上一篇:【PyTorch教程】05-如何使用PyTorch训练神经网络模型 (2022年最新)
1. 背景
在PyTorch中,可以使用 torch.nn 库来搭建神经网络。nn 库依赖于 autograd 定义模型并计算其梯度。一个 nn.Module 包含很多层,还包含一个前向传播方法 forward(input) 来返回输出 output 。
举个例子,下面这是一个用于识别数字图片的网络:
如上图所示,卷积神经网络首先获取输入图片,一层又一层地向前传播,最终得到输出结果。典型的神经网络的训练过程如下:
2. 神经网络中的输入输出关系
2.1 卷积层输入输出关系
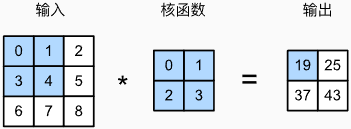
- 输入
X
X
X :
n
h
×
n
w
n_h\times n_w
nh×nw
- 卷积核 (Kernel)
W
W
W:
k
h
×
k
w
k_h\times k_w
kh×kw
- 偏差 bias:
b
∈
R
b\in \Bbb{R}
b∈R
- 输出
Y
Y
Y :
(
n
h
−
k
h
+
1
)
×
(
n
w
−
k
w
+
1
)
(n_h-k_h+1)\times (n_w-k_w+1)
(nh−kh+1)×(nw−kw+1)
Y
=
X
⋅
W
+
b
Y=X\cdot W+b
Y=X⋅W+b
其中,
W
W
W 和
b
b
b 是可学习的参数。
2.2 填充输入输出关系
在卷积神经网络中,常常用填充 padding 操作。
-
填充
p
h
p_h
ph 行和
p
w
p_w
pw 列。通常取卷积核大小减一的填充数,即
{
p
h
=
k
h
−
1
p
w
=
k
w
−
1
\begin{cases} p_h=k_h-1 \\ p_w=k_w-1 \end{cases}
{ph=kh−1pw=kw−1
-
输出:
(
n
h
−
k
h
+
2
p
h
+
1
)
×
(
n
w
−
k
w
+
2
p
w
+
1
)
(n_h-k_h+2p_h+1)\times (n_w - k_w+2p_w+1)
(nh−kh+2ph+1)×(nw−kw+2pw+1)
2.3 步幅输入输出关系
在卷积神经网络中,常常用步幅 stride 操作。
- 给定高度步幅
s
h
s_h
sh 和 宽度步幅
s
w
s_w
sw 。
- 输出形状除以步幅
s
s
s:
[
(
n
h
−
k
h
+
2
p
h
+
1
)
/
s
h
]
×
[
(
n
w
−
k
w
+
2
p
w
+
1
)
/
s
w
]
[(n_h-k_h+2p_h+1)/s_h] \times [(n_w - k_w+2p_w+1)/s_w]
[(nh−kh+2ph+1)/sh]×[(nw−kw+2pw+1)/sw]
2.4 池化层输入输出关系
- 池化层的输入输出关系与卷积层相同,把卷积核的形状换成池化窗口形状即可。
- 池化层没有可学习的参数。
3. 搭建网络
下面使用PyTorch来搭建一个下图所示的卷积神经网络:
上图的神经网络由2个卷积层 (Convolutions) 和3个全连接层 (Full Conection) 组成,大家也可以利用上上一节的知识来验证各层之间的输入输出关系。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module): # 括号里表示Net类继承自nn.Module这个类
"""
自定义神经网络类Net
"""
def __init__(self): # Net类的构造器
super(Net, self).__init__() # 让子类Net拥有父类nn.Module的所有属性
# 声明属性
# 卷积层
self.conv1 = nn.Conv2d(1, 6, 5) # 第1层卷积网络:输入通道为1,输出通道为6,卷积核形状为5×5
self.conv2 = nn.Conv2d(6, 16, 5) # 第2层卷积网络:输入通道为6,输出通道为16,卷积核形状为5×5
# 全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 第1个参数是输入神经元个数,第2个是输出神经元个数
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 前向传播的方法
# 2×2最大池化层
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果形状为方形(如2×2),可以简写为一个数字,如下所示
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # 把x沿着水平方向展开
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x # 返回前向传播的预测结果
if __name__ == '__main__':
# 创建Net类的对象
net = Net()
print(net)
输出:
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
在PyTorch中,您只需要定义前向传播函数 forward , autograd 将会自动创建反向传播函数 backward (进行梯度计算的函数) 。
模型的可学习参数将由 net.parameters() 函数返回,如下代码所示:
params = list(net.parameters()) # 用列表作为容器
print(f"The Length of params: {len(params)}")
print(f"The size of params: {params[0].size()}") # 第1层卷积层的参数
输出:
The Length of params: 10
The size of params: torch.Size([6, 1, 5, 5])
3.1 测试
尝试往这个神经网络中输入一个随机的
32
×
32
32\times 32
32×32 像素大小的随机张量 (当作是伪造的输入图片) 。例如,这个例子的网络模型是用在 MNIST 数据集上的,所以要把输入图片的尺寸调整为
32
×
32
32\times 32
32×32 像素的大小。
【注意】
-
torch.nn 库只支持批量处理的输入数据 (mini-batches) ,不支持输入一张图片样本。
- 输入图片的尺寸形状要满足神经网络的要求,不同的神经网络模型对输入图片的尺寸各不相同,大家要具体情况具体分析。
- 例如,本文例子中的网络要求输入一个四维张量,如下所示:
data = torch.rand(1, 1, 32, 32) # 伪造输入图片张量
output = net(data) # 输入到神经网络中
print(output)
第1行代码:创建了一个模型要求的四维张量,每个维度的含义如下:
