Swin Transformer V2
论文链接:https://arxiv.org/pdf/2111.09833.pdf
代码链接:https://github.com/microsoft/Swin-Transformer
问题:
作者提出了将Swin Transformer缩放到30亿个参数的技术 ,并使其能够使用高达1536×1536分辨率的图像进行训练。在很多方面达到了SOTA。
目前,视觉模型尚未像NLP语言模型那样被广泛探索,部分原因是训练和应用中的以下差异:
1) 视觉模型通常在规模上面临不稳定性问题;
2) 许多下游视觉任务需要高分辨率图像,如何有效地将低分辨率预训练的模型转换为高分辨率模型尚未被有效探索,也就是跨窗口分辨率迁移模型时性能下降。当图像分辨率较高时,GPU显存消耗也是一个问题。
解决思路:
为了解决这些问题,作者提出了几种技术,并在本文中以Swin Transformer进行了说明:
1)提高大视觉模型稳定性的后归一化(post normalization) 技术和缩放余弦注意力(scaled cosine attention) 方法;
2)一种对数间隔连续位置偏差技术(log-spaced continuous position bias technique) ,用于有效地将在低分辨率图像中预训练的模型转换为其高分辨率对应模型。

作者发现,在大型模型中,各层之间的激活幅度差异显著增大。仔细观察结构可以发现,这是由直接添加回主分支的残差单元的输出引起的。结果是激活值逐层累积,因此深层的振幅明显大于早期层的振幅。为了解决这个问题,作者提出了一种新的归一化配置,称为post norm,它将LN层从每个残差单元的开始移动到后端 ,如上图所示。作者发现,这种新的配置在网络层上产生了更温和的激活值。作者还提出了一种缩放余弦注意(scaled cosine attention)来取代以前的点积注意(dot product attention) 。缩放余弦注意使得计算与块输入的振幅无关,并且注意值不太可能陷入极端。
具体实现:
Scaling Up Model Capacity

每个残差块的输出激活值直接合并回主分支,并且主分支的振幅在更深层会越来越大。不同层中的振幅差异过大可能会导致训练不稳定问题。为了缓解这个问题,作者提出使用后归一化(post normalization) 方法。在这种方法中,每个残差块的输出在合并回主分支之前被归一化,并且当层加深时,主分支的振幅不会累积。如上图所示,这种方法的激活幅度比原始预归一化配置中的激活幅度要温和得多。
Scaled cosine attention
作者发现,在使用这种方法进行大型视觉模型时,某些block和head的学习注意力通常由几个像素对控制,特别是在后归一化配置中。为了缓解这个问题,作者提出了一种缩放余弦注意(scaled cosine attention)方法,该方法通过缩放余弦函数计算像素对i和j的注意力:
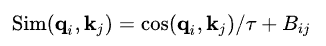
Bij表示像素ij之间的相对位置偏移,τ是科学系的标量,在head和层之间不共享,
Scaling Up Window Resolution
在本小节中,作者提出了一种对数间隔连续位置偏差(log-spaced continuous position bias) 方法。以使得相对位置偏差可以在窗口分辨率之间平滑地迁移。
Continuous Relative Position Bias
连续位置偏差方法不是直接优化参数化偏差,而是在相对坐标上引入一个小的元(meta)网络:
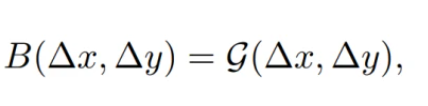
G是一个很小的网络,比如2层MLP。它对任意相对坐标生成偏置参数,因而可以自然地进行任意可变窗口尺寸的迁移。在推理阶段,每个相对位置的偏置可以预先计算并保存,按照原始方式进行推理。
Log-space Coordinates


也就是通过log的方式将外插比例缩小了。

感觉还有很多理解不到位,希望大家可以分享一下自己的想法,一起交流交流。
参考链接:
https://bbs.cvmart.net/articles/5772
https://view.inews.qq.com/a/20211121A03FGF00
https://zhuanlan.zhihu.com/p/436072504
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)