引言
笔者Ultra-Fast-Lane-Detection专栏链接🔗导航:
- 【Lane】 Ultra-Fast-Lane-Detection 复现
- 【Lane】Ultra-Fast-Lane-Detection(1)自定义数据集训练
- 【Lane】Ultra-Fast-Lane-Detection(2)自定义模型测试
笔者的上一篇博客链接1,可以作为读者的车道线检测初探索。
此外笔者重新更新一篇车道线检测(Ultra-Fast-Lane-Detection)完整复现思路(主要针对自定义数据集)
内容包括:环境搭建、数据准备、模型训练、模型测试
1 环境搭建
首先下载项目源码:Ultra-Fast-Lane-Detection源码地址
git clone https://github.com/cfzd/Ultra-Fast-Lane-Detection
cd Ultra-Fast-Lane-Detection
Windows系统下则直接手动下载解压,项目文件中的INSTALL.md中有详细的环境搭建步骤,可以作为环境搭建的参考
笔者基于Anaconda环境搭建指令总结如下:
(Anaconda的安装教程可以参考笔者的博客【Anaconda】windows安装Anaconda)
conda create -n lane(自定义) python=3.7 -y
conda activate lane
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio===0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install setuptools==59.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
上述简单的几个步骤就完成了环境的搭建
2 数据集准备
2.1 数据标注
使用labelme数据标注工具实现数据集的准备
人工标注完数据结构如下:
datasets
├─json(标签文件)
│ 202105270040-right00109.json
│ 202105270040-right00111.json
│ 202105270040-right00161.json
│
└─pic(图像数据)
202105270040-right00109.jpg
202105270040-right00111.jpg
202105270040-right00161.jpg
笔者的标注图像如下(简单的用两条直线标注轨道线):
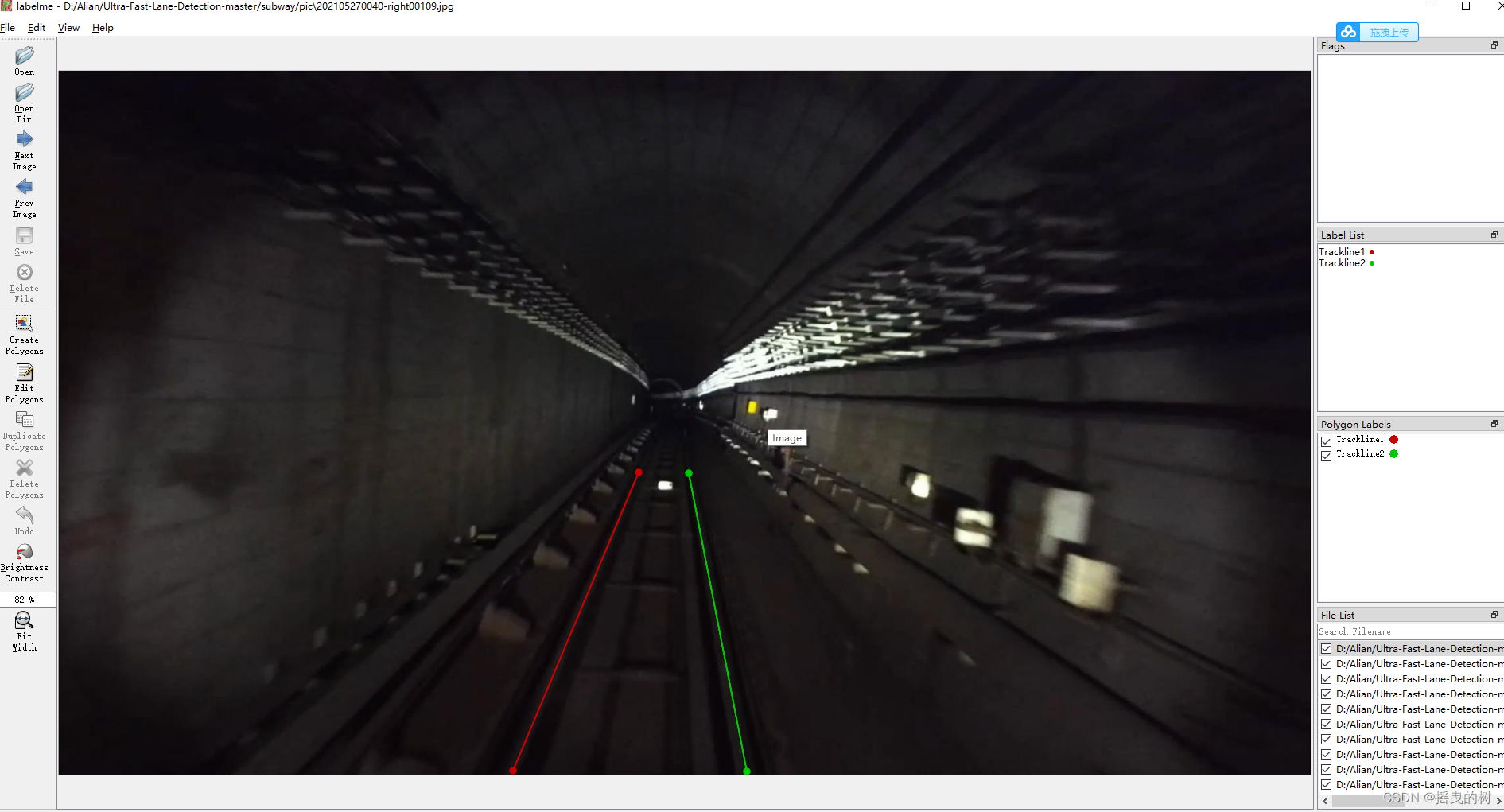
2.2 生成实例图像
创建脚本/utils_alian/instance.py,(utils_alian为笔者创建的文件夹,用于存放自定义的脚本)其中代码如下:
"""
2022.4.17
author:alian
function:
根据labelme标注的文件生成实例掩膜
"""
import argparse
import glob
import json
import os
import os.path as ops
import cv2
import numpy as np
def init_args():
parser = argparse.ArgumentParser()
parser.add_argument('--img_dir', type=str, help='The origin path of image')
parser.add_argument('--json_dir', type=str, help='The origin path of json')
return parser.parse_args()
def process_json_file(img_path, json_path, instance_dst_dir):
"""
:param img_path: 原始图像路径
:param json_path: 标签文件路径
:param instance_dst_dir:实例图像保存路径
:return:
"""
assert ops.exists(img_path), '{:s} not exist'.format(img_path)
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
instance_image = np.zeros([image.shape[0], image.shape[1]], np.uint8)
with open(json_path, 'r',encoding='utf8') as file:
info_dict = json.load(file)
for ind,info in enumerate(info_dict['shapes']):
contours = info['points']
contours = np.array(contours,dtype=int)
cv2.fillPoly(instance_image, [contours], (ind+1, ind+1, ind+1))
instance_image_path = img_path.replace(os.path.dirname(img_path),instance_dst_dir)
cv2.imwrite(instance_image_path.replace('.jpg','.png'), instance_image)
def process_tusimple_dataset(img_dir,json_dir):
