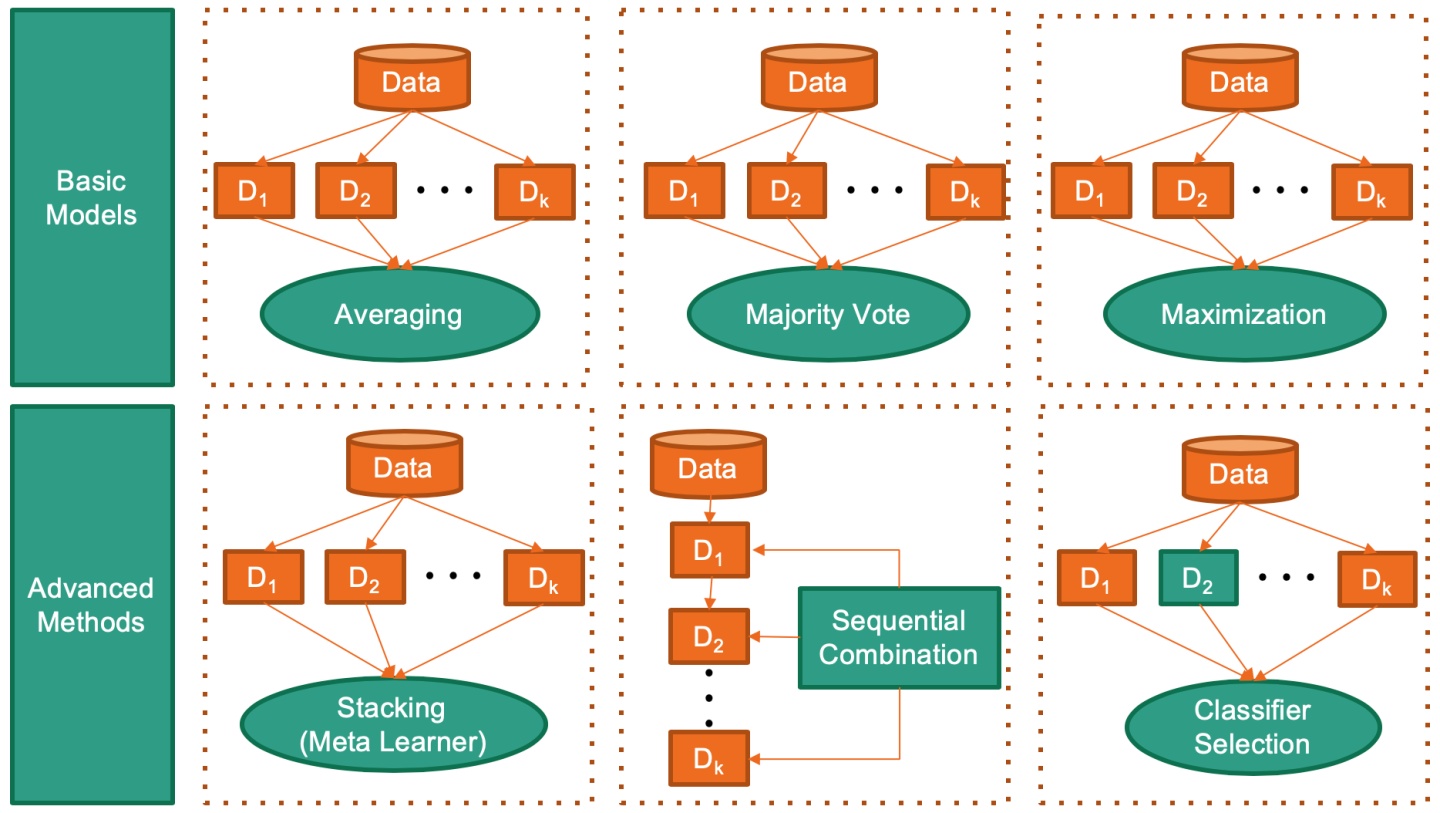
如下图所示的多种集成方式,并不能简单的做一个投票或者均值就进行集成学习,因为全局均值可能会对某些模型输出的异常平均掉。
甚至复杂的还有动态分类器选择,在进行预测的时候,选择训练集中相似的近似空间,并选择在这个相似的近似空间中最好的算法或者是集成算法。
集成工具介绍:https://github.com/yzhao062/combo
动态集成:https://github.com/yzhao062/LSCP
3.异常检测集成加速。
