绪论
这一章节介绍的是divide-and-conquer multiplication,divide的意思是分开,conquer的意思是占据,控制,divide-and-conquer直译下来就是分开后控制,其实就是分而治之的意思,multiplication的意思是乘法。divide-and-conquer multiplication算法的主要核心思想就是分治,通过分治来简化各种较为复杂的乘法运算。
后面还介绍了有关FFT的知识点,因为我也是问了别人才弄懂的,不做过多赘述。
Integer Multiplication
首先讨论实数与实数(整型与整型,浮点型与浮点型)之间的运算:
之前提到过基础的运算加减乘除,左移右移等的复杂度都视作O(1),这个O(1)不是说只做一次操作,而是相对于字节长度固定的整型(浮点型)而言,因为字节长度也就是位数固定,和位数相关的运算的复杂度也看做常数级。
例如加减运算和左移右移运算,如果限定的位数为n,需要依次对每一位进行运算和记录进位,所以复杂度为O(n)
int整型的位数为32,也就是说一次加法运算做的操作次数约为32个常数单位。

如果是两个二进制数的乘法,需要其中的一个二进制数对另一个二进制数的每一位逐步进行运算,然后将运算的结果进行错位的相加。每一位(乘法)运算的复杂度为O(n),n位的运算的复杂度就为O(n2),错位相加总共需要相加的位数为n*n=n2,根据前面的结论也可以得到复杂度为O(n2),总结n位二进制数相乘的复杂度为O(n2)。
int整型的位数为32,也就是说一次乘法运算做的操作次数约为32*32=1024个常数单位。同样都为基础运算,相较于加减法和左右移位,乘法的复杂度就要高很多。这就是为什么在前面提到的哈希技术中,需要尽可能地将乘法和模运算用左移右移运算来代替。
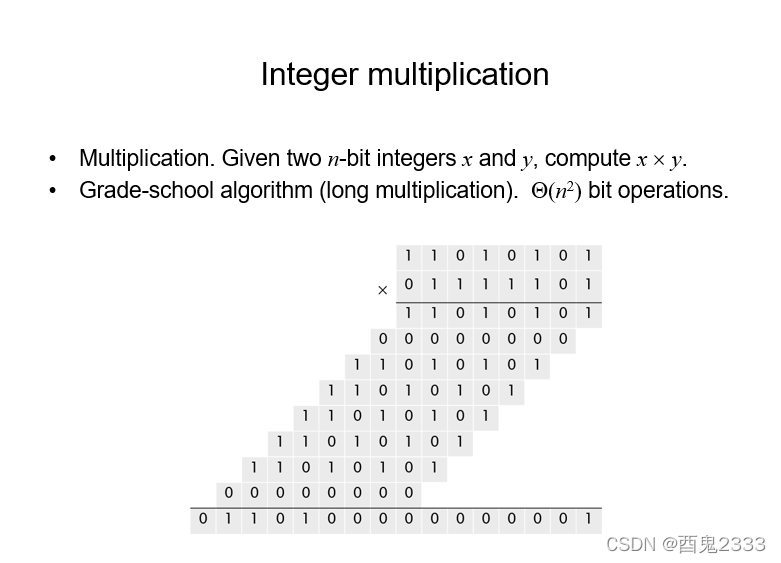
上面是一般的二进制乘法,分治思想是考虑将大的问题分割成若干个子问题解决,用分治法来优化二进制乘法就是将n位的二进制数相乘看作一个规模为n的问题,将一个二进制数分割成前半的部分和后半的部分,前半和后半的部分分别进行计算,规模为n的问题不断地切割成若干个规模为n/2的问题。

伪代码和对应部分的时间复杂度如下:

子问题复杂度之间的递归关系可以通过代码得到。

这种表达式对应着分治递归问题的递归树,其中子问题为它所在的大问题的子节点,有一般的情况如下。

a是需要解决的子问题的种类数,b是分割下来的子问题规模与原问题规模的比例,a和b的值有可能存在一定的关系,也有可能没有,因为分割出来的子问题可能是一样的,不需要重复计算(也有可能子问题都不相同)。
f(n)是分割和合并子问题时操作需要的时间复杂度。

对于一般的递归分治算法子问题复杂度之间的递归关系式,可以推出规模为n的问题的时间复杂度。

这样可以推出用分治尝试优化的实数乘法的时间复杂度仍为O(n2),没有能够做到真正意义上时间上的优化。
更好的做法是通过数学的转化将子问题的种类数减少,像下面这种就是减少到了ac,bd,(a-b)(c-d)3种。