"""
:param json_dir: 标签文件路径
:param img_dir: 原始图像路径
:return:
"""
gt_instance_dir = ops.join(os.path.dirname(img_dir), 'label')
os.makedirs(gt_instance_dir, exist_ok=True)
for img_path in glob.glob('{:s}/*.jpg'.format(img_dir)):
json_path = img_path.replace(img_dir,json_dir).replace('.jpg','.json')
process_json_file(img_path, json_path, gt_instance_dir)
return
if __name__ == '__main__':
img_dir = r'./pic'
json_dir = r'./json'
process_tusimple_dataset(img_dir,json_dir)
生成实例图片如下:
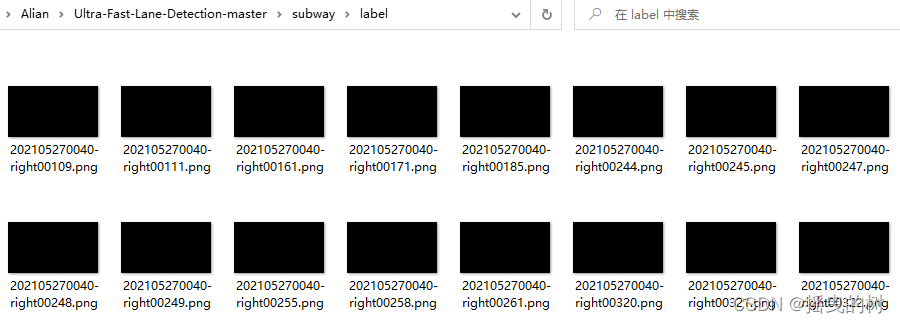
2.3 验证标签数
上篇博客【Lane】 Ultra-Fast-Lane-Detection 复现中提到:由于数据集的类别数与指定的类别数不一致导致训练出错,解决方法:
验证标签数目与训练时指定的数量一致,创建脚本utils_alian/check_label_num.py,代码如下:
"""
2022.4.17
author:alian
function:
核查.json标签数量
"""
import numpy as np
import scipy.special
import os
import cv2
path = r'C:\Users\ZNJT\Desktop\yuanshi\yuanshi\label'
a = os.listdir(path)
print(a)
for i in a:
img = cv2.imread(os.path.join(path,i),-1)
print(set((img.flatten())))
终端显示如下:
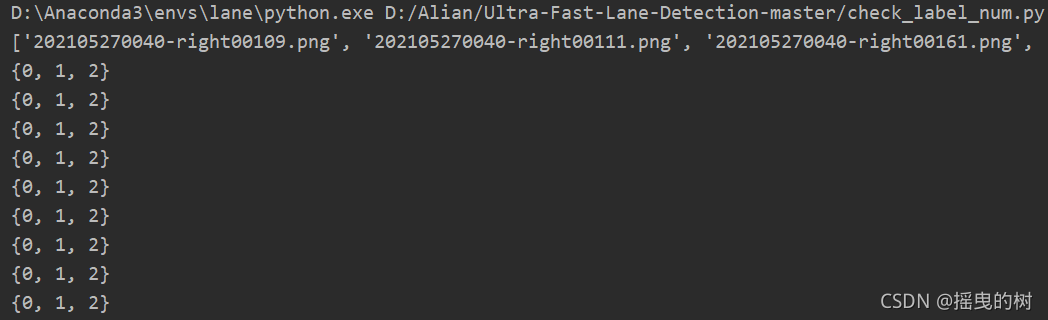
0默认为背景标签,上述显示说明车道线数有2个,代码运行完数据集目录结构如下:
datasets
├─json(标签文件)
│ 202105270040-right00109.json
│ 202105270040-right00111.json
│ 202105270040-right00161.json
│
├─label
│ 202105270040-right00109.png
│ 202105270040-right00111.png
│ 202105270040-right00161.png
│
└─pic(图像数据)
202105270040-right00109.jpg
202105270040-right00111.jpg
202105270040-right00161.jpg
3 模型训练
笔者对源码进行修改,主要针对自定义的数据集,删除了开源数据集的部分,修改的脚本文件如图所示
在项目中创建文件夹utils_alian,将自定义的脚本文件放在其中
3.1 配置文件的修改
创建脚本utils_alian/config.py,代码如下:
"""
2022.4.20
author:alian
function:
训练参数配置
"""
import argparse,datetime,os
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--source', type=str, default='./dataset/',help='数据库路径')
parser.add_argument('--log_path', type=str, default='./logs/', help='模型保存路径')
parser.add_argument('--epoch', type=int, default=100, help='训练轮数')
parser.add_argument('--batch_size', type=int, default=32, help='')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--optimizer', type=str, default='Adam', help='优化器:[SGD,Adam]')
parser.add_argument('--learning_rate', type=float, default=4e-4, help='学习率')
parser.add_argument('--weight_decay', type=float, default=1e-4, help='权重衰减系数')
parser.add_argument('--momentum', type=float, default=0.9, help='动量')
parser.add_argument('--scheduler', type=str, default='cos', help='调度器:[multi, cos]')
parser.add_argument('--gamma', type=float, default=0.1, help='模型预热')
parser.add_argument('--warmup', type=str, default='linear', help='模型预热')