异常检测的集成在很多情况下能对结果有很大的帮助,但是带了的事时间复杂度的提升,如何在有限的时间内尽可能快的进行集成的异常检测,suod很好的解决了这个问题。
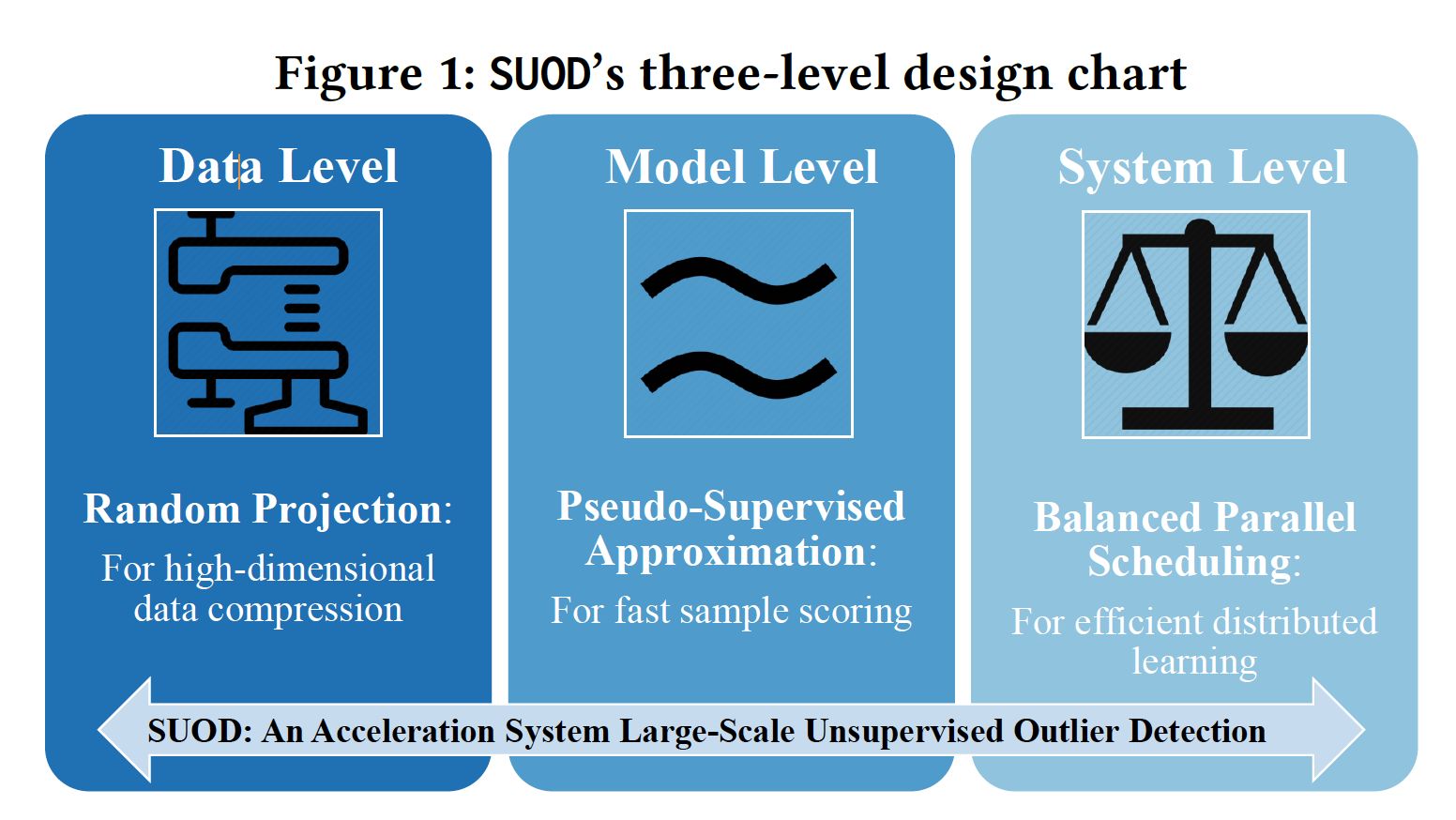
suod在3个纬度进行了异常检测集成的加速:
1.数据维度:用了Johnson-Lindenstrauss (JL) projection进行数据降维。
2.模型维度 :在预测的时候,如果耗时过高,就用有监督学习进行训练数据异常分数的拟合,然后用监督学习替代非监督学习进行预测。
