Multimodal Token Fusion for Vision Transformers
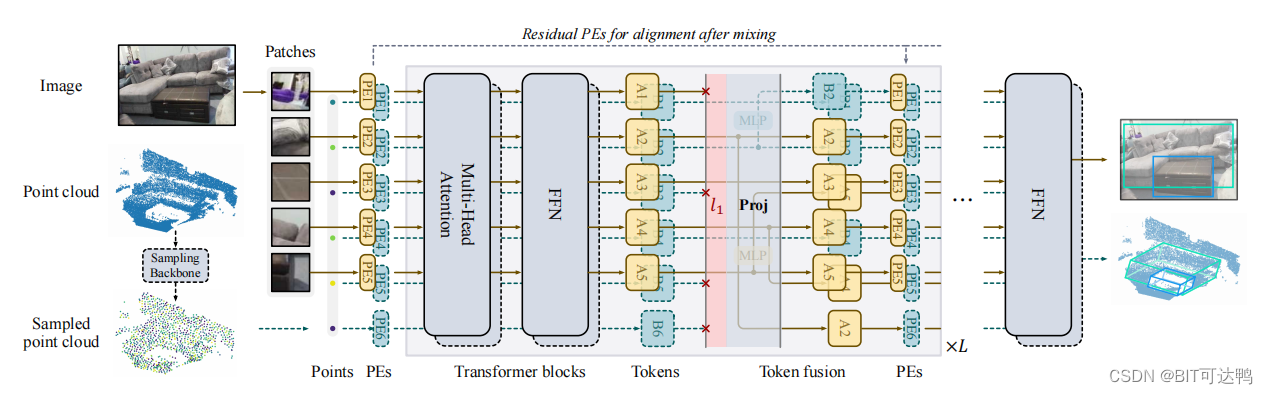
论文简介:
许多方法已经应用到了 Transformer 以解决单模态视觉任务,其中自注意模块被堆叠来处理图像等输入源。直观地说,向 Transformer 输入多种模式的数据可以提高性能,但注意力权重可能会被稀释,从而极大地削弱最终的性能。
在本文中,作者提出了一种多模态 Token 融合方法(Token Fusion),针对基于 Transformer 的视觉任务。为了有效地融合多种模式,Token Fusion 动态检测无信息的 token&