伪代码和对应部分的时间复杂度如下:

这样的时间复杂度可以从n2优化到n1.585。

Matrix Multiplication
分治乘法主要运用在矩阵与矩阵之间的乘法,普通无优化的矩阵乘法的复杂度为O(n3)。

用分治法优化矩阵乘法就是将当前n*n规模的矩阵分割成4个规模为(n/2)*(n/2)的子矩阵分别进行运算。这个方法在线代里面叫做分块矩阵,除了可以按照2*2进行分割,也可以按照1*4的方式进行分割。
像下面这样用最简单的方式直接分割,时间复杂度也是不会有多少变化的(线代里面对分块矩阵就是这么使用的,当时老师和慕课认为分块矩阵可以在矩阵存在局部0的情况时加快乘法的效率)。

更好的情况是像下面一样减少到七种不同的子问题。

代码和对应部分的时间复杂度如下:

这样时间复杂度可以优化到O(n2.8)左右,如果边长不能满足一直切割下去的条件就对周围的元素位置进行“补0”。

这个算法被称为Strassen’s algorithm(斯塔拉森矩阵乘法),当数据很大时,时间复杂度可以降低非常多(n≥2048时,优化过的矩阵乘法的耗时为优化之前的矩阵乘法耗时的1/8)。
矩阵乘法的时间复杂度仍然在不断地向下优化中·······

Convolution and FFT
Convolution and FFT这部分介绍了一个更为具体和完整的例子。这个例子我问了一下物联学过相关知识的大佬和给我课件的那位旁友然后反复研究了几遍的课件得到的结论就是:
FFT这个算法是用在信号处理,多项式相乘和卷积(convolution)等一系列需要快速将若干个值x1,x2······xn通过多项式转化成y1,y2·······yn的情况。然后我们这章主要介绍的是分治是FFT算法的主要核心算法思想,但是FFT算法你光用分治和上面一样处理是行不通的,或者说只能将原本n3的复杂度优化到n的2.3左右,FFT算法还需要另外的高数方面的知识点(高数82飘过)。
这里只介绍多项式的乘法。
Polynomials multiplication
对于多项式,有相加,相乘和对于某个x值求多项式值的几种操作,对于某个x值求多项式值的方法在前面介绍过,这个方法被称为Horner方法。
你像这样单纯的相乘复杂度就是O(n2)。

然后我们知道,对于一个n次的多项式,代入n个值可以得到n个结果。如果将系数看作未知数,那么这n个结果和代入的n个值可以像多元方程求解一样将n个系数反过来求出。
于是可以用n个代入的值和多项式值组成的数对来表示n次的多项式。

这种表达方法称为point-value表达法,比起系数的表达法,在乘法方面的效率要高很多。

考虑的做法是先将系数表达法转化成point-value表达法,再用point-value表达法进行乘法的运算,将运算后的结果转化回系数表达法。

因为有FFT算法能够快速地完成两种表达法的转化,所以采用这种两次转化的做法。
如果采用暴力将系数表达法转化成point-value表达法,第一种做法就是使用n次Horner方法,复杂度为n2,两次转化的复杂度不会优于系数表达法直接相乘的复杂度,并且Horner方法只能从系数表达法转化到point-value表达法,不能转化回来(大概)。
第二种方法是如果x幂次的值已知,考虑用线代矩阵相乘的方法来做,但这么做即使按照前面对矩阵的乘法进行优化,复杂度仍然会达到O(n2.38)。

FFT
FFT算法的核心思想也是分治,分割的方式是按照项次数的奇偶分割出两个最大次数为原多项式一半的多项式。
FFT算法另外最为重要的一个基础定理是欧拉恒等式,代入的n个值分别为欧拉恒等式的n个解,欧拉恒等式解与解之间的的性质,保证了子问题能够逐渐合并到最终的结果且不会出现无用的多项式值(具体为什么将divide和combine那里代入计算一下就明白了)。

伪代码和各个部分的复杂度如下。

上面的流程将前后相关的数据连线,不同的操作用不同的颜色表示,可以得到(比较)著名的FFT Butterfly(就学过的朋友所说,按照这个图形记忆反而记不住hhh)。

总结
这一章是数据结构课本上完全没有的东西,感觉学到了很多没有学过的东西,另外就是四门数学(高数,线代,离散,概率论)真的非常非常重要,不然就会像我一样在FFT算法卡上非常久的时间。