parser.add_argument('--warmup_iters', type=int, default=100, help='模型预热')
parser.add_argument('--backbone', type=str, default='18', help='网络骨干')
parser.add_argument('--use_aux', type=bool, default=True, help='是否使用语义标签')
parser.add_argument('--griding_num', type=int, default=100, help='网格列数')
parser.add_argument('--row_anchor', type=int, default=56, help='行锚框')
parser.add_argument('--num_lanes', type=int, default=2, help='车道数')
parser.add_argument('--sim_loss_w', type=int, default=0, help='loss')
parser.add_argument('--shp_loss_w', type=int, default=0, help='loss')
parser.add_argument('--resume', type=str, default=None, help='继续训练')
parser.add_argument('--auto_backup', action='store_true', help='automatically backup current code in the log path')
parser.add_argument('--distributed',type=bool, default=False, help='分布式训练')
opt = parser.parse_args()
return opt
def get_work_dir(opt):
now = datetime.datetime.now().strftime('%m%d_%H%M')
hyper_param_str = '_lr_%1.0e_b_%d' % (opt.learning_rate, opt.batch_size)
work_dir = os.path.join(opt.log_path, now+hyper_param_str)
return work_dir
3.2 数据加载文件的修改
修改如下源码文件: utils_alian/dataset_alian.py
自定义的训练数据集加载函数,代码如下:
"""
2022.4.20
author:alian
function:
Ultra-Fast-Lane-Detection:https://github.com/cfzd/Ultra-Fast-Lane-Detection
加载自定义数据集
"""
import torch
from PIL import Image
import pdb
import numpy as np
import glob
from data.mytransforms import find_start_pos
import torch.utils.data
def loader_func(path):
return Image.open(path)
class ClsDataset(torch.utils.data.Dataset):
def __init__(self, path, img_transform=None, target_transform=None, simu_transform=None, griding_num=50,
load_name=False,
row_anchor=None, use_aux=False, segment_transform=None, num_lanes=4):
super(ClsDataset, self).__init__()
self.img_transform = img_transform
self.target_transform = target_transform
self.segment_transform = segment_transform
self.simu_transform = simu_transform
self.path = path
self.griding_num = griding_num
self.load_name = load_name
self.use_aux = use_aux
self.num_lanes = num_lanes
self.row_anchor = row_anchor
self.row_anchor.sort()
def __getitem__(self, index):
labels = glob.glob('%s/label/*.png'%self.path)
label_path = labels[index]
label = loader_func(label_path)
imgs = glob.glob('%s/pic/*.jpg'%self.path)
img_path = imgs[index]
img = loader_func(img_path)
if self.simu_transform is not None:
img, label = self.simu_transform(img, label)