- 第1个维度:批大小 (batch size) ,指一次性处理多少张输入图片。
- 第2个维度:每张输入图片的通道数 (channels) ,彩色图片是三通道的,黑白的灰度图片是一通道的。
- 第3个维度:每张输入图片的高 (height) 尺寸,单位为像素。
- 第4个维度:每张输入图片的宽 (width) 尺寸,单位为像素。
输出:
tensor([[-0.0239, 0.0601, 0.1028, 0.0760, 0.0725, 0.0214, -0.0135, -0.0073,
0.0652, -0.1062]], grad_fn=<AddmmBackward0>)
输出有10个值,分别对应 MNIST 数据集的10个类别 (手写数字0~9) 。这就是网络前向传播的输出预测值,每个值是识别为对应标签的概率。
将所有参数的梯度缓存数据清零,并使用随机生成的梯度进行反向传播:
net.zero_grad() # 清空梯度缓存区的梯度数据
output.backward(torch.randn(1, 10)) # 将随机生成的梯度反向传播
3.2 总结
总结至今所学的所有类:
| 模块 |
作用 |
torch.Tensor |
多维张量模块。支持诸如 backward() 的自动求导运算。 |
nn.Module |
神经网络模块。封装了诸如卷积层、池化层、全连接层等的网络层,同时封装了将这些网络层移到GPU、导出和加载的函数。 |
nn.Paramter |
网络参数模块。也是张量,当被声明为模块的属性时,其会自动加载为参数。 |
autograd.Function |
自动求导函数模块。实现前向传播和反向传播的自动求导。每个张量运算都至少产生一个 Function 节点,该节点连接到创建张量的函数,并编码其历史记录。 |
4. 损失函数
将输入数据的预测结果 output 和真实标签 labels 输入到损失函数 loss 中,就会计算出一个值,这个值表征模型正向传播的预测结果 output 到底离真实的标签 labels 差得有多远。
在 torch.nn 库中封装了几种不同的损失函数。最简单的一个是 nn.MSELoss ,它计算预测结果 output 和真实标签 labels 之间的均方误差。
举个例子:
import torch
import torch.nn as nn
net = Net() # 创建Net类的对象
input = torch.randn(1, 1, 32, 32) # 虚拟的输入图片
labels = torch.randn(10) # 虚拟的标签
labels = labels.view(1, -1) # 让标签张量的维度与output的维度保持一致
output = net(input) # 前向传播的预测结果
# 计算损失函数
criterion = nn.MSELoss() # 创建一个均方误差损失函数的对象
loss = criterion(output, labels)
print(loss)
输出:
tensor(0.8566, grad_fn=<MseLossBackward0>)
下面展示了从输入到损失函数的流程图:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> flatten -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
因此,当我们调用 loss.backward() 时,上面的整个图上的参数都将自动求导,并且流程图中所有 requires_grad=True 的张量都将随梯度累积其 .grad 张量。
举个栗子:
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # 全连接层
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU层
输出:
<MseLossBackward0 object at 0x0000022466E6C250>
<AddmmBackward0 object at 0x0000022466E6C2E0>
<AccumulateGrad object at 0x0000022466E6C2E0>
5. 反向传播
PyTorch通过 loss.backward() 方法来反向传播损失函数。但是,你需要清除现有的梯度,否则新的梯度会累积到现有的梯度中。
现在调用 loss.backward() 方法,来比较一下第1层卷积层 conv1 在反向传播前和反向传播后的梯度误差。
net.zero_grad() # 将所有参数的梯度缓存区清零
print(f"conv1.bias.grad before backward: \n{net.conv1.bias.grad}")
loss.backward() # 反向传播
print(f"conv1.bias.grad after backward: \n{net.conv1.bias.grad}")
输出:
conv1.bias.grad before backward:
None
conv1.bias.grad after backward:
tensor([-0.0092, 0.0072, -0.0153, -0.0046, -0.0140, 0.0109])
6. 权重更新
在实际项目中使用的最简单的权重更新方法是随机梯度下降法 (Stochastic Gradient Descent, SGD) 。其公式如下:
weight = weight - learning_rate * gradient
如果没有PyTorch框架,我们只能使用如下代码暴力实现:
learning_rate = 0.01 # 声明学习率
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
但是,在实际开发中,我们往往还需要其他的权重更新方法,例如 Nesterov-SGD, Adam, RMSProp 等。为了满足这个需求,PyTorch建立了一个优化器的库 `torch.optim` ,这个库封装了所有的权重优化的方法。使用起来将变得非常简单方便。
举个栗子:
import torch.optim as optim
# 权重更新
optimizer = optim.SGD(net.parameters(), lr=0.01) # 创建SGD优化器的对象
# 在你的训练循环中
optimizer.zero_grad() # 将所有参数的梯度缓存区清零,防止梯度累积
output = net(input)
loss = criterion(output, labels)
loss.backward()
optimizer.step() # 进行权重更新
【注意】
记得必须通过 optimizer.zero_grad() 手动将梯度缓存清零,防止梯度累积。