3.系统维度:用了耗时预测对算法进行排列,将新的排列发到不同的worker,以防止出现单一worker的拖后腿
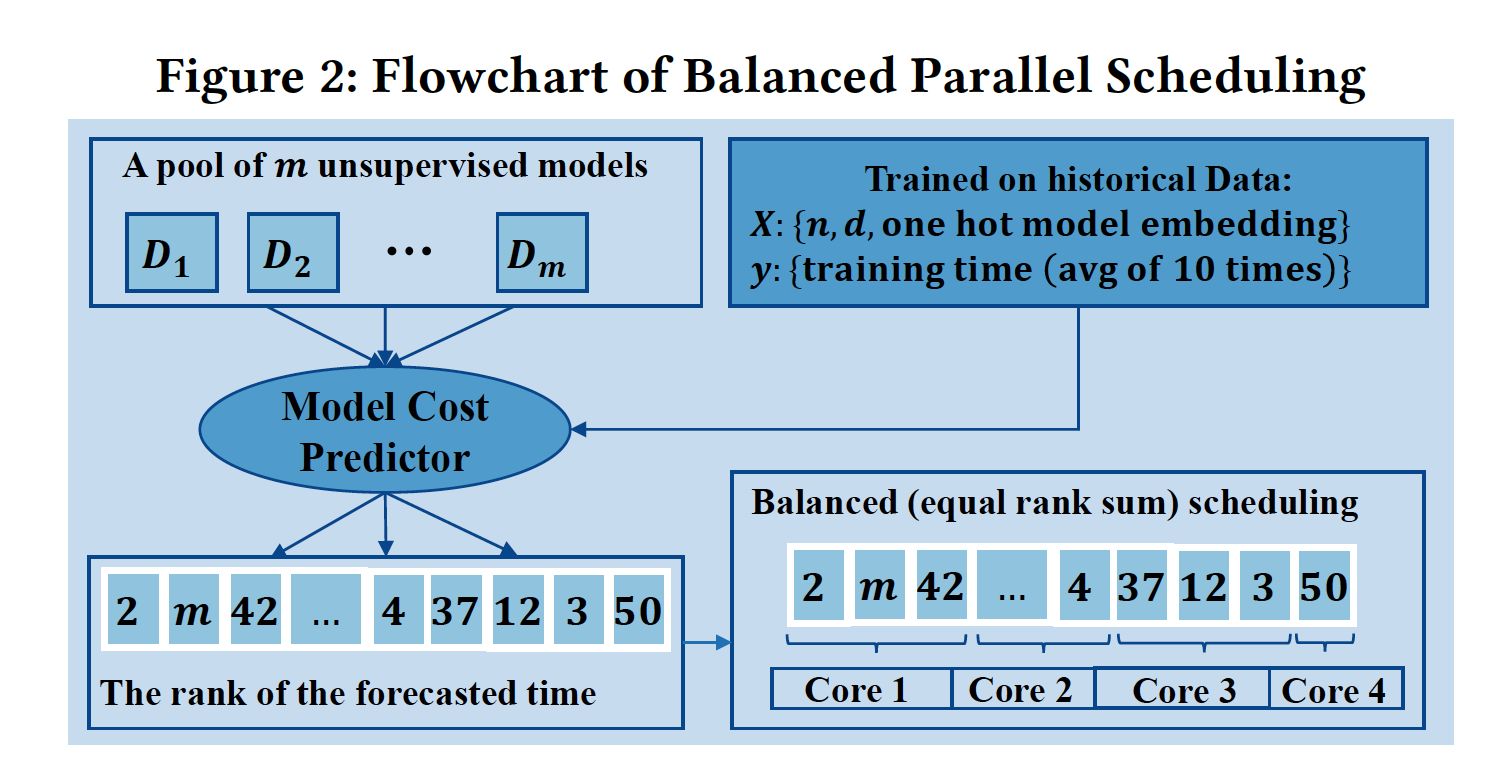
详见:GitHub - yzhao062/SUOD: (MLSys' 21) An Acceleration System for Large-scare Unsupervised Heterogeneous Outlier Detection (Anomaly Detection)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)