lane_pts = self._get_index(label)
w, h = img.size
cls_label = self._grid_pts(lane_pts, self.griding_num, w)
if self.img_transform is not None:
img = self.img_transform(img)
if self.use_aux:
assert self.segment_transform is not None
seg_label = self.segment_transform(label)
aa = seg_label[:,33]
return img, cls_label, seg_label
if self.load_name:
return img, cls_label
return img, cls_label
def __len__(self):
return len(glob.glob('%s/label/*.png'%self.path))
def _grid_pts(self, pts, num_cols, w):
"""
pts:包含车道线的坐标[车道线,56,2]
num_cols:网格列数
w:图片的列数(像素单位)
function:
将图片按指定的列数划分网格数,并获得车道线所在的网格位置
"""
num_lane, n, n2 = pts.shape
col_sample = np.linspace(0, w - 1, num_cols)
assert n2 == 2
to_pts = np.zeros((n, num_lane))
for i in range(num_lane):
pti = pts[i, :, 1]
to_pts[:, i] = np.asarray(
[int(pt // (col_sample[1] - col_sample[0])) if pt != -1 else num_cols for pt in pti])
return to_pts.astype(int)
def _get_index(self, label):
"""
label:1920*1080
"""
w, h = label.size
if h != 288:
scale_f = lambda x: int((x * 1.0 / 288) * h)
sample_tmp = list(map(scale_f, self.row_anchor))
all_idx = np.zeros((self.num_lanes, len(sample_tmp), 2))
for i, r in enumerate(sample_tmp):
label_r = np.asarray(label)[int(round(r))]
for lane_idx in range(1, self.num_lanes + 1):
pos = np.where(label_r == lane_idx)[0]
if len(pos) == 0:
all_idx[lane_idx - 1, i, 0] = r
all_idx[lane_idx - 1, i, 1] = -1
continue
pos = np.mean(pos)
all_idx[lane_idx - 1, i, 0] = r
all_idx[lane_idx - 1, i, 1] = pos
all_idx_cp = all_idx.copy()
for i in range(self.num_lanes):
if np.all(all_idx_cp[i, :, 1] == -1):
continue
valid = all_idx_cp[i, :, 1] != -1
valid_idx = all_idx_cp[i, valid, :]
if valid_idx[-1, 0] == all_idx_cp[0, -1, 0]:
continue
if len(valid_idx) < 6:
continue
valid_idx_half = valid_idx[len(valid_idx) // 2:, :]
p = np.polyfit(valid_idx_half[:, 0], valid_idx_half[:, 1], deg=1)
start_line = valid_idx_half[-1, 0]
pos = find_start_pos(all_idx_cp[i, :, 0], start_line) + 1
fitted = np.polyval(p, all_idx_cp[i, pos:, 0])
fitted = np.array([-1 if y < 0 or y > w - 1 else y for y in fitted])
assert np.all(all_idx_cp[i, pos:, 1] == -1)
all_idx_cp[i, pos:, 1] = fitted
if -1 in all_idx[:, :, 0]:
pdb.set_trace()
return all_idx_cp
创建脚本 utils_alian/dataloader_alian.py,代码如下:
"""
2022.4.20
author:alian
function:
自定义数据加载器
"""
import torch
import torchvision.transforms as transforms
import torch.utils.data
import data.mytransforms as mytransforms
from data.constant import tusimple_row_anchor
from utils_alian.dataset_alian import ClsDataset
def get_train_loader(batch_size, data_root, griding_num, use_aux, distributed, num_lanes):
target_transform = transforms.Compose([
mytransforms.FreeScaleMask((288, 800)),
mytransforms.MaskToTensor(),
])
segment_transform = transforms.Compose([
mytransforms.FreeScaleMask((36, 100)),
mytransforms.MaskToTensor(),
])
img_transform = transforms.Compose([
transforms.Resize((288, 800)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
simu_transform = mytransforms.Compose2([
mytransforms.RandomRotate(6),
mytransforms.RandomUDoffsetLABEL(100),
mytransforms.RandomLROffsetLABEL(200)
])
train_dataset = ClsDataset(data_root,
img_transform=img_transform, target_transform=target_transform,
simu_transform=simu_transform,
griding_num=griding_num,
row_anchor=tusimple_row_anchor,
segment_transform=segment_transform, use_aux=use_aux, num_lanes=num_lanes)
if distributed:
sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
sampler = torch.utils.data.RandomSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, sampler=sampler, num_workers=0)
return train_loader
class SeqDistributedSampler(torch.utils.data.distributed.DistributedSampler):
'''
Change the behavior of DistributedSampler to sequential distributed sampling.
The sequential sampling helps the stability of multi-thread testing, which needs multi-thread file io.
Without sequentially sampling, the file io on thread may interfere other threads.
'''
def __init__(self, dataset, num_replicas=None, rank=None, shuffle=False):
super().__init__(dataset, num_replicas, rank, shuffle)
def __iter__(self):
g = torch.Generator()
g.manual_seed(self.epoch)
if self.shuffle:
indices = torch.randperm(len(self.dataset), generator=g).tolist()
else:
indices = list(range(len(self.dataset)))
indices += indices[:(self.total_size - len(indices))]
assert len(indices) == self.total_size
num_per_rank = int(self.total_size // self.num_replicas)
indices = indices[num_per_rank * self.rank : num_per_rank * (self.rank + 1)]
assert len(indices) == self.num_samples
return iter(indices)
3.3 训练代码修改
创建脚本train_alian.py,该脚本文件直接放在项目文件夹下
"""
2022.4.20
author:alian
车道线训练代码
"""
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch, os, datetime,time
import torch.backends.cudnn
from model.model import parsingNet
from utils_alian.dataloader_alian import get_train_loader
from utils.dist_utils import dist_print, dist_tqdm
from utils.factory import get_metric_dict, get_loss_dict, get_optimizer, get_scheduler
from utils.metrics import update_metrics, reset_metrics
from utils.common import save_model, cp_projects
from utils.common import get_logger
from utils_alian.config import get_args,get_work_dir
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def inference(net, data_label, use_aux):
if use_aux:
img, cls_label, seg_label = data_label
img, cls_label, seg_label = img.cuda(), cls_label.long().cuda(), seg_label.long().cuda()
cls_out, seg_out = net(img)
return {'cls_out': cls_out, 'cls_label': cls_label, 'seg_out':seg_out, 'seg_label': seg_label}
else:
img, cls_label = data_label
img, cls_label = img.cuda(), cls_label.long().cuda()
cls_out = net(img)
return {'cls_out': cls_out, 'cls_label': cls_label}
def resolve_val_data(results, use_aux):
results['cls_out'] = torch.argmax(results['cls_out'], dim=1)
if use_aux:
results['seg_out'] = torch.argmax(results['seg_out'], dim=1)
return results
def calc_loss(loss_dict, results, logger, global_step):
loss = 0
for i in range(len(loss_dict['name'])):
data_src = loss_dict['data_src'][i]
datas = [results[src] for src in data_src]
loss_cur = loss_dict['op'][i](*datas)
if global_step % 20 == 0:
logger.add_scalar('loss/'+loss_dict['name'][i], loss_cur, global_step)
loss += loss_cur * loss_dict['weight'][i]
return loss
def train(net, data_loader, loss_dict, optimizer, scheduler,logger, epoch, metric_dict, use_aux):
net.train()
progress_bar = dist_tqdm(train_loader)
t_data_0 = time.time()
for b_idx, data_label in enumerate(progress_bar):
t_data_1 = time.time()
reset_metrics(metric_dict)
global_step = epoch * len(data_loader) + b_idx
t_net_0 = time.time()
results = inference(net, data_label, use_aux)
loss = calc_loss(loss_dict, results, logger, global_step)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step(global_step)
t_net_1 = time.time()
results = resolve_val_data(results, use_aux)
update_metrics(metric_dict, results)
if global_step % 20 == 0:
for me_name, me_op in zip(metric_dict['name'], metric_dict['op']):
logger.add_scalar('metric/' + me_name, me_op.get(), global_step=global_step)
logger.add_scalar('meta/lr', optimizer.param_groups[0]['lr'], global_step=global_step)
if hasattr(progress_bar,'set_postfix'):
kwargs = {me_name: '%.3f' % me_op.get() for me_name, me_op in zip(metric_dict['name'], metric_dict['op'])}
progress_bar.set_postfix(loss='%.3f' % float(loss),
data_time = '%.3f' % float(t_data_1 - t_data_0),
net_time = '%.3f' % float(t_net_1 - t_net_0),
**kwargs)
t_data_0 = time.time()
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True
opt = get_args()
work_dir = get_work_dir(opt)
distributed = False
if 'WORLD_SIZE' in os.environ:
distributed = int(os.environ['WORLD_SIZE']) > 1
if distributed:
import torch.distributed
torch.cuda.set_device(0)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
dist_print(datetime.datetime.now().strftime('[%Y/%m/%d %H:%M:%S]') + ' start training...')
dist_print(opt)
assert opt.backbone in ['18','34','50','101','152','50next','101next','50wide','101wide']
train_loader = get_train_loader(opt.batch_size, opt.source, opt.griding_num, opt.use_aux, distributed, opt.num_lanes)
net = parsingNet(pretrained = True, backbone=opt.backbone,cls_dim=(opt.griding_num+1,opt.row_anchor, opt.num_lanes),use_aux=opt.use_aux).cuda()
if distributed:
net = torch.nn.parallel.DistributedDataParallel(net, device_ids = [opt.local_rank])
optimizer = get_optimizer(net, opt)
if opt.resume is not None:
dist_print('==> Resume model from ' + opt.resume)
resume_dict = torch.load(opt.resume, map_location='cpu')
net.load_state_dict(resume_dict['model'])
if 'optimizer' in resume_dict.keys():
optimizer.load_state_dict(resume_dict['optimizer'])
resume_epoch = int(os.path.split(opt.resume)[1][2:5]) + 1
else:
resume_epoch = 0
scheduler = get_scheduler(optimizer, opt, len(train_loader))
dist_print(len(train_loader))
metric_dict = get_metric_dict(opt)
loss_dict = get_loss_dict(opt)
logger = get_logger(work_dir, opt)
cp_projects(opt.auto_backup, work_dir)
for epoch in range(resume_epoch, opt.epoch):
train(net, train_loader, loss_dict, optimizer, scheduler,logger, epoch, metric_dict, opt.use_aux)
save_model(net, optimizer, epoch, work_dir, distributed)
logger.close()
3.4 开始训练
1)在终端执行如下指令开始训练:
python train_alian.py --source /data3/205b/Alian/Ultra-Fast-Lane-Detection/subway --log_path /data3/205b/Alian/Ultra-Fast-Lane-Detection/model --epoch 100 --batch_size 32 --num_lanes 2
2)在pycharm中运行
在train_alian.py页面右键,选择设置参数,如下图所示
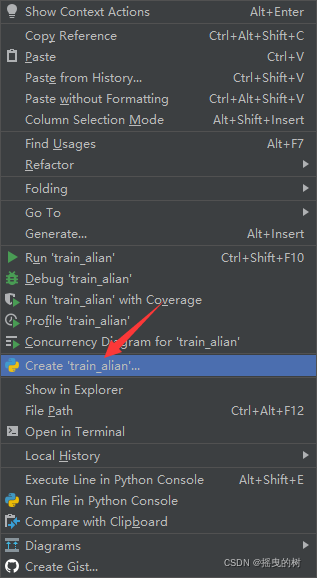
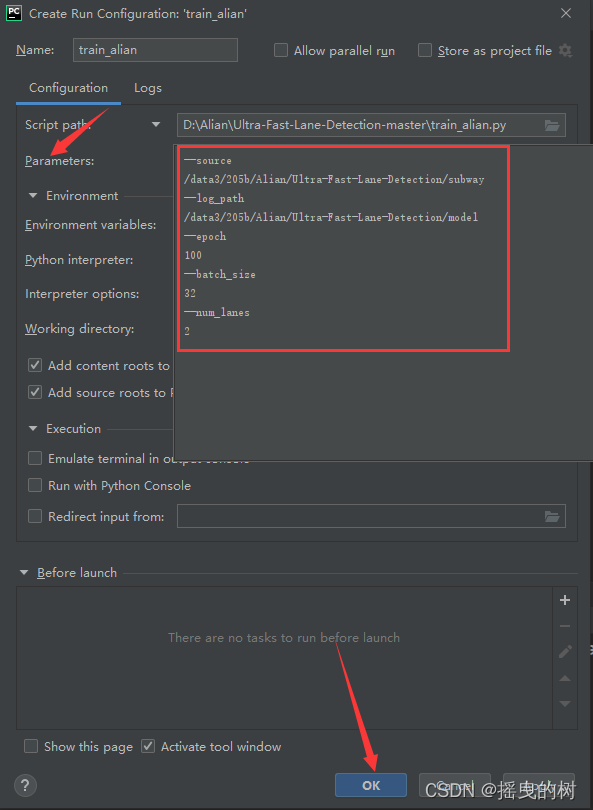
接着,再运行train_alian.py文件
终端显示如下,则说明训练正常:
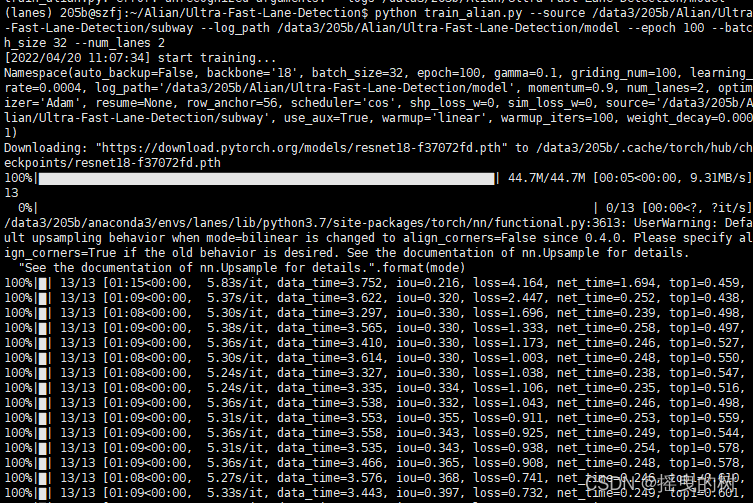
综上,就是Ultra-Fast-Lane-Detection自定义数据训练的全部过程
自训练完的模型测试部分,将在下一篇博客中详细说明。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)